From Simple to Complex Skills: The Case of In-Hand Object Reorientation
作者: Haozhi Qi, Brent Yi, Mike Lambeta, Yi Ma, Roberto Calandra, Jitendra Malik
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-01-09
备注: website: https://dexhier.github.io
💡 一句话要点
提出基于分层策略的灵巧手物体重定向系统,提升模拟到真实的迁移能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 灵巧操作 物体重定向 分层策略 模拟到真实 强化学习
📋 核心要点
- 灵巧操作中,模拟到真实的迁移面临奖励函数设计、超参数调整和系统辨识等挑战,需要大量人工干预。
- 论文提出一种分层策略,利用预先学习的低级旋转技能,实现更复杂的在手物体重定向任务。
- 实验表明,该分层策略比从头学习更鲁棒,更容易迁移,并能有效重定向对称和无纹理物体。
📝 摘要(中文)
本文提出了一种利用低级技能解决灵巧操作中模拟到真实迁移挑战的系统。该系统采用分层策略,用于在手物体重定向任务中,基于先前学习的旋转技能选择执行哪个低级技能。与从头开始学习相比,该分层策略对分布外变化更具鲁棒性,并且更容易从模拟环境迁移到真实环境。此外,本文还提出了一种通用的物体姿态估计器,该估计器使用本体感受信息、低级技能预测和控制误差作为输入来估计物体随时间的姿态。实验结果表明,该系统可以将物体(包括对称和无纹理的物体)重定向到期望的姿态。
🔬 方法详解
问题定义:现有方法在灵巧操作任务中,特别是从模拟环境迁移到真实环境时,需要针对每个新任务进行大量的精细调整,包括奖励函数的设计、超参数的优化以及系统模型的辨识。这些手动调整过程耗时且缺乏通用性,难以适应新的物体和环境。
核心思路:本文的核心思路是利用预先学习的、模块化的低级技能,构建一个分层策略。该策略通过选择合适的低级技能来完成更复杂的任务,从而避免了从头开始学习的复杂性和对环境变化的敏感性。这种分层结构使得策略更易于泛化和迁移。
技术框架:该系统包含两个主要组成部分:低级技能库和分层策略。低级技能库包含一系列预先训练好的旋转技能。分层策略则负责根据当前环境状态和低级技能的反馈,选择执行哪个低级技能。此外,系统还包含一个物体姿态估计器,用于估计物体在手上的姿态。整个流程如下:首先,姿态估计器估计物体姿态;然后,分层策略根据姿态选择合适的低级技能;最后,执行选定的低级技能,并更新物体姿态。
关键创新:该论文的关键创新在于将分层策略与预训练的低级技能相结合,用于解决灵巧操作中的模拟到真实迁移问题。与传统的端到端学习方法相比,该方法更具模块化和可解释性,并且更容易适应新的任务和环境。此外,提出的物体姿态估计器利用了本体感受信息、低级技能预测和控制误差,提高了姿态估计的准确性和鲁棒性。
关键设计:分层策略使用强化学习进行训练,奖励函数的设计鼓励策略选择能够有效减小目标姿态与当前姿态之间差异的低级技能。物体姿态估计器是一个神经网络,输入包括机械手的关节角度、低级技能的预测以及控制误差。损失函数包括姿态估计误差和控制误差的正则化项。
🖼️ 关键图片


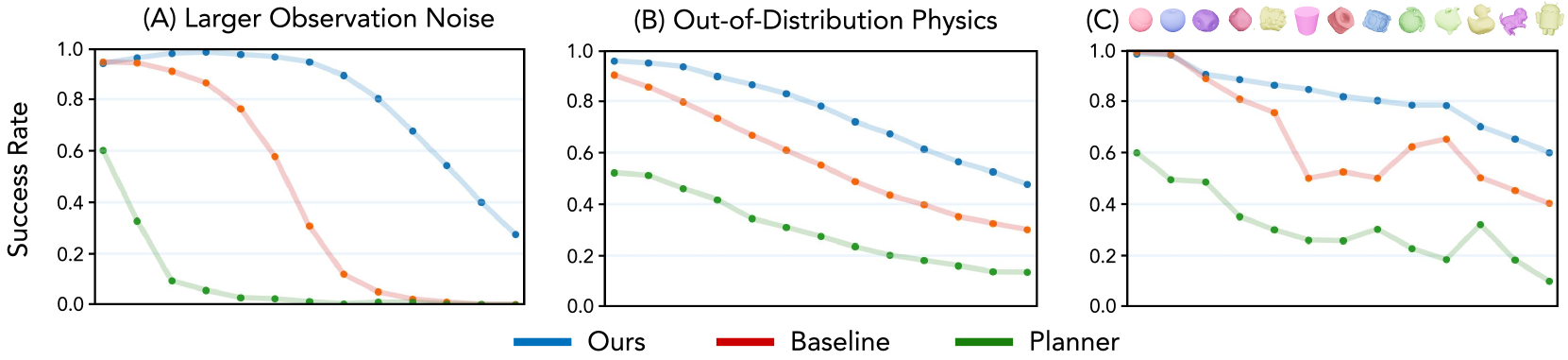
📊 实验亮点
实验结果表明,该系统能够成功地将物体重定向到期望的姿态,即使是对于对称和无纹理的物体。与从头开始学习的策略相比,该分层策略在模拟到真实环境的迁移中表现出更好的鲁棒性。具体性能数据未知,但论文强调了其在分布外变化下的优越性。
🎯 应用场景
该研究成果可应用于自动化装配、医疗手术机器人、家庭服务机器人等领域。通过预先学习的技能模块,机器人可以更灵活、更鲁棒地完成复杂的物体操作任务,降低开发成本,提高工作效率。未来,该方法有望扩展到更多类型的灵巧操作任务,例如抓取、放置和组装等。
📄 摘要(原文)
Learning policies in simulation and transferring them to the real world has become a promising approach in dexterous manipulation. However, bridging the sim-to-real gap for each new task requires substantial human effort, such as careful reward engineering, hyperparameter tuning, and system identification. In this work, we present a system that leverages low-level skills to address these challenges for more complex tasks. Specifically, we introduce a hierarchical policy for in-hand object reorientation based on previously acquired rotation skills. This hierarchical policy learns to select which low-level skill to execute based on feedback from both the environment and the low-level skill policies themselves. Compared to learning from scratch, the hierarchical policy is more robust to out-of-distribution changes and transfers easily from simulation to real-world environments. Additionally, we propose a generalizable object pose estimator that uses proprioceptive information, low-level skill predictions, and control errors as inputs to estimate the object pose over time. We demonstrate that our system can reorient objects, including symmetrical and textureless ones, to a desired pose.