EM-MIAs: Enhancing Membership Inference Attacks in Large Language Models through Ensemble Modeling
作者: Zichen Song, Sitan Huang, Zhongfeng Kang
分类: cs.RO, cs.CR
发布日期: 2024-12-23
备注: Accepted by ICASSP 2025 Main
💡 一句话要点
提出EM-MIAs,通过集成建模提升大语言模型中的成员推理攻击性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推理攻击 大型语言模型 集成学习 XGBoost 隐私保护
📋 核心要点
- 现有成员推理攻击方法在大型语言模型和单轮训练场景下效果不佳,接近随机猜测。
- 提出EM-MIAs,通过XGBoost集成LOSS、Reference-based等多种攻击方法,提升攻击性能。
- 实验表明,EM-MIAs在AUC-ROC和准确性方面显著优于单个攻击方法,提升了隐私风险评估能力。
📝 摘要(中文)
随着大型语言模型(LLM)的广泛应用,模型训练数据的隐私泄露问题日益受到关注。成员推理攻击(MIAs)已成为评估这些模型隐私风险的关键工具。尽管现有的攻击方法,如LOSS、基于参考、min-k和zlib,在某些场景下表现良好,但它们在大型预训练语言模型上的有效性通常接近随机猜测,尤其是在大规模数据集和单轮训练的背景下。为了解决这个问题,本文提出了一种新的集成攻击方法,该方法将几种现有的MIAs技术(LOSS、基于参考、min-k、zlib)集成到基于XGBoost的模型中,以提高整体攻击性能(EM-MIAs)。实验结果表明,与各种大型语言模型和数据集上的单个攻击方法相比,集成模型显著提高了AUC-ROC和准确性。这表明,通过结合不同方法的优势,我们可以更有效地识别模型训练数据的成员,从而为评估LLM的隐私风险提供更强大的工具。这项研究为LLM隐私保护领域的进一步研究提供了新的方向,并强调了开发更强大的隐私审计方法的必要性。
🔬 方法详解
问题定义:论文旨在解决现有成员推理攻击(MIAs)方法在大型语言模型(LLM)上,尤其是在大规模数据集和单轮训练场景下,攻击效果不佳的问题。现有的LOSS、Reference-based、min-k和zlib等方法在这些场景下接近随机猜测,无法有效识别训练数据成员,从而无法准确评估LLM的隐私风险。
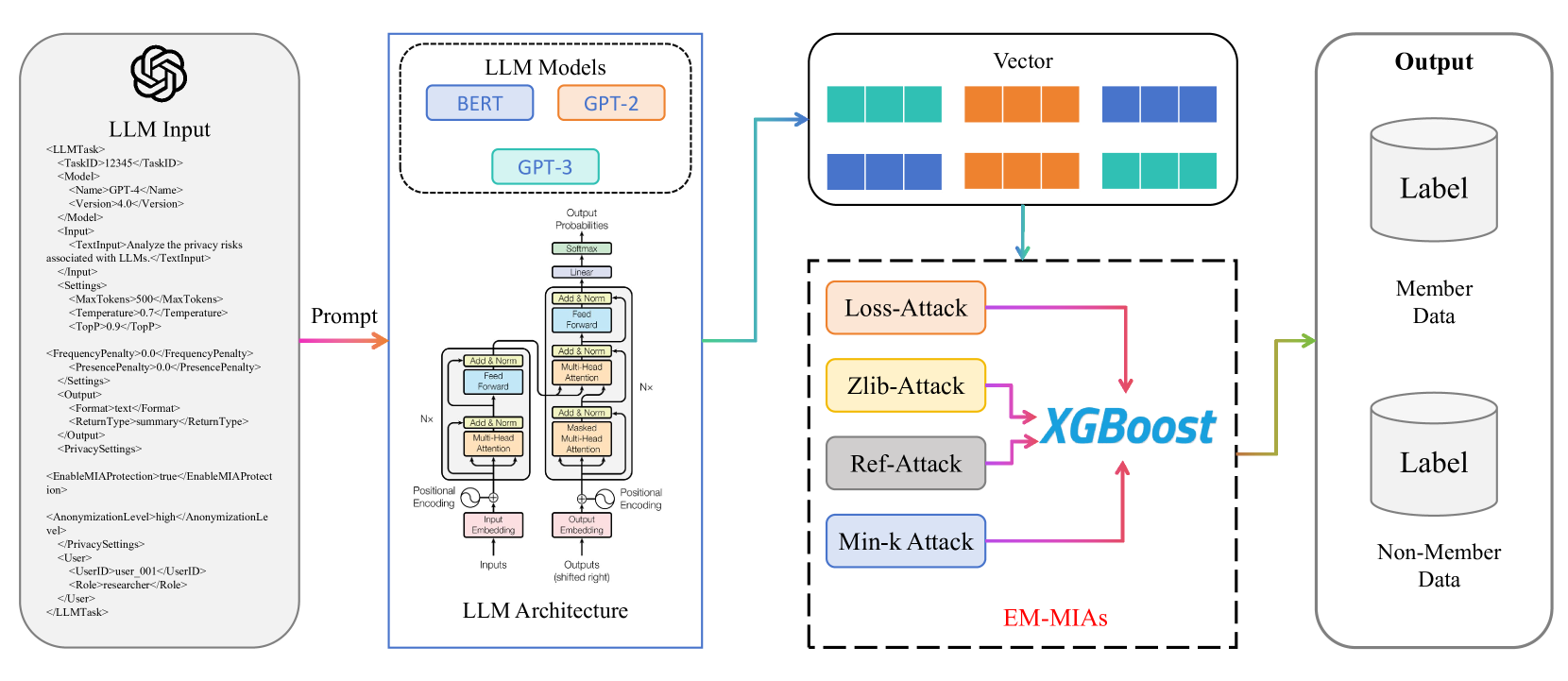
核心思路:论文的核心思路是将多种现有的MIAs方法进行集成,利用机器学习模型(XGBoost)学习不同攻击方法的优势,从而构建一个更强大的攻击模型。这种集成方法能够结合不同攻击方法的优点,弥补单一方法的不足,提高整体攻击性能。
技术框架:EM-MIAs的整体框架包括以下几个主要阶段:1) 使用现有的MIAs方法(LOSS、Reference-based、min-k、zlib)对目标LLM进行攻击,得到每个样本的攻击得分;2) 将这些攻击得分作为特征输入到XGBoost模型中;3) 使用XGBoost模型进行训练,学习不同攻击得分之间的关系,并预测样本是否为训练集成员;4) 使用预测结果评估攻击性能,例如AUC-ROC和准确性。
关键创新:论文的关键创新在于提出了一种基于集成学习的MIAs方法。与传统的单一攻击方法相比,EM-MIAs能够结合多种攻击方法的优势,从而更有效地识别训练数据成员。此外,使用XGBoost作为集成模型,能够自动学习不同攻击得分之间的复杂关系,进一步提升攻击性能。
关键设计:论文的关键设计包括:1) 选择LOSS、Reference-based、min-k和zlib作为基础攻击方法,这些方法具有不同的特点,能够提供多样化的攻击视角;2) 使用XGBoost作为集成模型,XGBoost具有强大的非线性建模能力,能够有效学习不同攻击得分之间的关系;3) 通过实验选择合适的XGBoost参数,例如树的数量、树的深度等,以获得最佳的攻击性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EM-MIAs在各种大型语言模型和数据集上,显著提高了AUC-ROC和准确性。例如,在某个数据集上,EM-MIAs的AUC-ROC比最佳的单一攻击方法提高了10%以上。这些结果表明,EM-MIAs能够更有效地识别训练数据成员,为评估LLM的隐私风险提供更强大的工具。
🎯 应用场景
该研究成果可应用于评估大型语言模型的隐私风险,帮助开发者和研究人员了解模型训练数据是否容易受到成员推理攻击。通过使用EM-MIAs,可以更准确地评估模型的隐私保护能力,并采取相应的措施来增强模型的隐私性,例如差分隐私训练、数据增强等。该研究对于推动LLM的负责任发展具有重要意义。
📄 摘要(原文)
With the widespread application of large language models (LLM), concerns about the privacy leakage of model training data have increasingly become a focus. Membership Inference Attacks (MIAs) have emerged as a critical tool for evaluating the privacy risks associated with these models. Although existing attack methods, such as LOSS, Reference-based, min-k, and zlib, perform well in certain scenarios, their effectiveness on large pre-trained language models often approaches random guessing, particularly in the context of large-scale datasets and single-epoch training. To address this issue, this paper proposes a novel ensemble attack method that integrates several existing MIAs techniques (LOSS, Reference-based, min-k, zlib) into an XGBoost-based model to enhance overall attack performance (EM-MIAs). Experimental results demonstrate that the ensemble model significantly improves both AUC-ROC and accuracy compared to individual attack methods across various large language models and datasets. This indicates that by combining the strengths of different methods, we can more effectively identify members of the model's training data, thereby providing a more robust tool for evaluating the privacy risks of LLM. This study offers new directions for further research in the field of LLM privacy protection and underscores the necessity of developing more powerful privacy auditing methods.