Subconscious Robotic Imitation Learning
作者: Jun Xie, Zhicheng Wang, Jianwei Tan, Huanxu Lin, Xiaoguang Ma
分类: cs.RO
发布日期: 2024-12-29
💡 一句话要点
提出潜意识机器人模仿学习,加速双臂任务执行并提高成功率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人模仿学习 潜意识学习 认知卸载 动作分块 双臂机器人 增强学习 机器人控制
📋 核心要点
- 现有机器人模仿学习方法依赖计算密集的多模型轨迹预测,导致执行速度慢,限制了实时性。
- SRIL通过结合认知卸载和历史动作分块,减少模型推理延迟,并利用潜意识降采样和模式增强学习提高效率。
- 实验表明,SRIL在双臂任务中执行速度比现有方法快100%-200%,并具有更高的成功率。
📝 摘要(中文)
机器人模仿学习(RIL)在具身智能机器人领域具有广阔前景,但现有RIL方法依赖于计算密集型的多模型轨迹预测,导致执行速度慢且实时响应性有限。受人类潜意识能够持续处理和存储大量经验、感知和学习信息,从而完成复杂动作(如骑自行车)的启发,我们提出了潜意识机器人模仿学习(SRIL)。SRIL结合了认知卸载和历史动作分块,以减少模型推理造成的延迟,从而加速任务执行。通过潜意识降采样和模式增强学习策略进一步增强了这一过程,其中利用量化采样技术处理富含意图的信息,以提高操作效率。实验结果表明,在全面的双臂任务中,SRIL的执行速度比SOTA策略快100%到200%,并且成功率始终更高。
🔬 方法详解
问题定义:现有机器人模仿学习方法,特别是用于复杂双臂操作任务时,面临着计算量大、执行速度慢的问题。这些方法通常依赖于对轨迹进行多模型预测,这在计算上是昂贵的,并且限制了机器人的实时响应能力。因此,如何提高机器人模仿学习的执行速度和效率,同时保持较高的任务成功率,是一个重要的挑战。
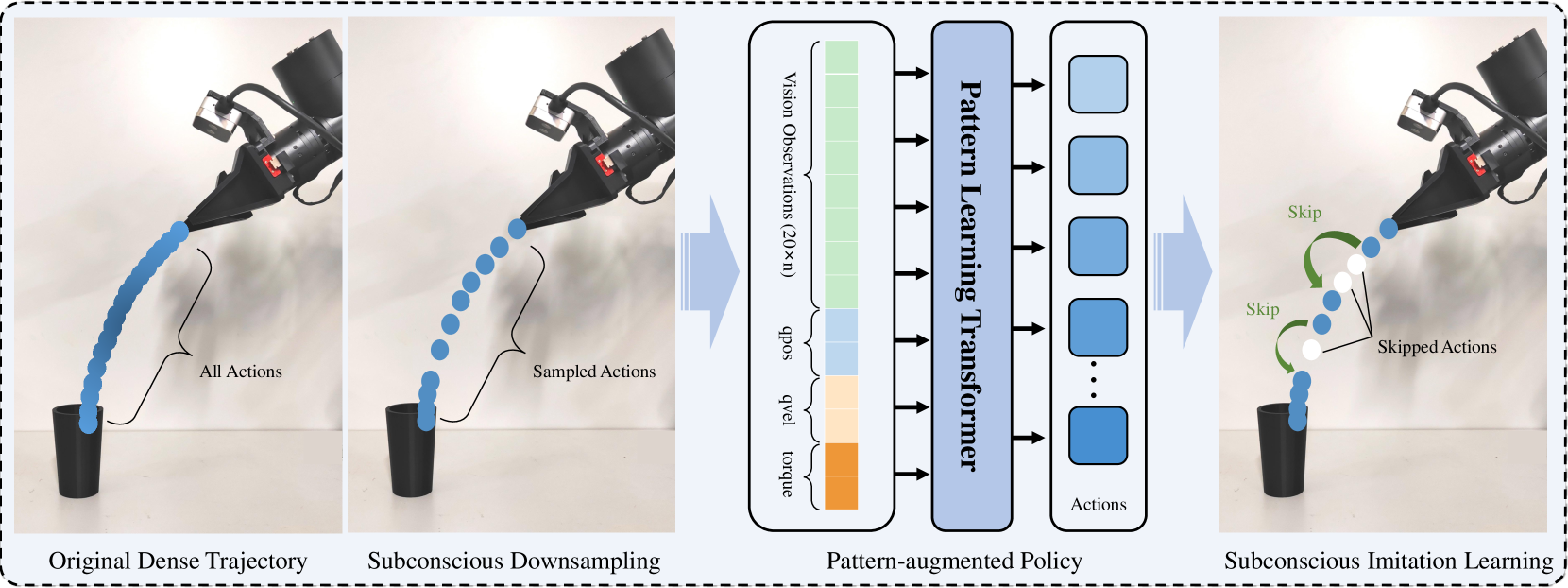
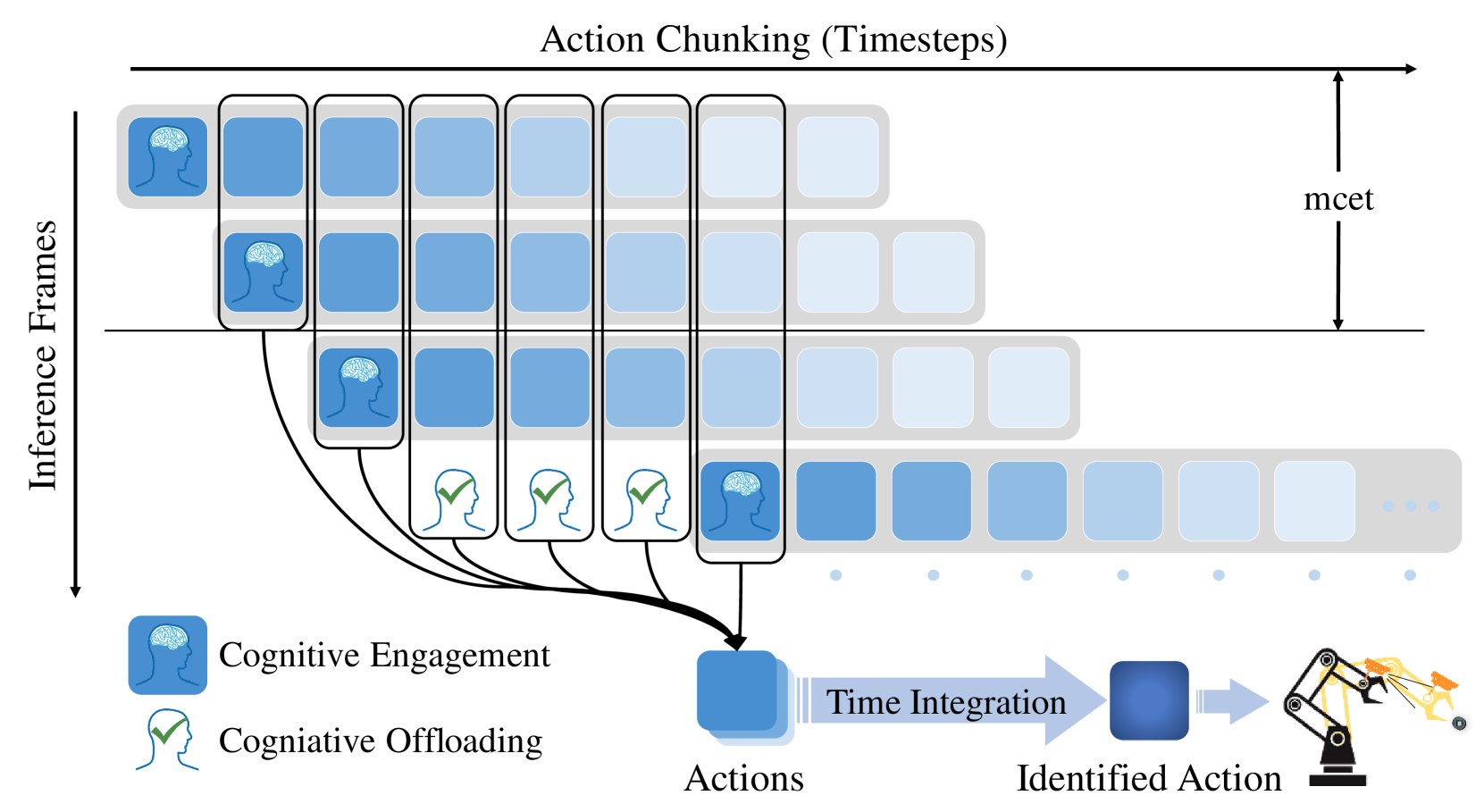
核心思路:该论文的核心思路是借鉴人类潜意识处理信息的方式,通过认知卸载和历史动作分块来减少模型推理的延迟。认知卸载指的是将一部分计算负担从在线推理转移到离线处理,而历史动作分块则是将过去成功的动作序列存储起来,以便在需要时快速调用。此外,论文还引入了潜意识降采样和模式增强学习策略,以提高操作效率。
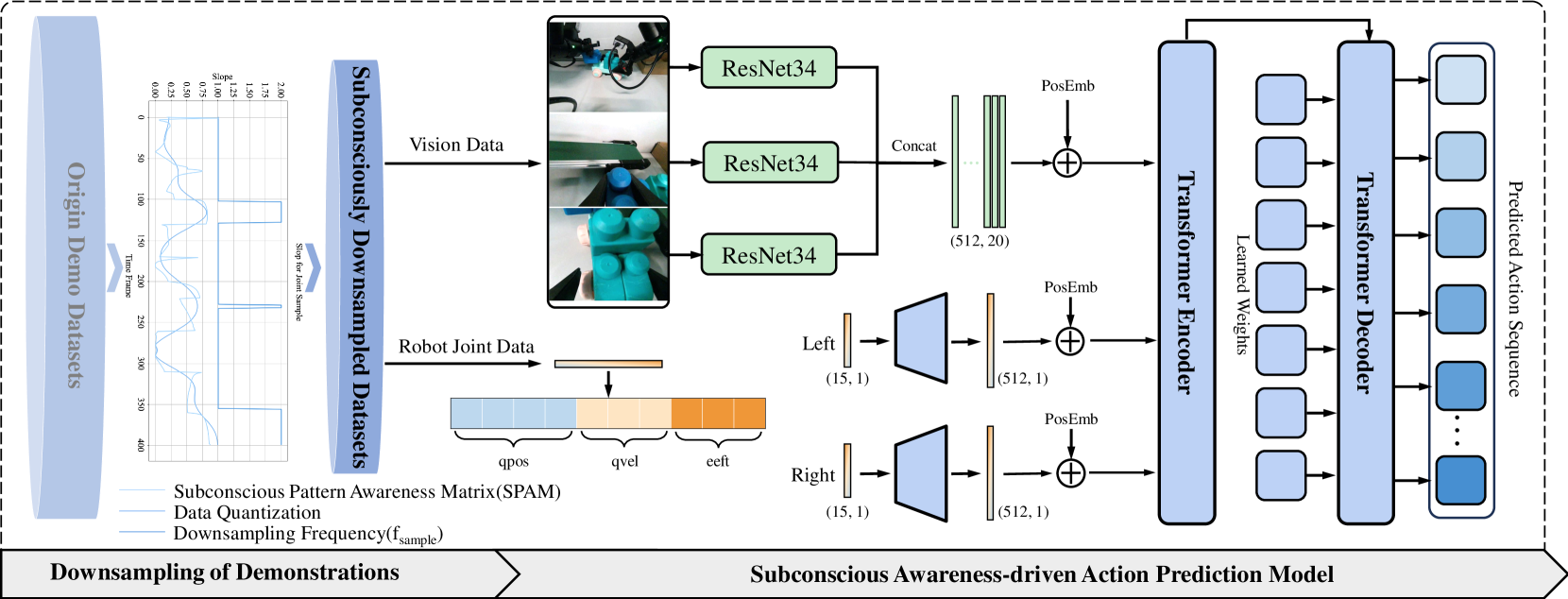
技术框架:SRIL的技术框架主要包含以下几个模块:1) 认知卸载模块:负责将一部分计算负担转移到离线处理。2) 历史动作分块模块:存储过去成功的动作序列,以便快速调用。3) 潜意识降采样模块:利用量化采样技术处理富含意图的信息,减少数据维度。4) 模式增强学习策略模块:通过增强学习来优化动作策略,提高操作效率。整体流程是,首先通过认知卸载和历史动作分块来减少模型推理延迟,然后利用潜意识降采样和模式增强学习策略来提高操作效率。
关键创新:该论文的关键创新在于将人类潜意识处理信息的方式引入到机器人模仿学习中。具体来说,通过认知卸载和历史动作分块来减少模型推理的延迟,并通过潜意识降采样和模式增强学习策略来提高操作效率。这种方法与现有方法的本质区别在于,它不是依赖于计算密集型的多模型轨迹预测,而是通过模仿人类潜意识的处理方式来提高执行速度和效率。
关键设计:论文中关于关键设计的具体细节描述较少,但可以推断出以下几点:1) 认知卸载策略:如何选择哪些计算负担可以转移到离线处理,以及如何保证离线处理的准确性。2) 历史动作分块策略:如何存储和检索历史动作序列,以及如何处理新的动作序列与历史动作序列之间的差异。3) 潜意识降采样策略:如何选择合适的量化采样技术,以及如何保证降采样后的数据仍然包含足够的信息。4) 模式增强学习策略:如何设计合适的奖励函数和状态空间,以及如何训练增强学习模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SRIL在全面的双臂任务中,执行速度比SOTA策略快100%到200%,并且成功率始终更高。这意味着SRIL能够显著提高机器人的操作效率和鲁棒性,使其能够更好地适应复杂环境。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
SRIL具有广泛的应用前景,例如在工业自动化、医疗机器人、家庭服务机器人等领域。它可以用于提高机器人在复杂环境中的操作效率和鲁棒性,例如在装配线上快速完成装配任务,在手术室中精确完成手术操作,在家庭环境中安全地完成家务任务。SRIL的未来发展方向包括进一步提高其泛化能力和适应性,使其能够适应更加复杂和动态的环境。
📄 摘要(原文)
Although robotic imitation learning (RIL) is promising for embodied intelligent robots, existing RIL approaches rely on computationally intensive multi-model trajectory predictions, resulting in slow execution and limited real-time responsiveness. Instead, human beings subconscious can constantly process and store vast amounts of information from their experiences, perceptions, and learning, allowing them to fulfill complex actions such as riding a bike, without consciously thinking about each. Inspired by this phenomenon in action neurology, we introduced subconscious robotic imitation learning (SRIL), wherein cognitive offloading was combined with historical action chunkings to reduce delays caused by model inferences, thereby accelerating task execution. This process was further enhanced by subconscious downsampling and pattern augmented learning policy wherein intent-rich information was addressed with quantized sampling techniques to improve manipulation efficiency. Experimental results demonstrated that execution speeds of the SRIL were 100\% to 200\% faster over SOTA policies for comprehensive dual-arm tasks, with consistently higher success rates.