UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation
作者: Oleg Sautenkov, Yasheerah Yaqoot, Artem Lykov, Muhammad Ahsan Mustafa, Grik Tadevosyan, Aibek Akhmetkazy, Miguel Altamirano Cabrera, Mikhail Martynov, Sausar Karaf, Dzmitry Tsetserukou
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-01-09 (更新: 2025-05-13)
备注: HRI 2025
💡 一句话要点
提出UAV-VLA系统,利用视觉语言模型和GPT实现大规模无人机任务生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机 视觉语言模型 GPT 任务生成 卫星图像
📋 核心要点
- 现有无人机任务生成方法依赖人工干预或复杂编程,缺乏灵活性和易用性。
- UAV-VLA系统结合卫星图像、视觉语言模型和GPT,通过文本指令生成无人机飞行路径和动作计划。
- 实验表明,该方法在轨迹长度和目标定位精度方面优于传统K近邻方法。
📝 摘要(中文)
UAV-VLA(视觉-语言-动作)系统是一种旨在促进与空中机器人通信的工具。通过将卫星图像处理与视觉语言模型(VLM)以及GPT的强大功能相结合,UAV-VLA使用户能够通过简单的文本请求生成通用的飞行路径和动作计划。该系统利用卫星图像提供的丰富的上下文信息,从而增强决策制定和任务规划。VLM的视觉分析和GPT的自然语言处理相结合,可以为用户提供路径和动作集,从而提高空中作业的效率和可访问性。新开发的方法在创建的轨迹长度上显示出22%的差异,并且在使用K近邻(KNN)方法时,在地图上找到感兴趣物体的平均误差为34.22米(欧几里得距离)。
🔬 方法详解
问题定义:论文旨在解决大规模无人机任务生成中人工干预过多、效率低下的问题。现有方法通常需要专业人员进行复杂编程或手动设置,难以适应快速变化的任务需求和环境。因此,如何通过更自然、更便捷的方式生成无人机任务计划是本研究的核心问题。
核心思路:论文的核心思路是利用视觉语言模型(VLM)理解卫星图像中的场景信息,并结合GPT的自然语言处理能力,将用户的文本指令转化为无人机可执行的飞行路径和动作计划。这种方法将复杂的任务生成过程简化为简单的文本交互,降低了使用门槛,提高了任务生成的效率和灵活性。
技术框架:UAV-VLA系统的整体架构包含以下几个主要模块:1) 卫星图像获取与预处理模块,负责获取目标区域的卫星图像,并进行必要的图像增强和校正;2) 视觉语言模型(VLM)模块,用于分析卫星图像,提取场景中的关键信息,如建筑物、道路、植被等;3) 自然语言处理(NLP)模块,利用GPT模型理解用户的文本指令,提取任务目标和约束条件;4) 路径规划与动作生成模块,根据VLM提取的场景信息和NLP模块解析的任务目标,生成无人机的飞行路径和动作计划;5) 任务执行与监控模块,负责将生成的任务计划发送给无人机执行,并实时监控无人机的状态和任务进度。
关键创新:该论文最重要的技术创新点在于将视觉语言模型和GPT模型相结合,实现了一种基于文本指令的无人机任务自动生成方法。与传统方法相比,该方法无需人工编程或手动设置,用户只需通过简单的文本指令即可生成复杂的无人机任务计划。此外,该方法还能够利用卫星图像提供的丰富的上下文信息,从而提高任务生成的准确性和可靠性。
关键设计:论文中没有详细描述关键参数设置、损失函数或网络结构等技术细节。但是,可以推断,VLM可能采用了预训练的视觉Transformer模型,并针对卫星图像进行了微调。GPT模型可能采用了大规模的语言模型,并针对无人机任务生成进行了指令微调。路径规划算法可能采用了A*算法或RRT算法,并结合了VLM提取的场景信息进行优化。
🖼️ 关键图片


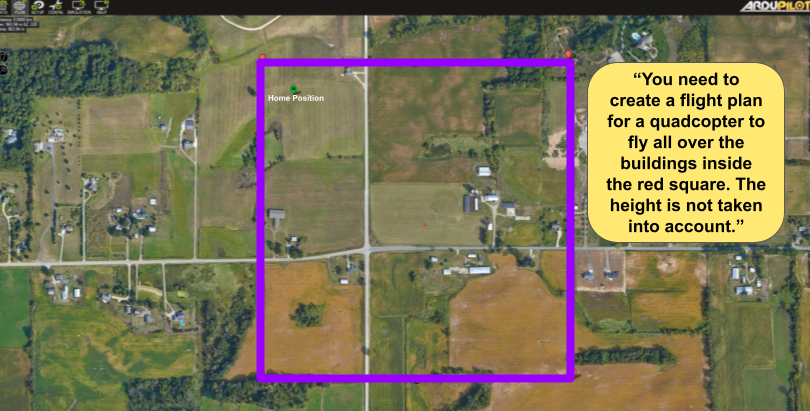
📊 实验亮点
实验结果表明,UAV-VLA系统在轨迹长度和目标定位精度方面优于传统的K近邻(KNN)方法。具体来说,UAV-VLA生成的轨迹长度比KNN方法短22%,并且在地图上找到感兴趣物体的平均误差为34.22米(欧几里得距离)。这些结果表明,UAV-VLA系统能够更有效地生成无人机任务计划,并提高任务执行的准确性。
🎯 应用场景
UAV-VLA系统可广泛应用于灾害救援、环境监测、农业巡检、城市规划等领域。该系统能够根据用户的文本指令,快速生成无人机任务计划,从而提高应急响应速度和工作效率。例如,在灾害救援中,用户可以通过简单的文本指令,指示无人机搜索受困人员或评估灾情。在农业巡检中,用户可以指示无人机监测农作物生长情况或病虫害情况。该系统具有巨大的应用潜力,有望推动无人机技术在各行各业的广泛应用。
📄 摘要(原文)
The UAV-VLA (Visual-Language-Action) system is a tool designed to facilitate communication with aerial robots. By integrating satellite imagery processing with the Visual Language Model (VLM) and the powerful capabilities of GPT, UAV-VLA enables users to generate general flight paths-and-action plans through simple text requests. This system leverages the rich contextual information provided by satellite images, allowing for enhanced decision-making and mission planning. The combination of visual analysis by VLM and natural language processing by GPT can provide the user with the path-and-action set, making aerial operations more efficient and accessible. The newly developed method showed the difference in the length of the created trajectory in 22% and the mean error in finding the objects of interest on a map in 34.22 m by Euclidean distance in the K-Nearest Neighbors (KNN) approach.