Dexterous Manipulation Based on Prior Dexterous Grasp Pose Knowledge
作者: Hengxu Yan, Haoshu Fang, Cewu Lu
分类: cs.RO, cs.LG
发布日期: 2024-12-20
💡 一句话要点
提出基于先验灵巧抓取姿态知识的强化学习方法,提升灵巧操作效率与精度
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧操作 强化学习 抓取姿态生成 机器人操作 先验知识
📋 核心要点
- 现有灵巧操作强化学习方法因机械手自由度高,存在学习效率低、准确性差的问题。
- 该方法将操作过程解耦为抓取姿态生成和强化学习探索两个阶段,利用先验知识引导学习。
- 实验表明,该方法显著提升了学习效率和操作成功率,尤其是在确定初始位置和操作视角方面。
📝 摘要(中文)
灵巧操作近年来受到了广泛关注。目前的研究主要集中在使用强化学习方法来解决机械手运动中大量的自由度问题。然而,这些方法通常效率和准确性较低。本文提出了一种新的强化学习方法,该方法利用先验的灵巧抓取姿态知识来提高效率和准确性。与以往总是让机械手采用固定的灵巧抓取姿态不同,我们将操作过程解耦为两个不同的阶段:首先,生成一个针对物体功能部分的灵巧抓取姿态;之后,我们采用强化学习来全面探索环境。我们的研究结果表明,大部分学习时间都花费在确定合适的初始位置和选择最佳的操作视角上。实验结果表明,在四个不同的任务中,学习效率和成功率都得到了显著提高。
🔬 方法详解
问题定义:论文旨在解决灵巧操作中,由于机械手自由度过高,导致强化学习方法训练效率低、操作成功率低的问题。现有方法通常采用固定的抓取姿态,限制了操作的灵活性和适应性。
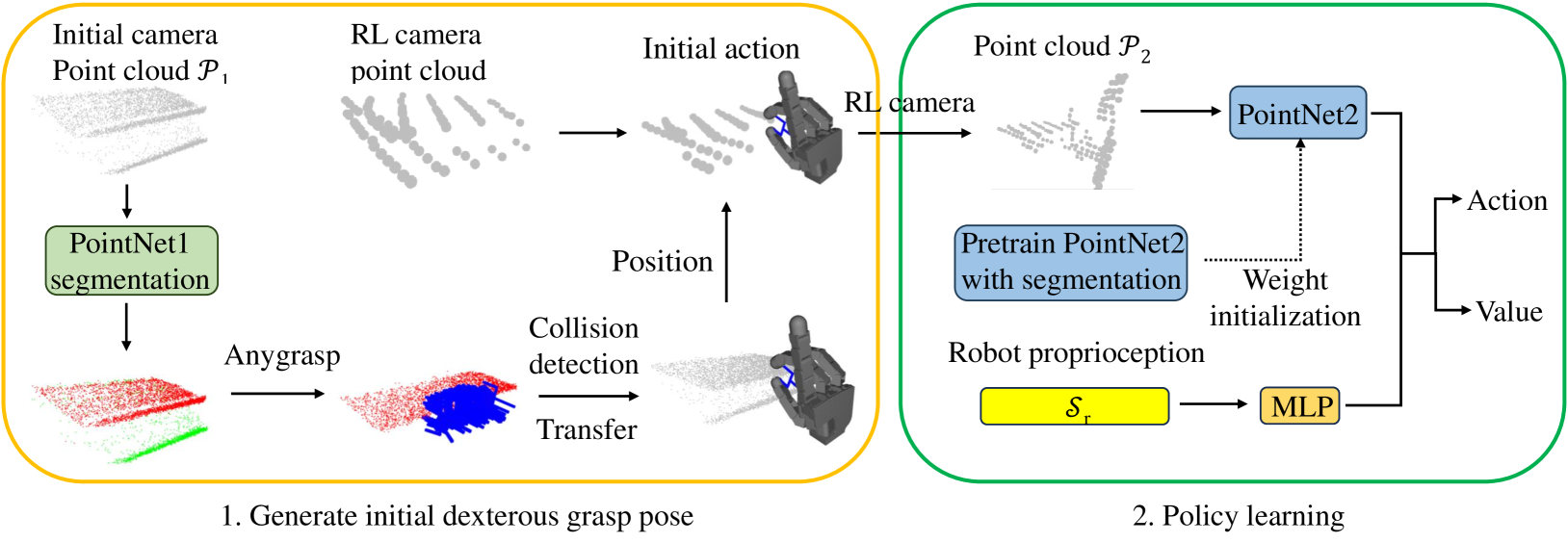
核心思路:论文的核心思路是将灵巧操作分解为两个阶段:首先,利用先验知识生成一个针对物体功能部分的灵巧抓取姿态;然后,使用强化学习方法在抓取姿态的基础上进行精细的操作调整和环境探索。这样可以有效缩小搜索空间,加速学习过程。
技术框架:整体框架包含两个主要阶段:1) 灵巧抓取姿态生成阶段:利用先验知识(例如物体形状、功能部件位置等)生成一个初始的抓取姿态,该姿态能够保证机械手能够稳定地抓取物体,并方便后续的操作。2) 强化学习探索阶段:在该阶段,使用强化学习算法(具体算法未知)对机械手的运动进行控制,使其能够完成特定的操作任务。强化学习的目标是学习一个策略,该策略能够根据当前的状态(例如机械手和物体的相对位置、物体的姿态等)选择合适的动作,从而实现操作目标。
关键创新:该方法最重要的创新点在于将灵巧操作分解为抓取姿态生成和强化学习探索两个阶段,并利用先验知识引导抓取姿态的生成。与现有方法相比,该方法能够更有效地利用先验知识,缩小搜索空间,提高学习效率和操作成功率。
关键设计:论文中关于抓取姿态生成和强化学习算法的具体细节未知。但是,可以推测,抓取姿态生成可能涉及到一些几何推理和运动学分析,以确保生成的姿态是可行的和稳定的。强化学习算法可能需要设计合适的奖励函数,以引导机械手完成特定的操作任务。此外,可能还需要一些技术手段来处理机械手和环境之间的交互,例如力/力矩控制、视觉反馈等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在四个不同的灵巧操作任务中,学习效率和成功率都得到了显著提高。具体提升幅度未知,但论文强调该方法能够更有效地利用先验知识,从而加速学习过程并提高操作的准确性。该方法尤其在确定合适的初始位置和选择最佳的操作视角方面表现出色。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的场景,例如:工业自动化中的精密装配、医疗机器人中的微创手术、家庭服务机器人中的物品整理等。通过提高灵巧操作的效率和精度,可以降低人工成本,提高生产效率,并拓展机器人的应用范围。
📄 摘要(原文)
Dexterous manipulation has received considerable attention in recent research. Predominantly, existing studies have concentrated on reinforcement learning methods to address the substantial degrees of freedom in hand movements. Nonetheless, these methods typically suffer from low efficiency and accuracy. In this work, we introduce a novel reinforcement learning approach that leverages prior dexterous grasp pose knowledge to enhance both efficiency and accuracy. Unlike previous work, they always make the robotic hand go with a fixed dexterous grasp pose, We decouple the manipulation process into two distinct phases: initially, we generate a dexterous grasp pose targeting the functional part of the object; after that, we employ reinforcement learning to comprehensively explore the environment. Our findings suggest that the majority of learning time is expended in identifying the appropriate initial position and selecting the optimal manipulation viewpoint. Experimental results demonstrate significant improvements in learning efficiency and success rates across four distinct tasks.