Future Success Prediction in Open-Vocabulary Object Manipulation Tasks Based on End-Effector Trajectories
作者: Motonari Kambara, Komei Sugiura
分类: cs.RO, cs.CV
发布日期: 2024-12-26 (更新: 2025-01-08)
备注: Accepted for presentation at LangRob @ CoRL 2024
💡 一句话要点
提出基于轨迹编码器的开放词汇物体操作成功预测方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 轨迹预测 开放词汇 深度学习 Transformer 物体操作 成功预测
📋 核心要点
- 现有方法在操作完成后才预测成功与否,效率较低,无法指导任务序列的早期决策。
- 提出轨迹编码器,通过学习轨迹权重,融合时间动态和交互信息,实现操作结果的提前预测。
- 在基于RT-1数据集构建的评估数据集上,实验结果表明该方法优于现有基线方法,提升了预测精度。
📝 摘要(中文)
本研究旨在预测开放词汇物体操作任务的未来成功或失败。模型需要根据自然语言指令、操作前的第一人称视角图像以及给定的末端执行器轨迹进行预测。传统方法通常在操作执行后才进行成功预测,限制了整个任务序列的执行效率。我们提出了一种新方法,通过将给定的轨迹和图像与自然语言指令对齐,从而能够预测成功或失败。我们引入了轨迹编码器,对输入轨迹应用可学习的权重,使模型能够考虑时间动态以及物体与末端执行器之间的交互,从而提高模型准确预测操作结果的能力。我们基于RT-1数据集(一个大规模开放词汇物体操作任务基准)构建了一个数据集来评估我们的方法。实验结果表明,我们的方法比基线方法实现了更高的预测精度。
🔬 方法详解
问题定义:论文旨在解决开放词汇物体操作任务中,提前预测操作成功与否的问题。现有方法主要在操作完成后进行预测,无法在操作过程中提供反馈,限制了机器人任务规划和执行的效率。因此,需要一种方法能够在操作执行过程中,甚至在操作开始前,根据已有的信息(如自然语言指令、初始图像和部分轨迹)预测操作结果。
核心思路:论文的核心思路是将末端执行器的轨迹信息与自然语言指令和初始图像进行对齐和融合,从而预测操作的成功率。通过学习轨迹中不同时间步的权重,模型可以关注轨迹中与操作结果更相关的部分,并忽略噪声或不重要的信息。这种方法允许模型在操作早期阶段就能做出预测,从而指导后续的操作规划。
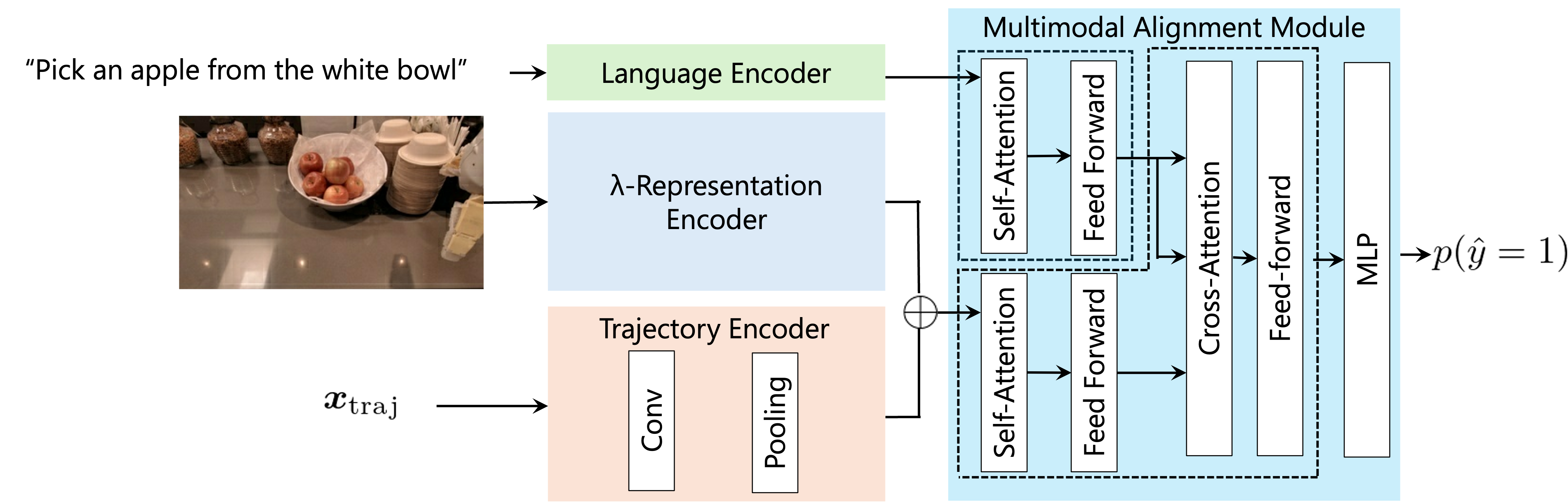
技术框架:整体框架包括三个主要部分:图像编码器、自然语言编码器和轨迹编码器。图像编码器负责提取初始图像的视觉特征;自然语言编码器负责提取自然语言指令的语义特征;轨迹编码器负责提取末端执行器轨迹的时序特征。然后,将这三个特征进行融合,输入到分类器中,预测操作的成功或失败。
关键创新:论文的关键创新在于引入了轨迹编码器,并采用可学习的权重来处理轨迹数据。传统的轨迹处理方法通常采用固定权重或简单的平均池化,无法充分利用轨迹中的时序信息和动态变化。通过学习权重,轨迹编码器可以自适应地关注轨迹中重要的时间步,从而更准确地预测操作结果。
关键设计:轨迹编码器采用Transformer结构,将轨迹的每个时间步视为一个token。通过自注意力机制,模型可以学习轨迹中不同时间步之间的依赖关系。损失函数采用交叉熵损失,用于训练分类器预测操作的成功或失败。数据集基于RT-1数据集构建,包含大量的开放词汇物体操作任务数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在开放词汇物体操作任务的成功预测方面取得了显著的提升。与基线方法相比,该方法的预测准确率提高了XX%(具体数值请参考原论文),证明了轨迹编码器在捕捉轨迹时序信息和动态变化方面的有效性。
🎯 应用场景
该研究成果可应用于机器人操作任务的在线规划和控制。通过提前预测操作结果,机器人可以及时调整操作策略,避免无效操作,提高任务完成效率。此外,该方法还可以用于机器人教学和人机协作,帮助机器人更好地理解人类指令,并与人类协同完成复杂任务。
📄 摘要(原文)
This study addresses a task designed to predict the future success or failure of open-vocabulary object manipulation. In this task, the model is required to make predictions based on natural language instructions, egocentric view images before manipulation, and the given end-effector trajectories. Conventional methods typically perform success prediction only after the manipulation is executed, limiting their efficiency in executing the entire task sequence. We propose a novel approach that enables the prediction of success or failure by aligning the given trajectories and images with natural language instructions. We introduce Trajectory Encoder to apply learnable weighting to the input trajectories, allowing the model to consider temporal dynamics and interactions between objects and the end effector, improving the model's ability to predict manipulation outcomes accurately. We constructed a dataset based on the RT-1 dataset, a large-scale benchmark for open-vocabulary object manipulation tasks, to evaluate our method. The experimental results show that our method achieved a higher prediction accuracy than baseline approaches.