Sampling-Based Constrained Motion Planning with Products of Experts
作者: Amirreza Razmjoo, Teng Xue, Suhan Shetty, Sylvain Calinon
分类: cs.RO
发布日期: 2024-12-23 (更新: 2026-01-15)
DOI: 10.1177/02783649251404955
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于专家乘积的采样约束运动规划方法,提升采样效率和性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 运动规划 模型预测控制 约束优化 专家乘积 张量链
📋 核心要点
- 传统基于采样的MPC方法在处理约束优化问题时,采样效率低,容易在边界累积样本。
- 论文提出一种基于专家乘积的project-then-sample策略,将优化和可行性问题解耦,提升采样效率。
- 实验表明,该方法在避障、非抓取操作等任务中优于现有基线,验证了其有效性。
📝 摘要(中文)
本文提出了一种新方法,通过利用专家乘积来增强基于采样的模型预测控制(MPC)在约束优化中的性能。该方法将主要问题分解为两个部分:一个侧重于最优性,另一个侧重于可行性。通过结合来自每个部分的解(表示为分布),我们应用专家乘积来实现一种project-then-sample策略。在该策略中,最优性分布被投影到可行区域中,从而实现更有效的采样。这种方法与传统的sample-then-project和简单的sample-then-reject方法形成对比,从而实现了更多样化的探索,并减少了样本在边界上的累积。我们展示了使用基于张量链的分布模型有效实现该原理,该模型的特点是非参数性、易于与任务级别的其他分布组合以及直接的采样技术。我们调整了现有的张量链模型以适应此目的,并通过在各种任务(包括避障、非抓取操作和涉及保持在受限体积中的任务)中的实验验证了该方法的有效性。实验结果表明,所提出的方法始终优于已知的基线,为该方法的有效性提供了强有力的经验支持。该项目的示例代码可在https://github.com/idiap/smpc_poe 获得。
🔬 方法详解
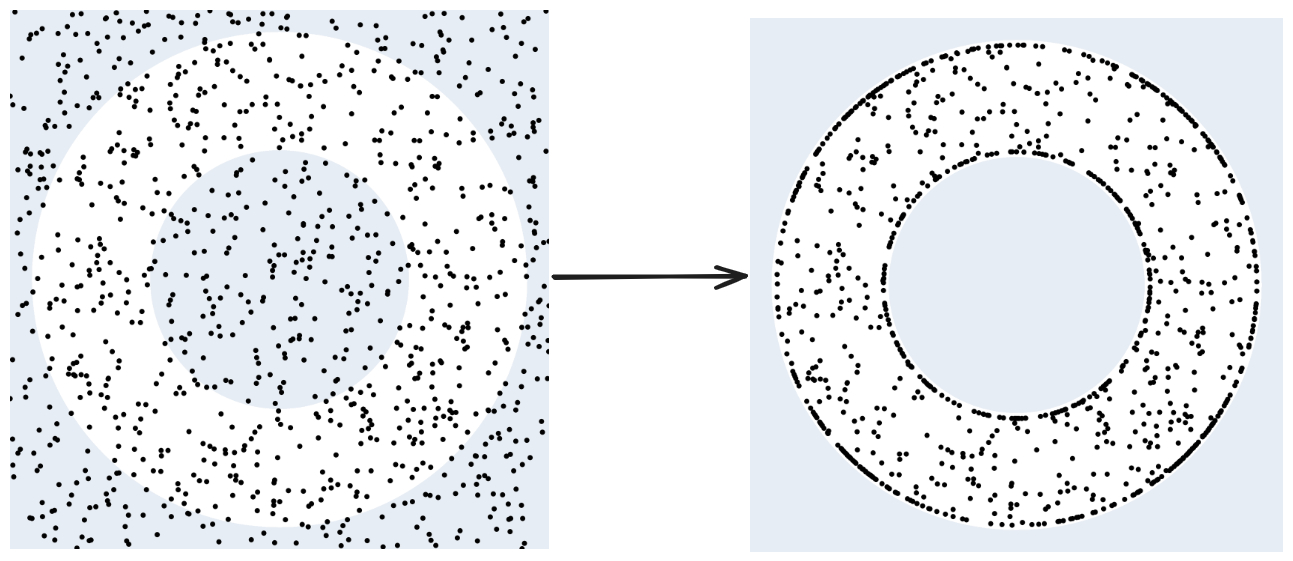
问题定义:论文旨在解决在约束条件下,基于采样的模型预测控制(MPC)方法采样效率低下的问题。传统方法如sample-then-project和sample-then-reject,要么效率低下,要么容易将样本集中在约束边界上,导致探索不足。
核心思路:核心思路是将优化问题分解为两个独立的专家:一个负责寻找最优解(不考虑约束),另一个负责保证解的可行性。然后,通过专家乘积(Product of Experts, PoE)将这两个专家的输出(概率分布)结合起来,得到一个既优化又可行的解的分布。这样,就可以先采样一个最优的解,然后将其投影到可行域中,从而提高采样效率。
技术框架:整体框架包含以下几个主要步骤:1) 将约束优化问题分解为最优性专家和可行性专家;2) 分别对两个专家建模,得到各自的概率分布;3) 使用专家乘积将两个分布结合,得到一个既优化又可行的分布;4) 从该分布中采样,得到控制序列;5) 将控制序列应用于系统,并重复以上步骤。论文使用张量链(Tensor Train, TT)模型来表示概率分布,因为它具有非参数性、易于组合以及采样方便的优点。
关键创新:关键创新在于使用专家乘积来实现project-then-sample策略。与传统的sample-then-project方法相比,该方法能够更有效地利用优化信息,避免了在不可行区域浪费采样点。与sample-then-reject方法相比,该方法能够更有效地探索可行区域,避免了样本在边界上的累积。此外,使用张量链模型来表示概率分布也使得该方法具有较好的可扩展性和灵活性。
关键设计:论文对现有的张量链模型进行了调整,使其更适合表示控制序列的概率分布。具体来说,论文可能涉及以下技术细节:如何选择张量链的秩(rank),如何训练张量链模型,如何计算专家乘积,以及如何从张量链模型中采样。此外,论文可能还涉及如何设计最优性专家和可行性专家,以及如何平衡它们之间的权重。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在避障、非抓取操作和受限体积内运动等任务中,均优于已知的基线方法。具体性能提升数据(例如,采样效率提升百分比、成功率提升百分比等)未知,但摘要明确指出该方法“始终优于已知的基线”,表明其具有显著的性能优势。
🎯 应用场景
该研究成果可广泛应用于机器人运动规划、自动驾驶、无人机控制等领域,尤其是在存在复杂约束的环境中。例如,在狭窄空间内的机器人操作、有障碍物的路径规划、以及需要保持在特定区域内的无人机飞行等场景。该方法能够提高采样效率,从而提升控制系统的实时性和鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
We present a novel approach to enhance the performance of sampling-based Model Predictive Control (MPC) in constrained optimization by leveraging products of experts. Our methodology divides the main problem into two components: one focused on optimality and the other on feasibility. By combining the solutions from each component, represented as distributions, we apply products of experts to implement a project-then-sample strategy. In this strategy, the optimality distribution is projected into the feasible area, allowing for more efficient sampling. This approach contrasts with the traditional sample-then-project and naive sample-then-reject method, leading to more diverse exploration and reducing the accumulation of samples on the boundaries. We demonstrate an effective implementation of this principle using a tensor train-based distribution model, which is characterized by its non-parametric nature, ease of combination with other distributions at the task level, and straightforward sampling technique. We adapt existing tensor train models to suit this purpose and validate the efficacy of our approach through experiments in various tasks, including obstacle avoidance, non-prehensile manipulation, and tasks involving staying in a restricted volume. Our experimental results demonstrate that the proposed method consistently outperforms known baselines, providing strong empirical support for its effectiveness. Sample codes for this project are available at https://github.com/idiap/smpc_poe.