VTAO-BiManip: Masked Visual-Tactile-Action Pre-training with Object Understanding for Bimanual Dexterous Manipulation
作者: Zhengnan Sun, Zhaotai Shi, Jiayin Chen, Qingtao Liu, Yu Cui, Qi Ye, Jiming Chen
分类: cs.RO, cs.CV
发布日期: 2025-01-07 (更新: 2025-12-25)
💡 一句话要点
VTAO-BiManip:面向灵巧双手动手的视觉-触觉-动作掩码预训练与物体理解
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双手动手操作 视觉触觉融合 动作预训练 物体理解 课程强化学习
📋 核心要点
- 双手动手操作因每个手的自由度高以及双手协调困难而极具挑战。
- VTAO-BiManip通过视觉-触觉-动作预训练和物体理解,指导课程强化学习,提升双手动手操作能力。
- 实验表明,该方法在瓶盖拧开任务中超越现有方法,成功率提升超过20%。
📝 摘要(中文)
本文提出VTAO-BiManip框架,结合视觉-触觉-动作预训练与物体理解,促进课程强化学习,实现类人双手动手操作。通过整合手部运动数据改进预训练,为双手协调提供比二元触觉反馈更有效的指导。预训练模型利用掩码多模态输入预测未来动作以及物体姿态和尺寸,从而促进跨模态正则化。为解决多技能学习挑战,引入两阶段课程强化学习方法以稳定训练。在瓶盖拧开任务上的评估表明,该方法在模拟和真实环境中均有效,成功率超过现有视觉-触觉预训练方法20%以上。
🔬 方法详解
问题定义:现有单手操作技术依赖人类演示指导强化学习,但难以泛化到涉及多个子技能的复杂双手任务。双手动手操作的关键挑战在于高自由度带来的控制复杂性,以及如何有效协调双手完成任务。
核心思路:VTAO-BiManip的核心在于利用视觉、触觉和动作信息进行预训练,并结合物体理解,从而学习到更有效的双手协调策略。通过预训练,模型能够预测未来动作和物体状态,为后续的强化学习提供更好的初始化和指导。
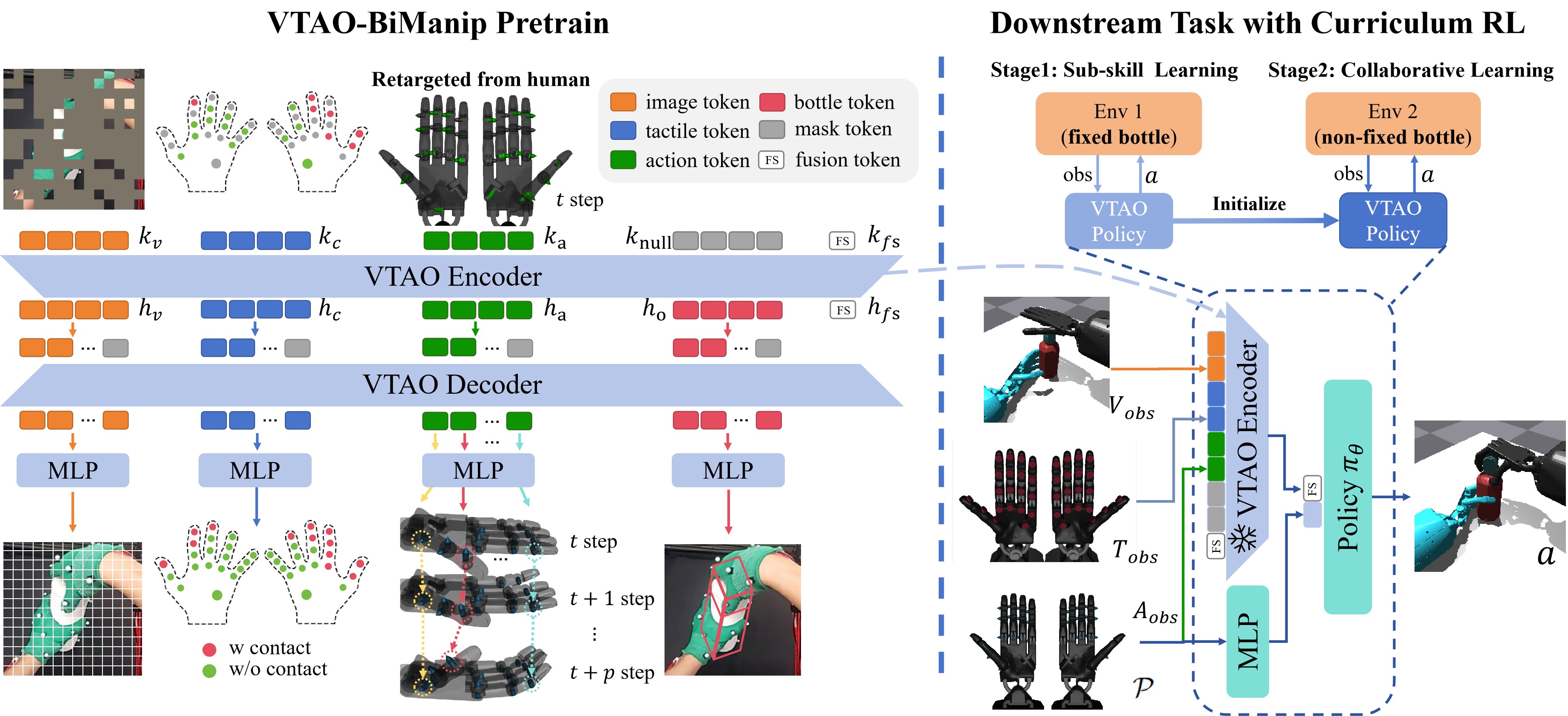
技术框架:VTAO-BiManip框架包含三个主要部分:1) 多模态数据收集,包括视觉、触觉和动作数据;2) 掩码多模态预训练,模型学习预测被掩盖的动作和物体状态;3) 两阶段课程强化学习,首先学习单个子技能,然后学习双手协调完成完整任务。
关键创新:该方法最重要的创新点在于将视觉、触觉和动作信息融合到预训练中,并利用掩码机制进行跨模态学习。与仅使用视觉或触觉信息的预训练方法相比,VTAO-BiManip能够学习到更丰富的环境和任务信息,从而更好地指导强化学习。此外,两阶段课程强化学习策略也提高了训练的稳定性和效率。
关键设计:预训练模型使用Transformer架构,输入包括视觉特征、触觉传感器数据和手部动作。掩码比例设置为50%,模型需要预测被掩盖的动作和物体姿态。损失函数包括动作预测损失和物体状态预测损失。课程强化学习的第一阶段训练单个手的控制策略,第二阶段训练双手协调策略,使用PPO算法进行训练。
🖼️ 关键图片


📊 实验亮点
在瓶盖拧开任务中,VTAO-BiManip在模拟和真实环境中均取得了显著的成果。与现有的视觉-触觉预训练方法相比,VTAO-BiManip的成功率提高了20%以上。这表明该方法能够有效地学习到双手协调策略,并具有良好的泛化能力。实验结果验证了VTAO-BiManip在复杂双手动手操作任务中的有效性。
🎯 应用场景
VTAO-BiManip技术可应用于各种需要灵巧双手动手操作的机器人任务,例如装配、医疗手术、家庭服务等。该研究有助于提升机器人在复杂环境中的操作能力,降低对人工示教的依赖,实现更自主、智能的机器人系统。未来,该技术有望应用于更广泛的机器人领域,推动机器人技术的发展。
📄 摘要(原文)
Bimanual dexterous manipulation remains significant challenges in robotics due to the high DoFs of each hand and their coordination. Existing single-hand manipulation techniques often leverage human demonstrations to guide RL methods but fail to generalize to complex bimanual tasks involving multiple sub-skills. In this paper, we introduce VTAO-BiManip, a novel framework that combines visual-tactile-action pretraining with object understanding to facilitate curriculum RL to enable human-like bimanual manipulation. We improve prior learning by incorporating hand motion data, providing more effective guidance for dual-hand coordination than binary tactile feedback. Our pretraining model predicts future actions as well as object pose and size using masked multimodal inputs, facilitating cross-modal regularization. To address the multi-skill learning challenge, we introduce a two-stage curriculum RL approach to stabilize training. We evaluate our method on a bottle-cap unscrewing task, demonstrating its effectiveness in both simulated and real-world environments. Our approach achieves a success rate that surpasses existing visual-tactile pretraining methods by over 20%.