EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
作者: Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yue Hu, Yue Liao, Peng Gao, Hongsheng Li, Maoqing Yao, Guanghui Ren
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-01-03 (更新: 2025-11-16)
备注: Accepted by NeurIPS 2025. Website: https://sites.google.com/view/enerverse
💡 一句话要点
EnerVerse:用于机器人操作的具身未来空间生成式基础模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 生成式模型 视频扩散模型 具身智能 多视角视频 模拟到真实 长期推理 4D高斯溅射
📋 核心要点
- 现有机器人操作方法在长期推理和处理运动模糊、3D定位等问题上存在不足。
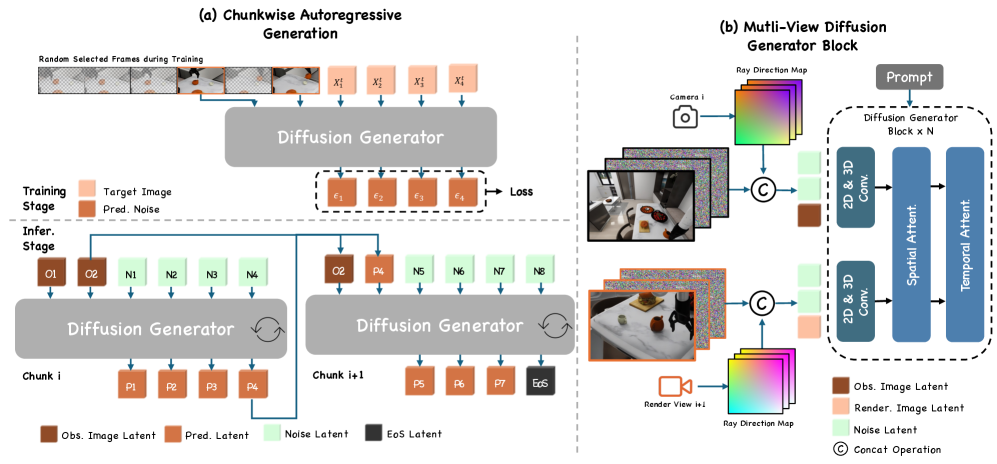
- EnerVerse通过分块自回归视频扩散模型预测未来具身空间,并引入多视角视频表示增强3D建模能力。
- EnerVerse-D数据引擎结合生成模型和4D高斯溅射,构建自增强数据循环,有效缩小了模拟到真实的差距。
📝 摘要(中文)
我们提出了EnerVerse,一个生成式机器人基础模型,用于构建和解释具身空间。EnerVerse采用分块自回归视频扩散框架,从指令预测未来的具身空间,并利用稀疏上下文记忆进行长期推理。为了对3D机器人世界进行建模,我们采用了多视角视频表示,提供丰富的视角来解决运动模糊和3D定位等挑战。此外,EnerVerse-D,一个结合生成建模和4D高斯溅射的数据引擎管道,形成一个自增强数据循环,以减少模拟到真实的差距。利用这些创新,EnerVerse通过策略头(EnerVerse-A)将4D世界表示转化为物理动作,在模拟和真实世界的任务中都实现了最先进的性能。为了提高效率,EnerVerse-A重用来自第一步去噪的特征,并预测动作块,在单个RTX 4090上实现了大约280毫秒/8步动作块的速度。更多的视频演示和数据集样本可以在我们的项目页面找到。
🔬 方法详解
问题定义:论文旨在解决机器人操作中长期推理、运动模糊和3D定位等问题。现有方法难以有效预测未来具身空间,并且在模拟环境和真实环境之间存在较大差距,限制了机器人的泛化能力。
核心思路:论文的核心思路是利用生成式模型EnerVerse,通过学习大量机器人操作数据,预测未来具身空间,并将预测结果转化为物理动作。通过多视角视频表示和自增强数据循环,提高模型的3D建模能力和泛化能力。
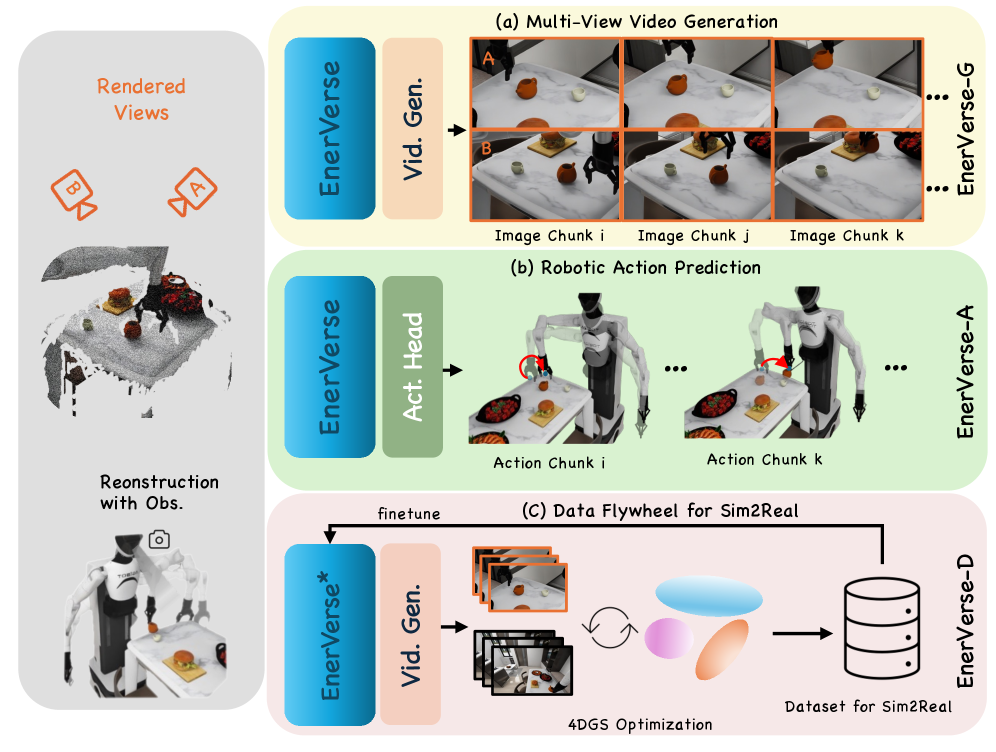
技术框架:EnerVerse包含以下主要模块:1) 分块自回归视频扩散框架,用于从指令预测未来具身空间;2) 稀疏上下文记忆,用于长期推理;3) 多视角视频表示,用于增强3D建模能力;4) EnerVerse-D数据引擎,用于生成高质量的训练数据;5) 策略头EnerVerse-A,用于将4D世界表示转化为物理动作。
关键创新:论文的关键创新在于:1) 提出了EnerVerse,一个生成式机器人基础模型,能够构建和解释具身空间;2) 采用了分块自回归视频扩散框架,提高了视频预测的效率和准确性;3) 引入了EnerVerse-D数据引擎,通过自增强数据循环,有效缩小了模拟到真实的差距。
关键设计:EnerVerse-A重用来自第一步去噪的特征,并预测动作块,从而提高了动作预测的效率。在单个RTX 4090上实现了大约280毫秒/8步动作块的速度。EnerVerse-D结合生成建模和4D高斯溅射,生成高质量的训练数据,用于训练EnerVerse模型。
🖼️ 关键图片

📊 实验亮点
EnerVerse在模拟和真实世界的机器人操作任务中都取得了最先进的性能。EnerVerse-A通过重用特征和预测动作块,在单个RTX 4090上实现了大约280毫秒/8步动作块的速度,显著提高了动作预测的效率。EnerVerse-D数据引擎有效缩小了模拟到真实的差距,提高了模型的泛化能力。
🎯 应用场景
EnerVerse可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。该研究有助于提高机器人的智能化水平和泛化能力,使其能够更好地适应复杂多变的环境,完成各种任务。未来,EnerVerse有望成为机器人领域的基础模型,推动机器人技术的快速发展。
📄 摘要(原文)
We introduce EnerVerse, a generative robotics foundation model that constructs and interprets embodied spaces. EnerVerse employs a chunk-wise autoregressive video diffusion framework to predict future embodied spaces from instructions, enhanced by a sparse context memory for long-term reasoning. To model the 3D robotics world, we adopt a multi-view video representation, providing rich perspectives to address challenges like motion ambiguity and 3D grounding. Additionally, EnerVerse-D, a data engine pipeline combining generative modeling with 4D Gaussian Splatting, forms a self-reinforcing data loop to reduce the sim-to-real gap. Leveraging these innovations, EnerVerse translates 4D world representations into physical actions via a policy head (EnerVerse-A), achieving state-of-the-art performance in both simulation and real-world tasks. For efficiency, EnerVerse-A reuses features from the first denoising step and predicts action chunks, achieving about 280 ms per 8-step action chunk on a single RTX 4090. Further video demos, dataset samples could be found in our project page.