Robustness Evaluation of Offline Reinforcement Learning for Robot Control Against Action Perturbations
作者: Shingo Ayabe, Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto
分类: cs.RO, cs.LG
发布日期: 2024-12-25 (更新: 2025-07-18)
备注: 22 pages, 6 figures
DOI: 10.1177/17298806251360454/
💡 一句话要点
评估离线强化学习在机器人控制中对抗动作扰动的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 机器人控制 鲁棒性评估 动作扰动 执行器故障
📋 核心要点
- 现有离线强化学习方法在机器人控制中,对真实世界中执行器故障等扰动的鲁棒性不足,限制了实际应用。
- 通过在机器人关节扭矩信号中引入随机和对抗性扰动,模拟真实场景中的执行器故障,评估离线强化学习算法的鲁棒性。
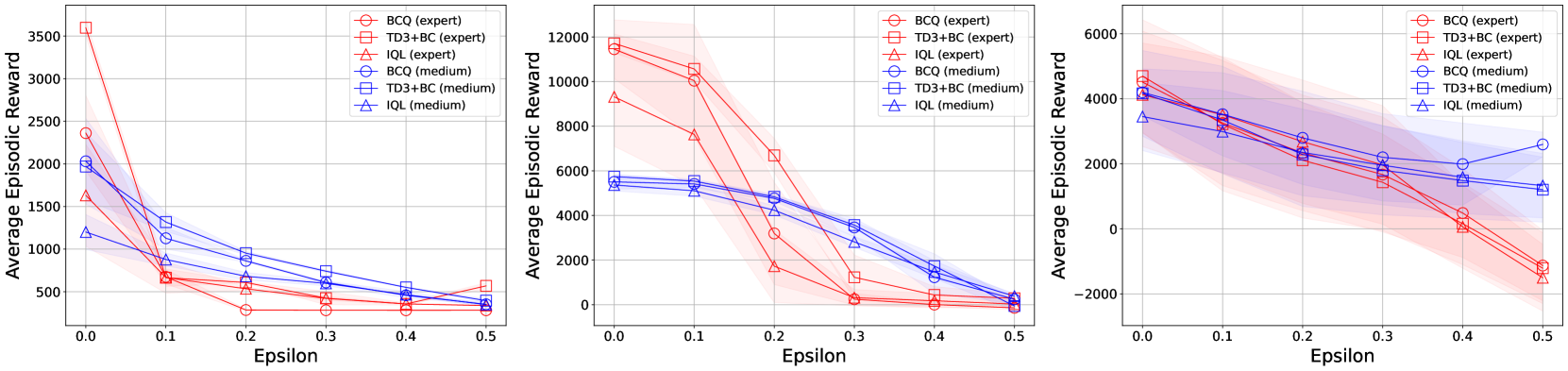
- 实验结果表明,现有离线强化学习方法对动作扰动非常敏感,其鲁棒性低于在线强化学习方法,需要进一步改进。
📝 摘要(中文)
离线强化学习(Offline RL)仅从数据集中学习,无需环境交互,受到了广泛关注。这种方法与传统的在线深度强化学习类似,在机器人控制应用中具有很大的潜力。然而,它在实际挑战中的鲁棒性,例如机器人关节执行器故障,仍然是一个关键问题。本研究基于平均 episodic rewards,评估了现有离线强化学习方法在使用 OpenAI Gym 的 legged robots 上的鲁棒性。为了进行鲁棒性评估,我们通过将随机和对抗性扰动(代表最坏情况)纳入关节扭矩信号来模拟故障。实验表明,现有的离线强化学习方法对这些动作扰动表现出明显的脆弱性,并且比在线强化学习方法更容易受到攻击,这突出了该领域需要更鲁棒的方法。
🔬 方法详解
问题定义:论文旨在评估离线强化学习算法在机器人控制任务中,面对动作扰动时的鲁棒性。现有离线强化学习方法虽然在模拟环境中表现良好,但在实际机器人应用中,由于执行器故障、传感器噪声等因素引起的动作扰动,会导致性能显著下降,甚至完全失效。因此,如何提高离线强化学习算法在真实环境中的鲁棒性是一个重要的研究问题。
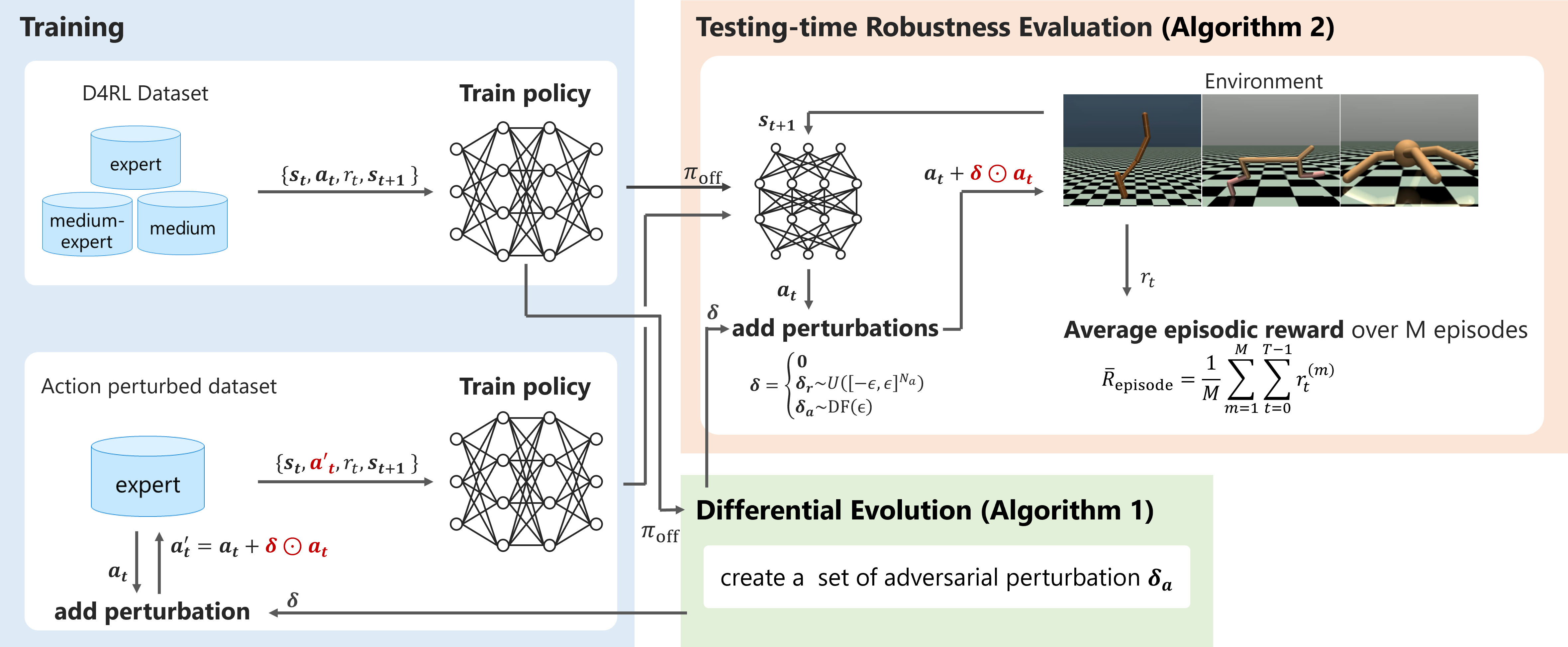
核心思路:论文的核心思路是通过模拟真实环境中的动作扰动,来评估现有离线强化学习算法的鲁棒性。具体来说,通过在机器人关节的扭矩信号中加入随机和对抗性的扰动,模拟执行器故障等情况,然后观察离线强化学习算法在这些扰动下的性能表现。通过这种方式,可以有效地评估算法的鲁棒性,并为后续改进提供指导。
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择合适的离线强化学习算法;2) 在 OpenAI Gym 的 legged robots 环境中训练离线策略;3) 在测试阶段,向机器人的关节扭矩信号中加入随机和对抗性的扰动;4) 评估离线策略在不同扰动下的性能表现,例如平均 episodic rewards。通过对比不同算法在不同扰动下的性能,可以评估它们的鲁棒性。
关键创新:论文的关键创新在于提出了一个评估离线强化学习算法鲁棒性的方法,该方法通过模拟真实环境中的动作扰动,可以有效地评估算法在实际应用中的性能。与传统的鲁棒性评估方法相比,该方法更加贴近实际应用场景,可以更好地反映算法的真实性能。此外,论文还对比了离线强化学习和在线强化学习算法在动作扰动下的表现,发现离线强化学习算法更容易受到扰动的影响。
关键设计:论文的关键设计包括:1) 扰动类型的选择:论文选择了随机扰动和对抗性扰动两种类型,分别代表了不同类型的执行器故障;2) 扰动强度的设置:论文通过调整扰动的强度,来模拟不同程度的执行器故障;3) 性能指标的选择:论文选择了平均 episodic rewards 作为性能指标,该指标可以有效地反映算法的整体性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的离线强化学习方法对动作扰动非常敏感,其鲁棒性低于在线强化学习方法。具体来说,在引入随机和对抗性扰动后,离线强化学习算法的平均 episodic rewards 显著下降,甚至接近于零。这表明,现有的离线强化学习方法在真实机器人应用中存在很大的风险,需要进一步改进。
🎯 应用场景
该研究成果可应用于各种机器人控制领域,尤其是在需要高可靠性和安全性的场景中,例如工业机器人、医疗机器人和自动驾驶汽车。通过提高离线强化学习算法的鲁棒性,可以减少因执行器故障等原因导致的意外事故,提高系统的安全性和可靠性。此外,该研究还可以促进离线强化学习算法在真实机器人系统中的应用。
📄 摘要(原文)
Offline reinforcement learning, which learns solely from datasets without environmental interaction, has gained attention. This approach, similar to traditional online deep reinforcement learning, is particularly promising for robot control applications. Nevertheless, its robustness against real-world challenges, such as joint actuator faults in robots, remains a critical concern. This study evaluates the robustness of existing offline reinforcement learning methods using legged robots from OpenAI Gym based on average episodic rewards. For robustness evaluation, we simulate failures by incorporating both random and adversarial perturbations, representing worst-case scenarios, into the joint torque signals. Our experiments show that existing offline reinforcement learning methods exhibit significant vulnerabilities to these action perturbations and are more vulnerable than online reinforcement learning methods, highlighting the need for more robust approaches in this field.