Contrastive Learning from Exploratory Actions: Leveraging Natural Interactions for Preference Elicitation
作者: Nathaniel Dennler, Stefanos Nikolaidis, Maja Matarić
分类: cs.RO, cs.AI, cs.HC, cs.LG
发布日期: 2025-01-02
备注: Accepted to HRI 2025
💡 一句话要点
提出CLEA:利用探索性行为的对比学习进行偏好获取
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 偏好获取 人机交互 机器人学习 探索性行为
📋 核心要点
- 现有方法难以提取用户偏好的机器人行为特征,从原始数据学习缺乏语义,从用户数据学习需要繁琐标注。
- CLEA利用用户在自定义机器人时的探索性行为,通过对比学习提取与用户偏好对齐的轨迹特征。
- 实验表明,CLEA特征在偏好获取的完整性、简单性、最小性和可解释性方面优于自监督特征。
📝 摘要(中文)
为了理解和推断用户对机器人行为的偏好,机器人需要学习一个奖励函数,该函数描述了机器人行为与用户偏好的一致性程度。机器人行为的良好表征可以显著减少用户教导机器人其偏好所需的时间和精力。然而,指定这些表征(即机器人行为的哪些“特征”对用户重要)仍然是一个难题;从原始数据中学习的特征缺乏语义意义,而从用户数据中学习的特征需要用户参与繁琐的标注过程。我们的关键见解是,执行自定义机器人任务的用户具有通过探索性搜索生成标签的内在动机;他们探索自己感兴趣的行为,而忽略不相关的行为。为了利用这种探索性行为的新数据源,我们提出了从探索性行为中进行对比学习(CLEA),以学习与用户关心的特征对齐的轨迹特征。我们从用户在使用Kuri机器人进行开放式信号设计活动(N=25)中执行的探索性行为中学习了CLEA特征,并通过对另一组用户(N=42)进行的第二项用户研究评估了CLEA特征。在完整性、简单性、最小性和可解释性这四个指标上,CLEA特征优于自监督特征。
🔬 方法详解
问题定义:论文旨在解决如何高效地从用户与机器人的交互中学习用户偏好,并将其转化为机器人行为的奖励函数的问题。现有方法主要存在两个痛点:一是直接从原始数据学习的特征缺乏语义信息,难以解释;二是依赖用户进行大量标注,过程繁琐且耗时。
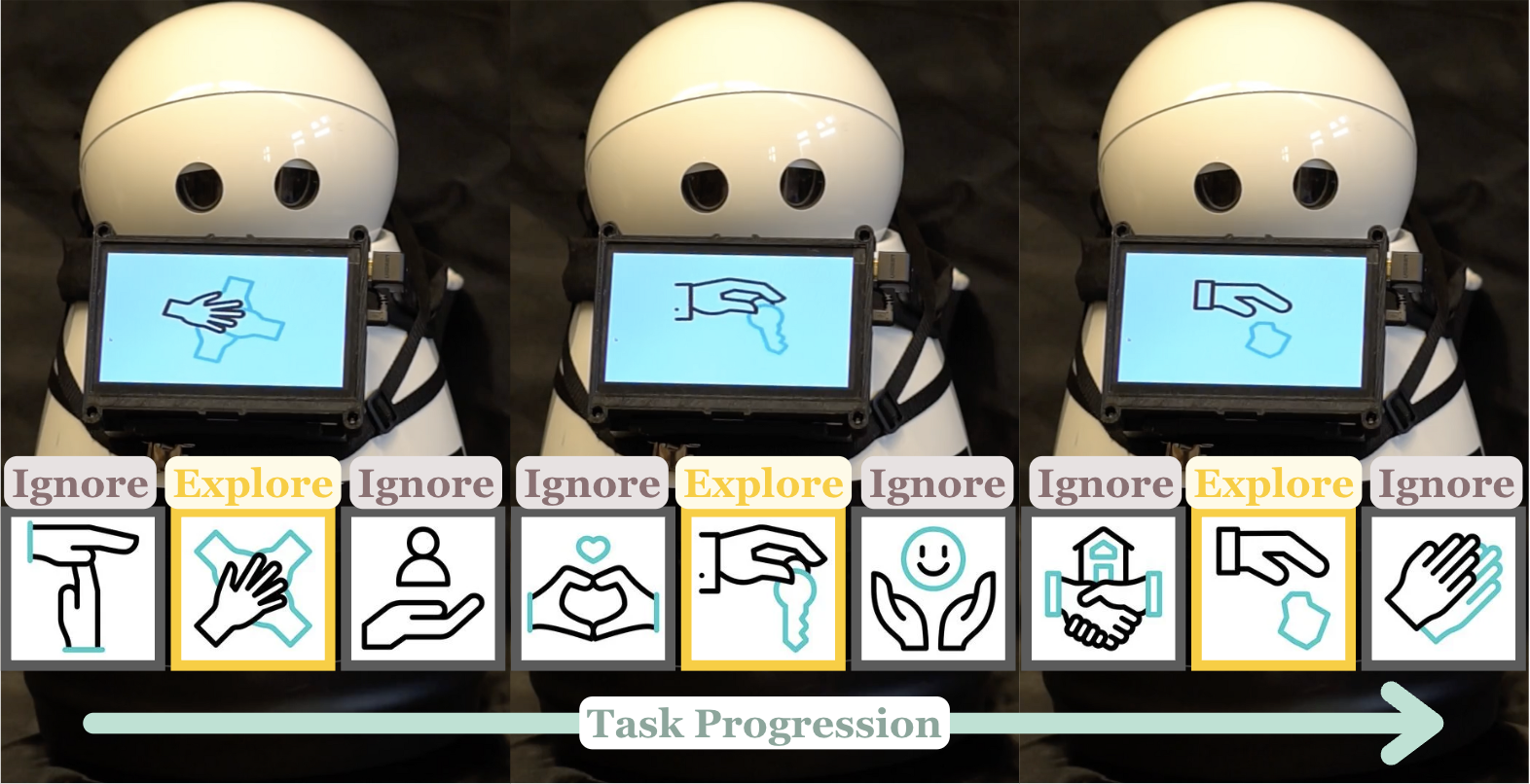
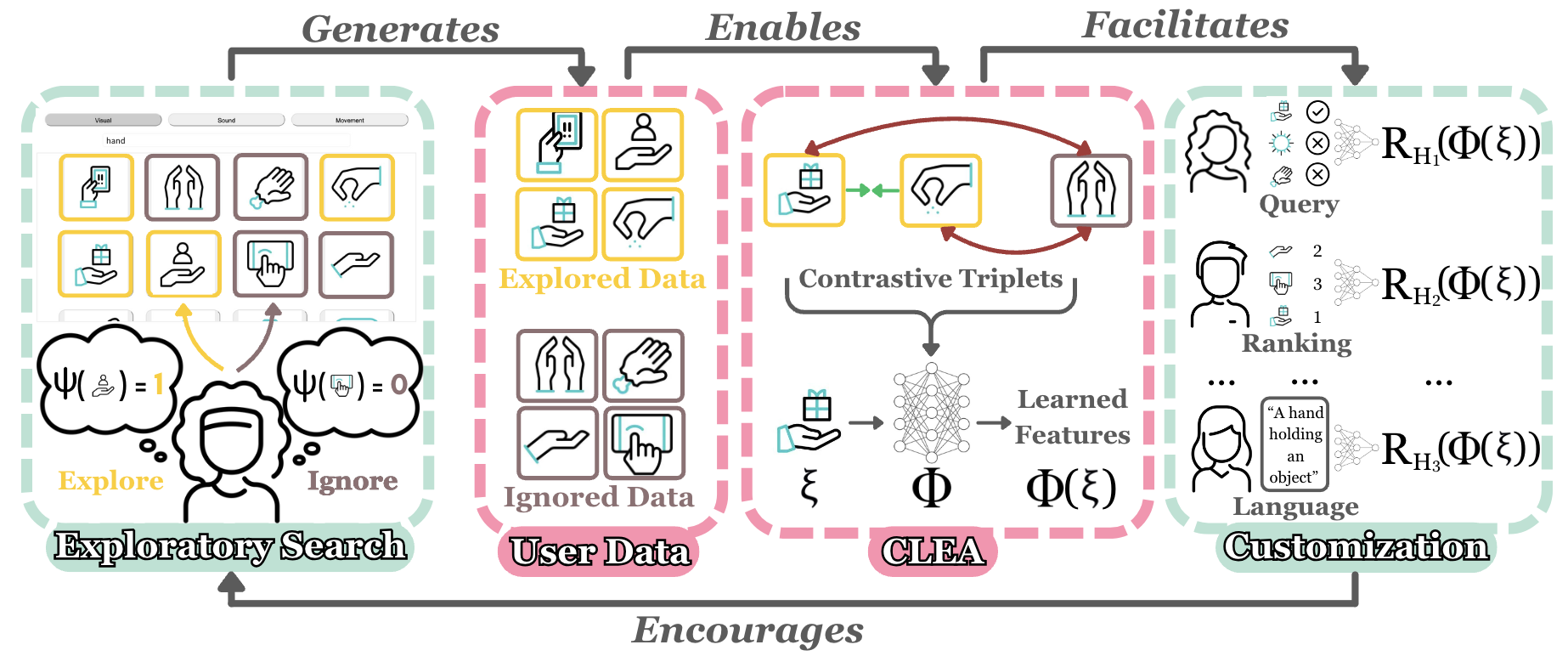
核心思路:论文的核心思路是利用用户在探索机器人行为时的内在动机,将用户的探索性行为视为一种隐式的标注信号。用户会主动探索他们感兴趣的行为,而忽略不相关的行为,因此这些探索性行为包含了用户偏好的信息。通过对比学习,可以从这些探索性行为中学习到与用户偏好对齐的轨迹特征。
技术框架:CLEA (Contrastive Learning from Exploratory Actions) 的整体框架包含以下几个主要阶段:1) 数据收集:收集用户在探索机器人行为时产生的轨迹数据。2) 特征提取:使用神经网络从轨迹数据中提取特征。3) 对比学习:使用对比损失函数训练神经网络,使得相似的轨迹(例如,同一用户探索的不同行为)在特征空间中更接近,而不相似的轨迹(例如,不同用户探索的行为)在特征空间中更远离。4) 偏好获取:使用学习到的特征来构建奖励函数,从而获取用户偏好。
关键创新:CLEA 的最重要创新在于它将用户的探索性行为视为一种隐式的标注信号,并利用对比学习来提取与用户偏好对齐的轨迹特征。与现有方法相比,CLEA 不需要用户进行显式的标注,从而大大降低了用户的工作量。此外,CLEA 学习到的特征具有更好的语义信息,更容易解释。
关键设计:CLEA 的关键设计包括:1) 使用三元组损失 (Triplet Loss) 作为对比损失函数,鼓励相似轨迹的特征更接近,不相似轨迹的特征更远离。2) 精心设计了神经网络结构,以有效地从轨迹数据中提取特征。3) 通过用户研究验证了 CLEA 的有效性,并与其他自监督学习方法进行了比较。
🖼️ 关键图片

📊 实验亮点
通过用户研究,CLEA 在偏好获取的四个关键指标(完整性、简单性、最小性和可解释性)上均优于自监督学习方法。具体来说,CLEA 能够更完整地捕捉用户偏好,生成的奖励函数更简单易懂,所需的特征数量更少,并且更容易向用户解释。这些结果表明,CLEA 是一种有效的偏好获取方法,可以显著提高人机交互的效率和质量。
🎯 应用场景
CLEA 方法可应用于各种人机交互场景,例如个性化机器人助手、可定制的智能家居设备和自适应游戏AI。通过学习用户的隐式偏好,CLEA 可以使机器人和智能系统更好地理解用户的需求,并提供更个性化的服务。该研究的未来影响在于,它可以促进人机协作的效率和自然性,并最终实现更加智能和人性化的机器人。
📄 摘要(原文)
People have a variety of preferences for how robots behave. To understand and reason about these preferences, robots aim to learn a reward function that describes how aligned robot behaviors are with a user's preferences. Good representations of a robot's behavior can significantly reduce the time and effort required for a user to teach the robot their preferences. Specifying these representations -- what "features" of the robot's behavior matter to users -- remains a difficult problem; Features learned from raw data lack semantic meaning and features learned from user data require users to engage in tedious labeling processes. Our key insight is that users tasked with customizing a robot are intrinsically motivated to produce labels through exploratory search; they explore behaviors that they find interesting and ignore behaviors that are irrelevant. To harness this novel data source of exploratory actions, we propose contrastive learning from exploratory actions (CLEA) to learn trajectory features that are aligned with features that users care about. We learned CLEA features from exploratory actions users performed in an open-ended signal design activity (N=25) with a Kuri robot, and evaluated CLEA features through a second user study with a different set of users (N=42). CLEA features outperformed self-supervised features when eliciting user preferences over four metrics: completeness, simplicity, minimality, and explainability.