VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
作者: Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, Xipeng Qiu
分类: cs.RO, cs.AI, cs.CL, cs.CV
发布日期: 2024-12-24
💡 一句话要点
VLABench:一个用于长程推理语言条件机器人操作的大规模基准测试
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 语言条件控制 视觉-语言-动作模型 长程推理 基准测试
📋 核心要点
- 现有的机器人操作基准测试不足以满足视觉-语言-动作模型(VLAs)的需求,限制了通用机器人任务的学习。
- VLABench通过提供多样化的任务、自然语言指令、长程推理需求和综合能力评估,旨在推动VLA领域的研究。
- 实验结果表明,即使是最先进的VLA模型在VLABench上仍然面临挑战,突显了该基准测试的难度和价值。
📝 摘要(中文)
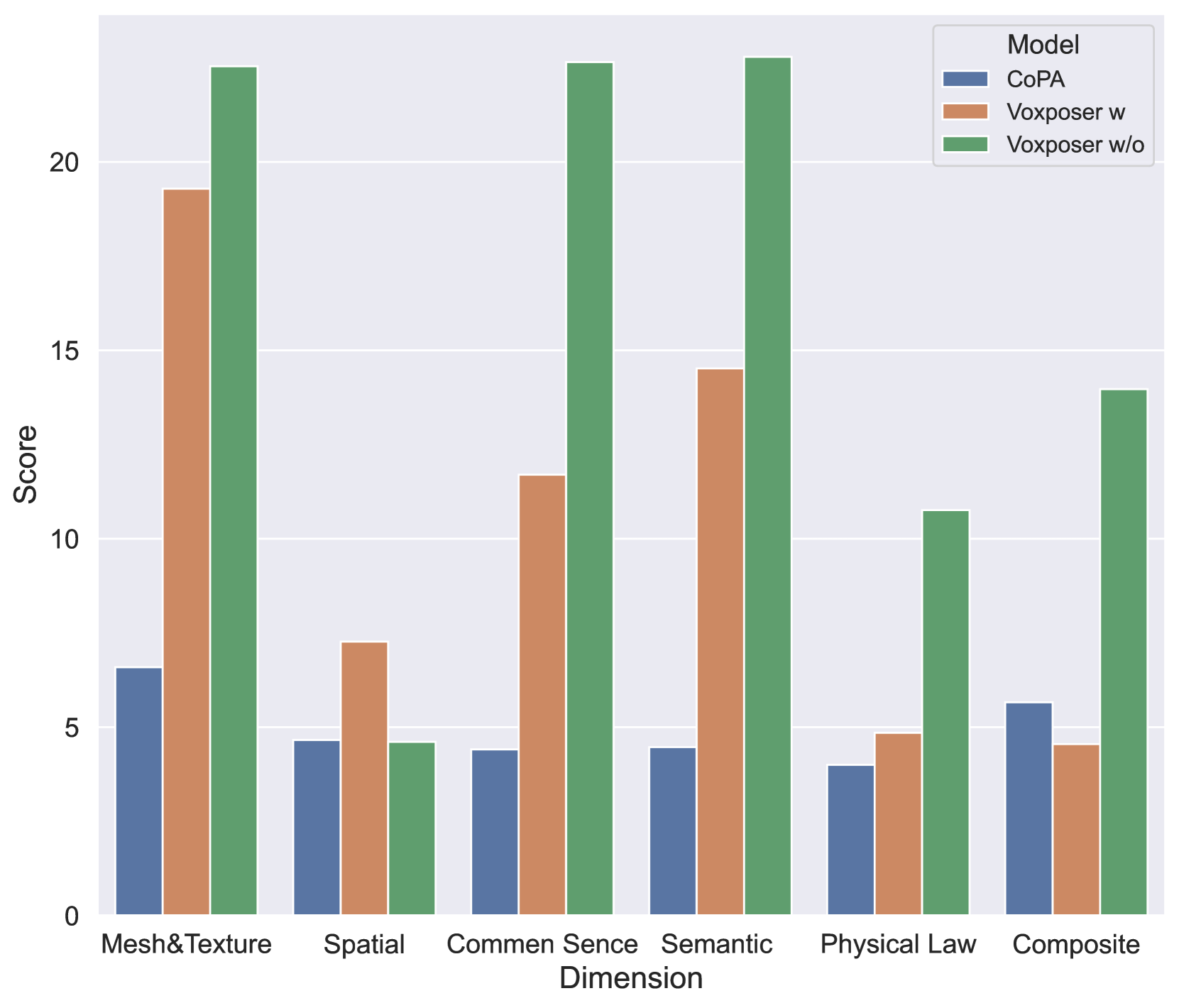
本文提出了VLABench,一个开源的基准测试,用于评估通用语言条件机器人操作(LCM)任务的学习。VLABench提供了100个精心设计的任务类别,每个类别都具有很强的随机性,总共包含2000多个对象。VLABench在四个关键方面优于以往的基准:1)需要世界知识和常识迁移的任务;2)具有隐含人类意图的自然语言指令,而非模板;3)需要多步骤推理的长程任务;4)评估动作策略和语言模型的能力。该基准评估多种能力,包括对网格和纹理、空间关系、语义指令、物理定律、知识迁移和推理等的理解。为了支持下游微调,我们提供通过自动化框架收集的高质量训练数据,该框架结合了启发式技能和先验信息。实验结果表明,当前最先进的预训练视觉-语言-动作模型(VLAs)和基于视觉-语言模型的流程在我们的任务中都面临挑战。
🔬 方法详解
问题定义:现有语言条件机器人操作(LCM)基准测试在任务多样性、指令自然度、推理长度和评估能力方面存在不足。具体来说,它们缺乏对世界知识和常识迁移的测试,使用模板化的指令而非自然语言,任务通常是短视的,并且没有全面评估语言模型的能力。这些限制阻碍了通用机器人智能的发展。
核心思路:VLABench的核心思路是创建一个大规模、多样化、具有挑战性的LCM基准测试,以推动VLA模型的发展。通过精心设计的任务类别、自然语言指令、长程推理需求和综合能力评估,VLABench旨在更好地定义通用任务,并促进VLA领域的研究。
技术框架:VLABench包含100个任务类别,每个类别都具有很强的随机性,总共包含2000多个对象。该基准测试提供了一个自动化框架,用于收集高质量的训练数据,该框架结合了启发式技能和先验信息。评估过程包括对动作策略和语言模型能力的评估,涵盖了对网格和纹理、空间关系、语义指令、物理定律、知识迁移和推理等多种能力的评估。
关键创新:VLABench的关键创新在于其综合性地考虑了LCM任务的各个方面,包括任务多样性、指令自然度、推理长度和评估能力。与现有基准测试相比,VLABench更具挑战性,更贴近实际应用场景,并且能够更全面地评估VLA模型的能力。
关键设计:VLABench的任务设计侧重于需要世界知识和常识迁移、自然语言指令、长程推理的任务。训练数据的收集采用自动化框架,结合了启发式技能和先验信息,以保证数据的质量和多样性。评估指标涵盖了动作策略的成功率和语言模型对指令的理解程度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最先进的预训练VLA模型和基于VLM的工作流程在VLABench上仍然面临挑战。这表明VLABench是一个具有挑战性的基准测试,能够有效地评估VLA模型的能力。该基准测试的发布将促进VLA领域的研究,并推动通用机器人智能的发展。
🎯 应用场景
VLABench可用于训练和评估各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。该基准测试能够推动通用机器人智能的发展,使机器人能够更好地理解人类的指令和意图,从而更有效地完成各种任务。未来的研究可以利用VLABench来开发更强大的VLA模型,并探索新的机器人学习方法。
📄 摘要(原文)
General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.