CuRLA: Curriculum Learning Based Deep Reinforcement Learning for Autonomous Driving
作者: Bhargava Uppuluri, Anjel Patel, Neil Mehta, Sridhar Kamath, Pratyush Chakraborty
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-01-09
备注: To be published in the 17th International Conference on Agents and Artificial Intelligence (ICAART), Feb 2025
💡 一句话要点
提出基于课程学习的深度强化学习方法CuRLA,用于提升自动驾驶在复杂环境中的适应性和安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 深度强化学习 课程学习 近端策略优化 变分自编码器
📋 核心要点
- 传统计算机视觉方法在自动驾驶中泛化性差,深度强化学习方法虽能适应动态环境,但仍面临泛化性和安全性的挑战。
- 论文提出CuRLA,结合深度强化学习与课程学习,通过逐步增加环境难度和引入碰撞惩罚,提升智能体的适应性和安全性。
- 该方法在CARLA模拟器中进行了验证,结果表明CuRLA能够有效提升自动驾驶智能体在复杂环境中的性能。
📝 摘要(中文)
在自动驾驶领域,传统的计算机视觉(CV)智能体由于训练数据中的偏差,常常在不熟悉的环境中表现不佳。深度强化学习(DRL)智能体通过从经验中学习并最大化奖励来解决这个问题,从而适应动态环境。然而,保证其泛化能力仍然具有挑战性,尤其是在静态训练环境中。此外,DRL模型缺乏透明度,难以保证在所有场景下的安全性,尤其是在训练期间未见过的场景。为了解决这些问题,我们提出了一种将DRL与课程学习相结合的自动驾驶方法。我们的方法使用近端策略优化(PPO)智能体和一个变分自编码器(VAE)来学习在CARLA模拟器中的安全驾驶。该智能体通过双重课程学习进行训练,逐步增加环境难度,并在奖励函数中加入碰撞惩罚以提高安全性。该方法提高了智能体在复杂环境中的适应性和可靠性,并理解了在单个标量奖励函数中平衡来自不同反馈信号的多个奖励分量的细微之处。
🔬 方法详解
问题定义:现有自动驾驶系统依赖的计算机视觉方法,在面对训练数据未覆盖的复杂或未知环境时,泛化能力不足。深度强化学习虽然可以通过与环境交互学习,但训练过程不稳定,且难以保证安全性,尤其是在训练初期可能出现危险行为。此外,如何设计有效的奖励函数,平衡不同目标(如速度、安全性、舒适性)也是一个挑战。
核心思路:论文的核心思路是利用课程学习的思想,逐步增加训练环境的难度,使智能体能够循序渐进地学习驾驶技能。同时,在奖励函数中引入碰撞惩罚,引导智能体学习安全驾驶行为。通过这种方式,提高智能体的泛化能力和安全性。
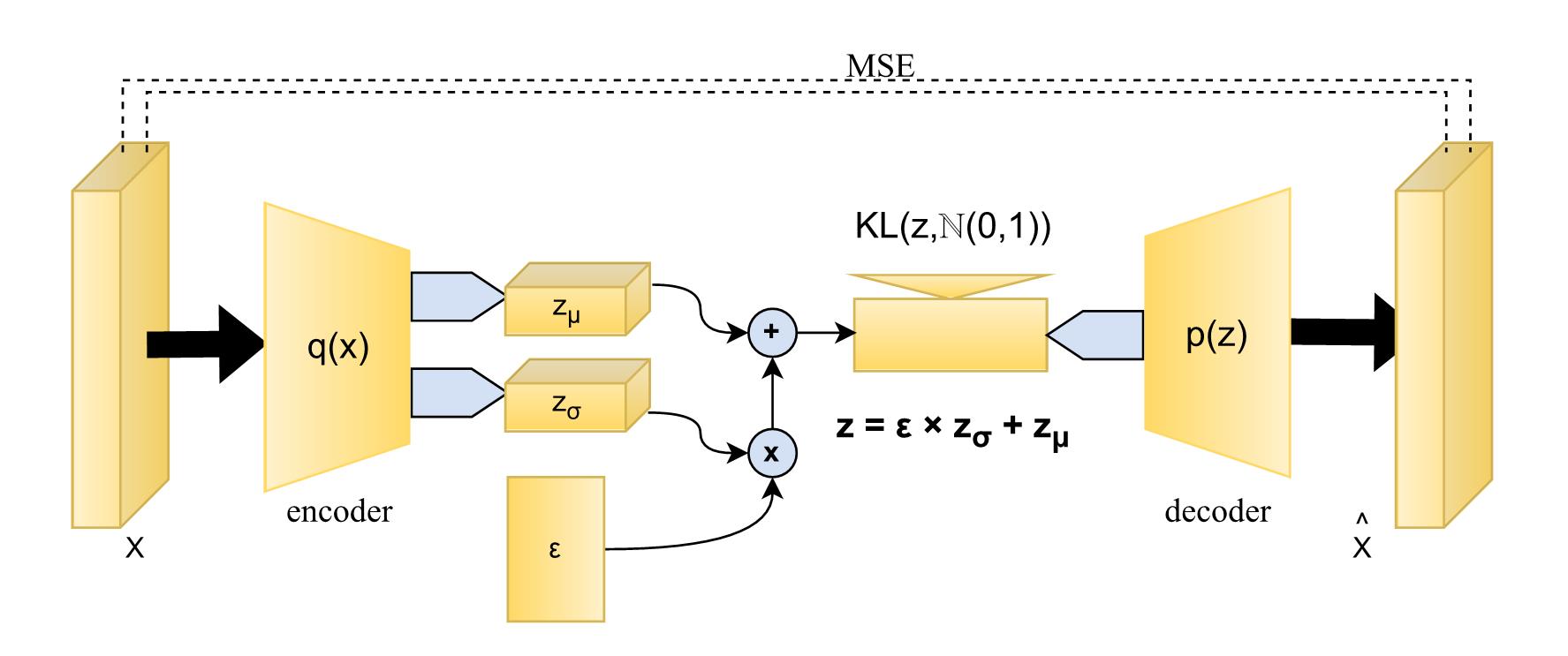
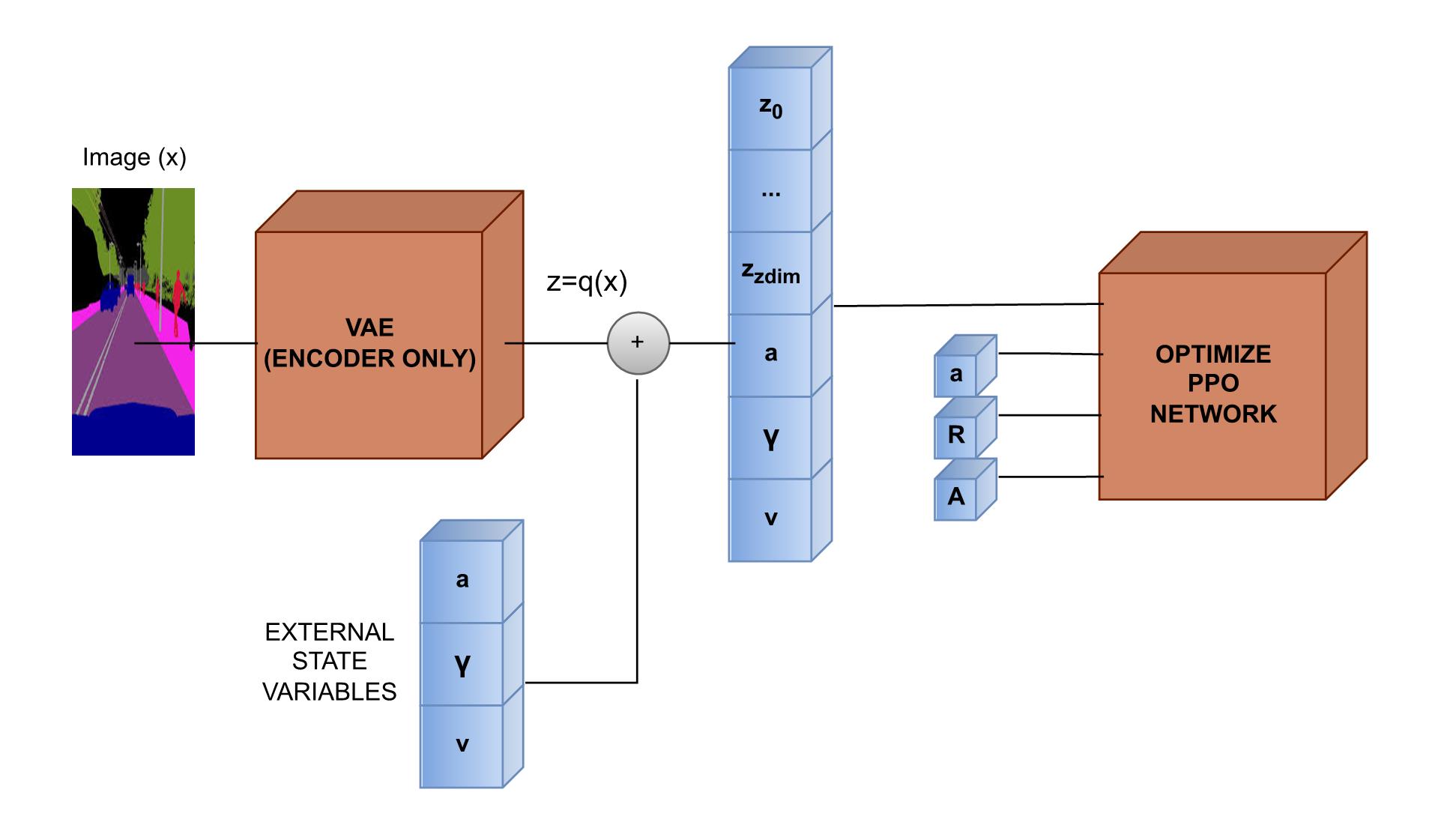
技术框架:整体框架包含以下几个主要模块:1) 基于CARLA模拟器的自动驾驶环境;2) 基于近端策略优化(PPO)的深度强化学习智能体;3) 用于特征提取的变分自编码器(VAE);4) 课程学习模块,用于动态调整环境难度和奖励函数。训练流程如下:首先,使用VAE提取环境特征。然后,PPO智能体与环境交互,根据当前状态采取行动,并获得奖励。课程学习模块根据智能体的表现,调整环境难度和奖励函数中的碰撞惩罚权重。重复以上步骤,直到智能体达到预定的性能指标。
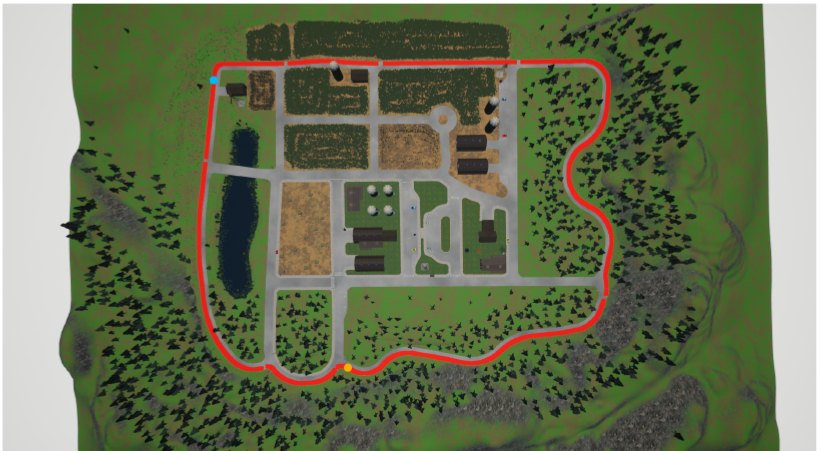
关键创新:论文的关键创新在于将课程学习与深度强化学习相结合,并设计了一种双重课程学习策略。第一重课程学习逐步增加环境的复杂性,例如增加车辆数量、改变天气条件等。第二重课程学习逐步增加奖励函数中碰撞惩罚的权重,引导智能体学习安全驾驶行为。这种双重课程学习策略能够有效地提高智能体的泛化能力和安全性。
关键设计:论文使用了PPO作为强化学习算法,因为它具有较好的稳定性和收敛性。VAE用于提取环境的低维特征表示,降低了状态空间的维度。奖励函数的设计至关重要,除了速度奖励外,还包括碰撞惩罚、偏离车道惩罚等。课程学习的难度调整策略需要仔细设计,以避免智能体陷入局部最优解。具体的参数设置,如PPO的学习率、折扣因子,VAE的隐层维度等,需要通过实验进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了CuRLA的有效性。实验结果表明,与传统的深度强化学习方法相比,CuRLA能够显著提高自动驾驶智能体在复杂环境中的性能,减少碰撞事故的发生。具体而言,CuRLA在CARLA模拟器中实现了更高的平均速度和更低的碰撞率,证明了其在提升自动驾驶安全性和效率方面的潜力。
🎯 应用场景
该研究成果可应用于自动驾驶系统的开发与测试,尤其是在复杂城市环境和恶劣天气条件下的自动驾驶。通过课程学习,可以有效地提高自动驾驶系统在各种场景下的适应性和安全性。此外,该方法还可以推广到其他机器人控制领域,例如无人机导航、机器人操作等。
📄 摘要(原文)
In autonomous driving, traditional Computer Vision (CV) agents often struggle in unfamiliar situations due to biases in the training data. Deep Reinforcement Learning (DRL) agents address this by learning from experience and maximizing rewards, which helps them adapt to dynamic environments. However, ensuring their generalization remains challenging, especially with static training environments. Additionally, DRL models lack transparency, making it difficult to guarantee safety in all scenarios, particularly those not seen during training. To tackle these issues, we propose a method that combines DRL with Curriculum Learning for autonomous driving. Our approach uses a Proximal Policy Optimization (PPO) agent and a Variational Autoencoder (VAE) to learn safe driving in the CARLA simulator. The agent is trained using two-fold curriculum learning, progressively increasing environment difficulty and incorporating a collision penalty in the reward function to promote safety. This method improves the agent's adaptability and reliability in complex environments, and understand the nuances of balancing multiple reward components from different feedback signals in a single scalar reward function. Keywords: Computer Vision, Deep Reinforcement Learning, Variational Autoencoder, Proximal Policy Optimization, Curriculum Learning, Autonomous Driving.