LMV-RPA: Large Model Voting-based Robotic Process Automation
作者: Osama Abdellatif, Ahmed Ayman, Ali Hamdi
分类: cs.RO, cs.AI, cs.SE
发布日期: 2024-12-23 (更新: 2025-04-28)
备注: 12 pages, 1 figures, 1 algorithm
💡 一句话要点
LMV-RPA:基于大模型投票的RPA系统,提升OCR准确率和效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OCR 机器人流程自动化 大型语言模型 集成学习 文档处理
📋 核心要点
- 现有OCR技术在处理复杂布局和模糊文本时面临准确性和效率的挑战,尤其是在大规模任务中。
- LMV-RPA通过集成多种OCR引擎和大型语言模型,利用多数投票机制提高OCR结果的准确性和可靠性。
- 实验结果表明,LMV-RPA在OCR准确率上达到99%,相比基线模型提升了5%,同时处理时间减少了80%。
📝 摘要(中文)
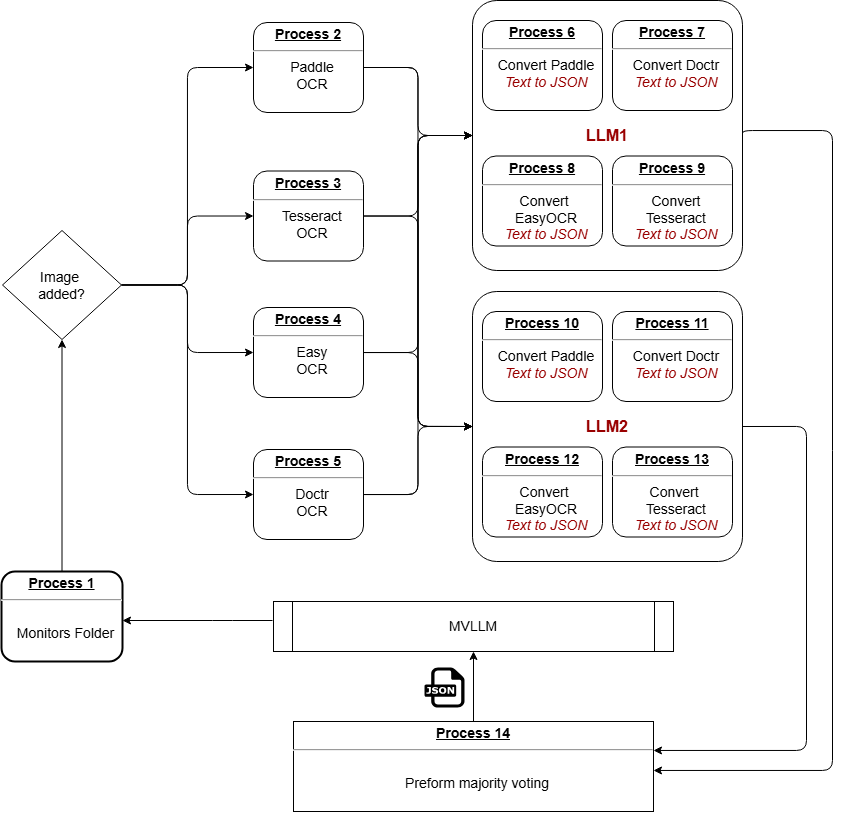
本文提出了一种基于大模型投票的机器人流程自动化系统LMV-RPA,旨在提升OCR工作流程的效率和准确性。该系统集成了Paddle OCR、Tesseract OCR、Easy OCR和DocTR等多种OCR引擎的输出,并结合LLaMA 3和Gemini-1.5-pro等大型语言模型,利用多数投票机制将OCR结果处理成结构化的JSON格式,从而提高在复杂布局下的准确性。该多阶段流程通过LLM处理OCR引擎提取的文本,并结合结果以确保最准确的输出。基准评估表明,LMV-RPA在OCR任务中达到了99%的准确率,超过了基线模型的94%,同时处理时间减少了80%,为大规模文档处理任务提供了一种更快、更可靠、更高效的自动化解决方案。
🔬 方法详解
问题定义:论文旨在解决大规模非结构化数据处理中,传统OCR技术在复杂布局和模糊文本识别方面存在的准确率和效率瓶颈。现有方法难以兼顾速度和精度,导致自动化流程效率低下。
核心思路:论文的核心思路是利用集成学习的思想,通过融合多个OCR引擎和大型语言模型的输出,并采用多数投票机制,来提高最终OCR结果的准确性和鲁棒性。这种方法能够有效降低单个OCR引擎的误差对整体性能的影响。
技术框架:LMV-RPA系统包含以下主要阶段:1) 多种OCR引擎并行提取文本;2) 大型语言模型对提取的文本进行处理和理解;3) 多数投票机制融合不同引擎和模型的输出;4) 将结果转化为结构化的JSON格式。整个流程旨在提高准确率并减少处理时间。
关键创新:该方法最重要的创新点在于将多种OCR引擎与大型语言模型相结合,并使用多数投票机制进行结果融合。这种集成方法能够充分利用不同模型的优势,有效提高OCR的准确性和鲁棒性,尤其是在处理复杂文档布局时。
关键设计:具体的技术细节包括:选择合适的OCR引擎(Paddle OCR, Tesseract OCR, Easy OCR, DocTR)和大型语言模型(LLaMA 3, Gemini-1.5-pro);设计有效的投票策略,例如可以根据不同引擎的置信度进行加权投票;优化LLM的prompt,使其更好地理解和处理OCR结果;以及设计高效的数据结构来存储和处理中间结果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LMV-RPA在OCR任务中达到了99%的准确率,相比基线模型(94%)提升了5%。更重要的是,LMV-RPA将处理时间减少了80%,显著提高了大规模文档处理的效率。这些结果验证了LMV-RPA在准确性和效率方面的优势。
🎯 应用场景
LMV-RPA可广泛应用于金融、法律、医疗等领域的大规模文档处理自动化。例如,自动处理发票、合同、病历等文件,提取关键信息并进行结构化存储,从而提高工作效率,降低人工成本,并减少人为错误。该技术还有潜力应用于智能客服、知识图谱构建等领域。
📄 摘要(原文)
Automating high-volume unstructured data processing is essential for operational efficiency. Optical Character Recognition (OCR) is critical but often struggles with accuracy and efficiency in complex layouts and ambiguous text. These challenges are especially pronounced in large-scale tasks requiring both speed and precision. This paper introduces LMV-RPA, a Large Model Voting-based Robotic Process Automation system to enhance OCR workflows. LMV-RPA integrates outputs from OCR engines such as Paddle OCR, Tesseract OCR, Easy OCR, and DocTR with Large Language Models (LLMs) like LLaMA 3 and Gemini-1.5-pro. Using a majority voting mechanism, it processes OCR outputs into structured JSON formats, improving accuracy, particularly in complex layouts. The multi-phase pipeline processes text extracted by OCR engines through LLMs, combining results to ensure the most accurate outputs. LMV-RPA achieves 99 percent accuracy in OCR tasks, surpassing baseline models with 94 percent, while reducing processing time by 80 percent. Benchmark evaluations confirm its scalability and demonstrate that LMV-RPA offers a faster, more reliable, and efficient solution for automating large-scale document processing tasks.