Attribute-Based Robotic Grasping with Data-Efficient Adaptation
作者: Yang Yang, Houjian Yu, Xibai Lou, Yuanhao Liu, Changhyun Choi
分类: cs.RO, cs.AI
发布日期: 2025-01-04
备注: Project page: https://z.umn.edu/attr-grasp. arXiv admin note: substantial text overlap with arXiv:2104.02271
期刊: IEEE Transactions on Robotics, vol. 40, pp. 1566-1579, 2024
💡 一句话要点
提出基于属性的机器人抓取方法,实现数据高效的领域自适应
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人抓取 属性学习 领域自适应 数据高效 深度学习
📋 核心要点
- 现有机器人抓取方法难以快速适应新物体和环境,需要大量数据进行训练。
- 利用物体属性(如颜色、形状)作为中间表示,结合视觉和文本信息,提升泛化能力。
- 提出对抗自适应和单次抓取自适应方法,显著提高数据效率和抓取成功率。
📝 摘要(中文)
本文提出了一种基于属性的机器人抓取方法,旨在解决在杂乱环境中快速教会机器人抓取新目标物体的挑战。该方法利用物体属性来促进识别、抓取以及快速适应新领域。我们提出了一个端到端编码器-解码器网络,以学习基于属性的机器人抓取,并具备数据高效的自适应能力。首先,我们使用各种基本物体预训练端到端模型,以学习用于识别和抓取的通用属性表示。我们的方法使用门控注意力机制融合工作空间图像和查询文本的嵌入,并学习预测实例抓取的可供性。为了训练视觉和文本属性的联合嵌入空间,机器人利用抓取前后物体的持久性。我们的模型在模拟环境中进行自监督训练,仅使用各种颜色和形状的基本物体,但可以推广到新环境中的新物体。为了进一步促进泛化,我们提出了两种自适应方法:对抗自适应和单次抓取自适应。对抗自适应使用未标记图像的增强数据来调节图像编码器,而单次抓取自适应使用来自一次抓取试验的增强数据来更新整个端到端模型。两种自适应方法都具有数据高效性,并显着提高了实例抓取性能。在模拟和真实世界的实验结果表明,我们的方法在未知物体上的实例抓取成功率超过81%,大大优于几种基线方法。
🔬 方法详解
问题定义:现有机器人抓取系统在面对新的物体和环境时,需要大量的训练数据才能达到较好的性能。这限制了它们在实际场景中的应用,因为收集和标注大量数据成本高昂。此外,如何有效地利用少量数据进行快速自适应也是一个挑战。
核心思路:本文的核心思路是利用物体属性作为视觉和抓取之间的桥梁。通过学习物体属性的通用表示,模型可以更好地泛化到新的物体。同时,结合文本描述,可以更精确地指导抓取。此外,通过对抗自适应和单次抓取自适应,可以进一步提高模型在目标领域的性能,并降低对大量标注数据的依赖。
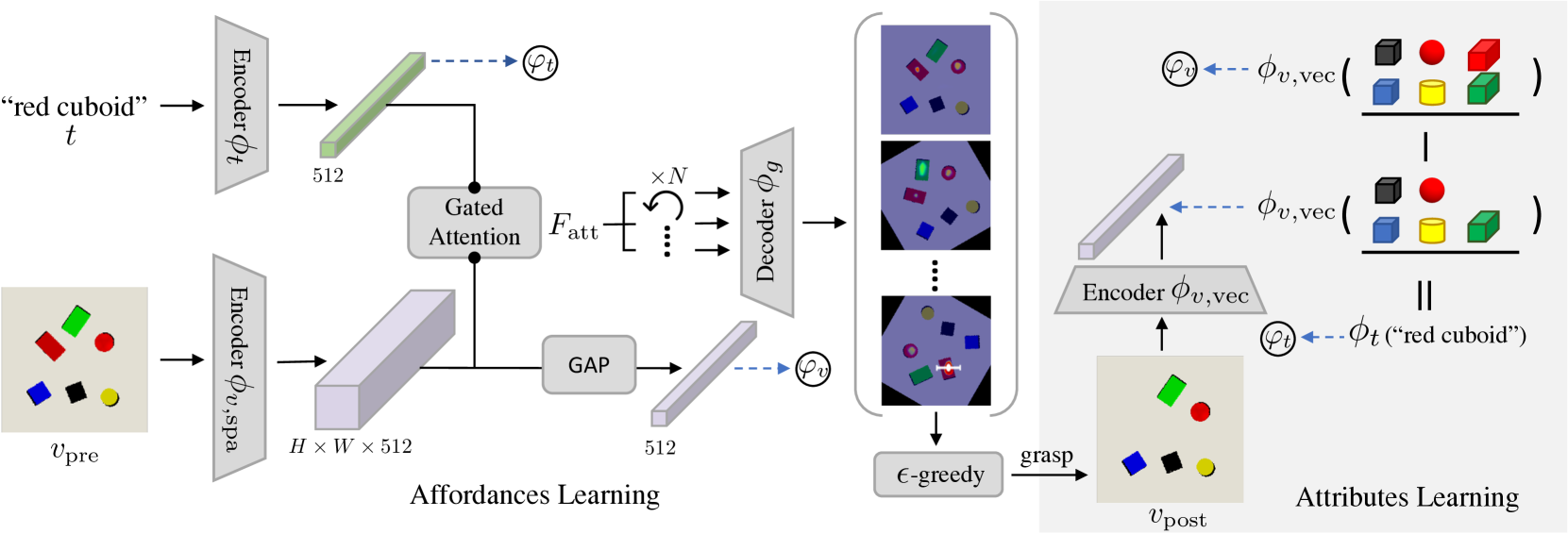
技术框架:该方法采用端到端的编码器-解码器网络结构。整体流程如下:1) 使用包含多种基本物体的合成数据集预训练模型,学习通用属性表示。2) 使用门控注意力机制融合工作空间图像和查询文本的嵌入。3) 预测实例抓取的可供性。4) 使用对抗自适应和单次抓取自适应方法,在目标领域进行微调。
关键创新:该方法最重要的技术创新点在于:1) 利用物体属性作为视觉和抓取之间的桥梁,提高了模型的泛化能力。2) 提出了对抗自适应和单次抓取自适应方法,实现了数据高效的领域自适应。3) 使用门控注意力机制融合视觉和文本信息,提高了抓取的精度。
关键设计:1) 门控注意力机制:用于融合图像和文本嵌入,突出与抓取相关的特征。2) 对抗自适应:使用判别器区分源域和目标域的图像特征,促使图像编码器学习领域不变的特征。3) 单次抓取自适应:使用一次抓取试验的数据进行增广,并更新整个端到端模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在未知物体上的实例抓取成功率超过81%,显著优于基线方法。对抗自适应和单次抓取自适应方法能够有效提高模型在目标领域的性能,即使在只有少量数据的情况下也能取得良好的效果。例如,单次抓取自适应仅使用一次抓取试验的数据,就能显著提升抓取成功率。
🎯 应用场景
该研究成果可应用于各种机器人抓取场景,例如:工业自动化中的零件抓取、家庭服务机器人中的物品整理、以及物流仓储中的货物拣选。通过数据高效的自适应能力,机器人可以快速适应新的工作环境和目标物体,降低部署成本,提高工作效率。未来,该技术有望进一步扩展到更复杂的机器人操作任务中。
📄 摘要(原文)
Robotic grasping is one of the most fundamental robotic manipulation tasks and has been the subject of extensive research. However, swiftly teaching a robot to grasp a novel target object in clutter remains challenging. This paper attempts to address the challenge by leveraging object attributes that facilitate recognition, grasping, and rapid adaptation to new domains. In this work, we present an end-to-end encoder-decoder network to learn attribute-based robotic grasping with data-efficient adaptation capability. We first pre-train the end-to-end model with a variety of basic objects to learn generic attribute representation for recognition and grasping. Our approach fuses the embeddings of a workspace image and a query text using a gated-attention mechanism and learns to predict instance grasping affordances. To train the joint embedding space of visual and textual attributes, the robot utilizes object persistence before and after grasping. Our model is self-supervised in a simulation that only uses basic objects of various colors and shapes but generalizes to novel objects in new environments. To further facilitate generalization, we propose two adaptation methods, adversarial adaption and one-grasp adaptation. Adversarial adaptation regulates the image encoder using augmented data of unlabeled images, whereas one-grasp adaptation updates the overall end-to-end model using augmented data from one grasp trial. Both adaptation methods are data-efficient and considerably improve instance grasping performance. Experimental results in both simulation and the real world demonstrate that our approach achieves over 81% instance grasping success rate on unknown objects, which outperforms several baselines by large margins.