Self-Supervised Representation Learning with Joint Embedding Predictive Architecture for Automotive LiDAR Object Detection
作者: Haoran Zhu, Zhenyuan Dong, Kristi Topollai, Beiyao Sha, Anna Choromanska
分类: cs.RO, cs.CV
发布日期: 2025-01-09 (更新: 2025-10-07)
💡 一句话要点
提出AD-L-JEPA,用于自动驾驶LiDAR目标检测的自监督表征学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 LiDAR点云 目标检测 联合嵌入预测 自动驾驶
📋 核心要点
- 现有自监督学习方法在自动驾驶场景中直接应用对比学习或生成式方法效果不佳,甚至可能导致负迁移。
- AD-L-JEPA通过预测鸟瞰图嵌入来捕捉驾驶场景的多样性,并采用方差正则化避免表征崩溃,无需手动构建对比对。
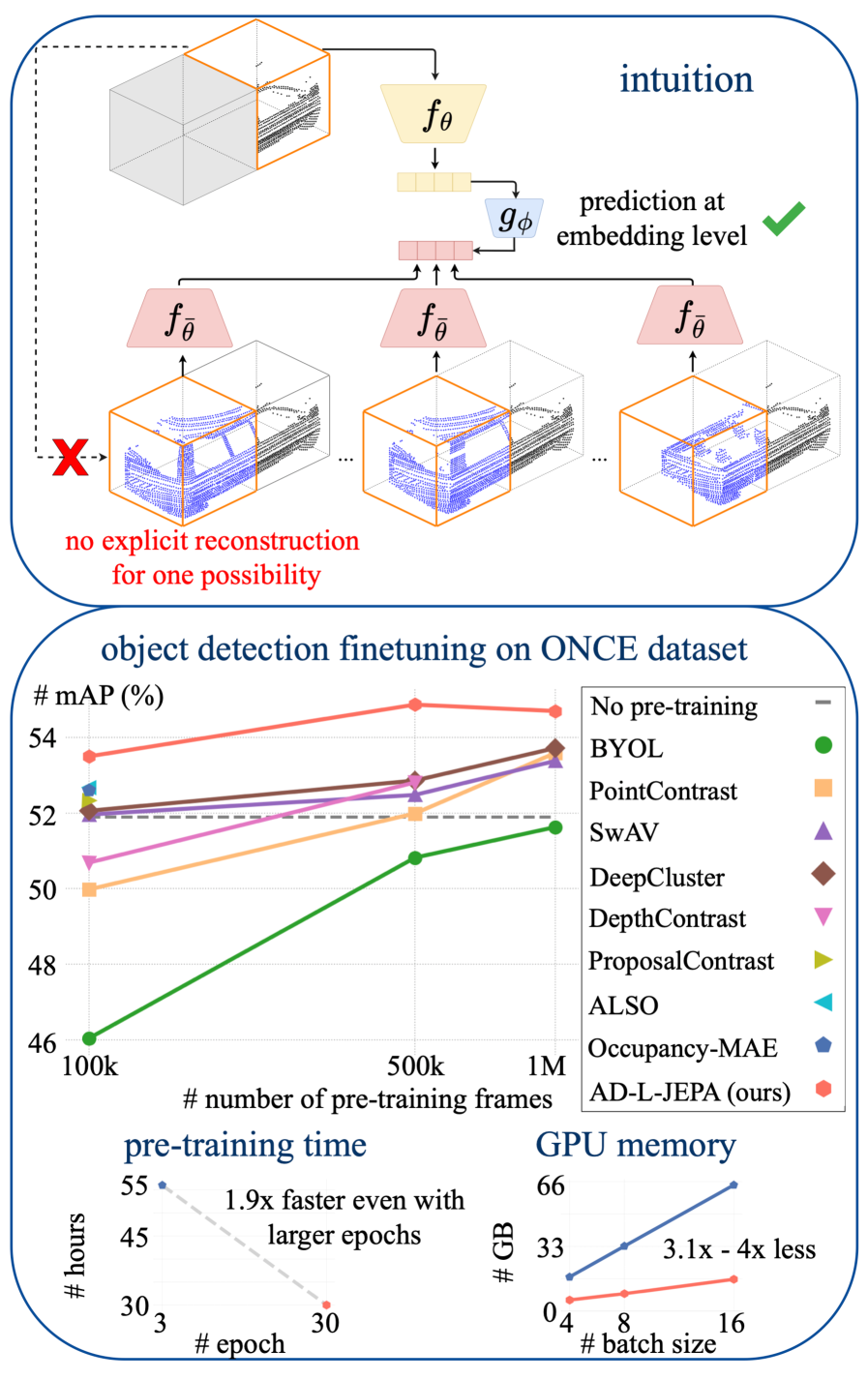
- 实验表明,AD-L-JEPA在多个数据集上提升了LiDAR 3D目标检测性能,并显著降低了GPU时间和内存消耗。
📝 摘要(中文)
本文提出了一种新颖的自监督预训练框架AD-L-JEPA,它采用联合嵌入预测架构(JEPA)用于自动驾驶LiDAR目标检测。与现有的对比学习或生成式方法不同,AD-L-JEPA既非生成式也非对比式。该方法不显式地生成掩码区域,而是预测鸟瞰图(BEV)嵌入,以捕捉驾驶场景的多样性。此外,该方法通过采用显式的方差正则化来避免表征崩溃,从而消除了手动形成对比对的需求。实验结果表明,在KITTI3D、Waymo和ONCE数据集上,LiDAR 3D目标检测下游任务的性能均得到一致提升,同时与最先进的方法Occupancy-MAE相比,GPU使用时间减少了1.9倍-2.7倍,GPU内存减少了2.8倍-4倍。值得注意的是,在最大的ONCE数据集上,使用10万帧进行预训练可获得1.61 mAP的增益,优于所有其他使用10万或50万帧进行预训练的方法;使用50万帧进行预训练可获得2.98 mAP的增益,优于所有其他使用50万或100万帧进行预训练的方法。AD-L-JEPA是第一个基于JEPA的自动驾驶预训练方法,它提供了更高质量、更快、更节省GPU内存的自监督表征学习。AD-L-JEPA的源代码即将发布。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景下,LiDAR点云数据自监督表征学习的问题。现有方法,如对比学习和生成式方法,直接应用于该场景效果不佳,可能导致负迁移。这些方法或者需要手动构建对比样本对,或者计算复杂度高,资源消耗大。
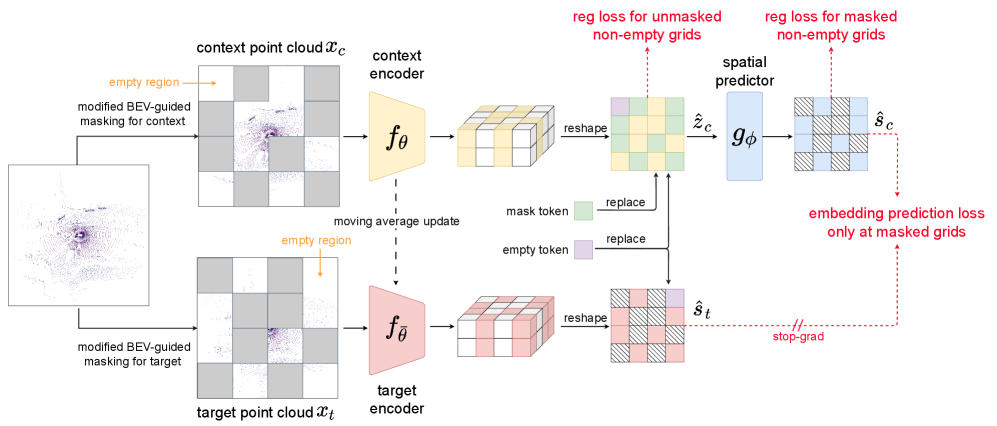
核心思路:论文的核心思路是利用联合嵌入预测架构(JEPA),通过预测鸟瞰图(BEV)嵌入来学习LiDAR点云的表征。这种方法避免了显式地生成掩码区域,而是直接学习场景的整体结构信息。同时,采用方差正则化来避免表征崩溃,从而无需手动构建对比样本对。
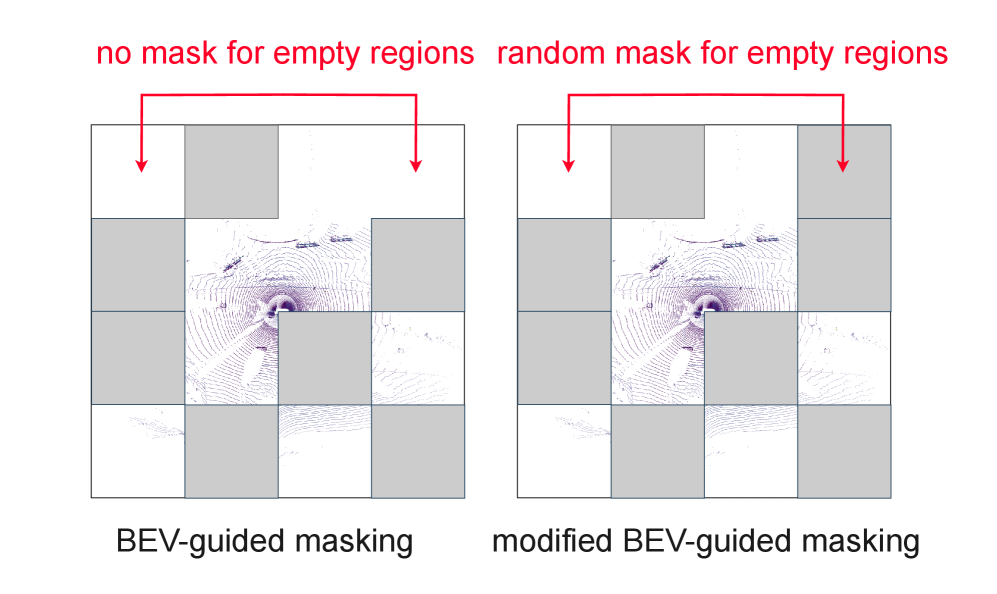
技术框架:AD-L-JEPA框架主要包含以下几个模块:1) LiDAR点云数据输入;2) BEV编码器,将点云数据转换为BEV特征图;3) 掩码模块,对BEV特征图进行随机掩码;4) 预测器,基于未掩码的BEV特征预测被掩码区域的BEV嵌入;5) 损失函数,用于衡量预测的BEV嵌入与真实BEV嵌入之间的差异。整个框架通过最小化损失函数来学习LiDAR点云的表征。
关键创新:AD-L-JEPA的关键创新在于:1) 首次将JEPA架构应用于自动驾驶LiDAR点云数据的自监督学习;2) 提出了一种基于BEV嵌入预测的自监督学习方法,能够有效捕捉驾驶场景的多样性;3) 采用方差正则化来避免表征崩溃,无需手动构建对比样本对,简化了训练过程。
关键设计:在BEV编码器方面,可以使用现有的BEV编码器,如VoxelNet或PointPillars。掩码模块采用随机掩码策略,掩码比例可以根据实际情况进行调整。预测器可以使用Transformer或MLP等网络结构。损失函数可以使用L1或L2损失函数。方差正则化的系数需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
AD-L-JEPA在KITTI3D、Waymo和ONCE数据集上均取得了显著的性能提升。在ONCE数据集上,使用10万帧进行预训练,mAP提升了1.61,优于其他使用10万或50万帧预训练的方法;使用50万帧进行预训练,mAP提升了2.98,优于其他使用50万或100万帧预训练的方法。同时,与Occupancy-MAE相比,GPU使用时间减少了1.9x-2.7x,GPU内存减少了2.8x-4x。
🎯 应用场景
该研究成果可广泛应用于自动驾驶领域,例如提升LiDAR 3D目标检测的精度和鲁棒性,降低对大量标注数据的依赖,加速自动驾驶系统的开发和部署。此外,该方法还可以应用于其他LiDAR相关的任务,如语义分割、场景重建等,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Recently, self-supervised representation learning relying on vast amounts of unlabeled data has been explored as a pre-training method for autonomous driving. However, directly applying popular contrastive or generative methods to this problem is insufficient and may even lead to negative transfer. In this paper, we present AD-L-JEPA, a novel self-supervised pre-training framework with a joint embedding predictive architecture (JEPA) for automotive LiDAR object detection. Unlike existing methods, AD-L-JEPA is neither generative nor contrastive. Instead of explicitly generating masked regions, our method predicts Bird's-Eye-View embeddings to capture the diverse nature of driving scenes. Furthermore, our approach eliminates the need to manually form contrastive pairs by employing explicit variance regularization to avoid representation collapse. Experimental results demonstrate consistent improvements on the LiDAR 3D object detection downstream task across the KITTI3D, Waymo, and ONCE datasets, while reducing GPU hours by 1.9x-2.7x and GPU memory by 2.8x-4x compared with the state-of-the-art method Occupancy-MAE. Notably, on the largest ONCE dataset, pre-training on 100K frames yields a 1.61 mAP gain, better than all other methods pre-trained on either 100K or 500K frames, and pre-training on 500K frames yields a 2.98 mAP gain, better than all other methods pre-trained on either 500K or 1M frames. AD-L-JEPA constitutes the first JEPA-based pre-training method for autonomous driving. It offers better quality, faster, and more GPU-memory-efficient self-supervised representation learning. The source code of AD-L-JEPA is ready to be released.