Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
作者: Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, Jiangmiao Pang
分类: cs.RO
发布日期: 2024-12-19
备注: Project page: https://nimolty.github.io/Seer/
🔗 代码/项目: GITHUB
💡 一句话要点
提出预测逆动力学模型PIDM,提升机器人操作任务中的可扩展学习能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 逆动力学模型 视觉预测 Transformer网络 端到端学习
📋 核心要点
- 现有机器人操作策略学习主要集中在行为克隆或视觉表征预训练,缺乏视觉与动作的有效闭环。
- PIDM通过预测视觉状态调节逆动力学模型来预测动作,实现视觉与动作的端到端闭环学习。
- Seer模型在大规模数据集上预训练,并在真实场景中微调,显著提升了泛化性和操作性能。
📝 摘要(中文)
本文提出了一种端到端的范式,称为预测逆动力学模型(PIDM),该模型通过预测的视觉状态来调节逆动力学模型,从而预测动作。通过闭环视觉和动作,端到端的PIDM可以成为一个更好的可扩展动作学习器。在实践中,我们使用Transformer来处理视觉状态和动作,并将该模型命名为Seer。Seer首先在大型机器人数据集(如DROID)上进行预训练,然后可以通过少量微调数据适应真实场景。由于大规模的端到端训练以及视觉和动作之间的协同作用,Seer在模拟和真实世界的实验中显著优于以前的方法。在LIBERO-LONG基准测试中,Seer取得了13%的改进,在CALVIN ABC-D中取得了21%的改进,在真实世界任务中取得了43%的改进。值得注意的是,Seer在CALVIN ABC-D基准测试中创造了新的state-of-the-art,平均长度达到4.28,并且在真实场景中,对于新颖物体、光照条件和高强度干扰下表现出卓越的泛化能力。代码和模型已在https://github.com/OpenRobotLab/Seer/上公开。
🔬 方法详解
问题定义:现有机器人操作策略学习方法,要么侧重于从大量机器人数据中进行行为克隆,要么侧重于利用大规模视觉数据集预训练表征或生成模型(即世界模型)来增强模型泛化能力。这些方法通常缺乏视觉和动作之间的有效闭环,限制了其可扩展性和泛化能力。
核心思路:本文的核心思路是建立一个端到端的模型,该模型能够根据预测的未来视觉状态来预测机器人应该采取的动作。通过使用逆动力学模型,该模型能够学习从期望的状态变化到所需动作的映射。这种闭环方法允许模型更好地理解视觉输入和动作之间的关系,从而提高其泛化能力和鲁棒性。
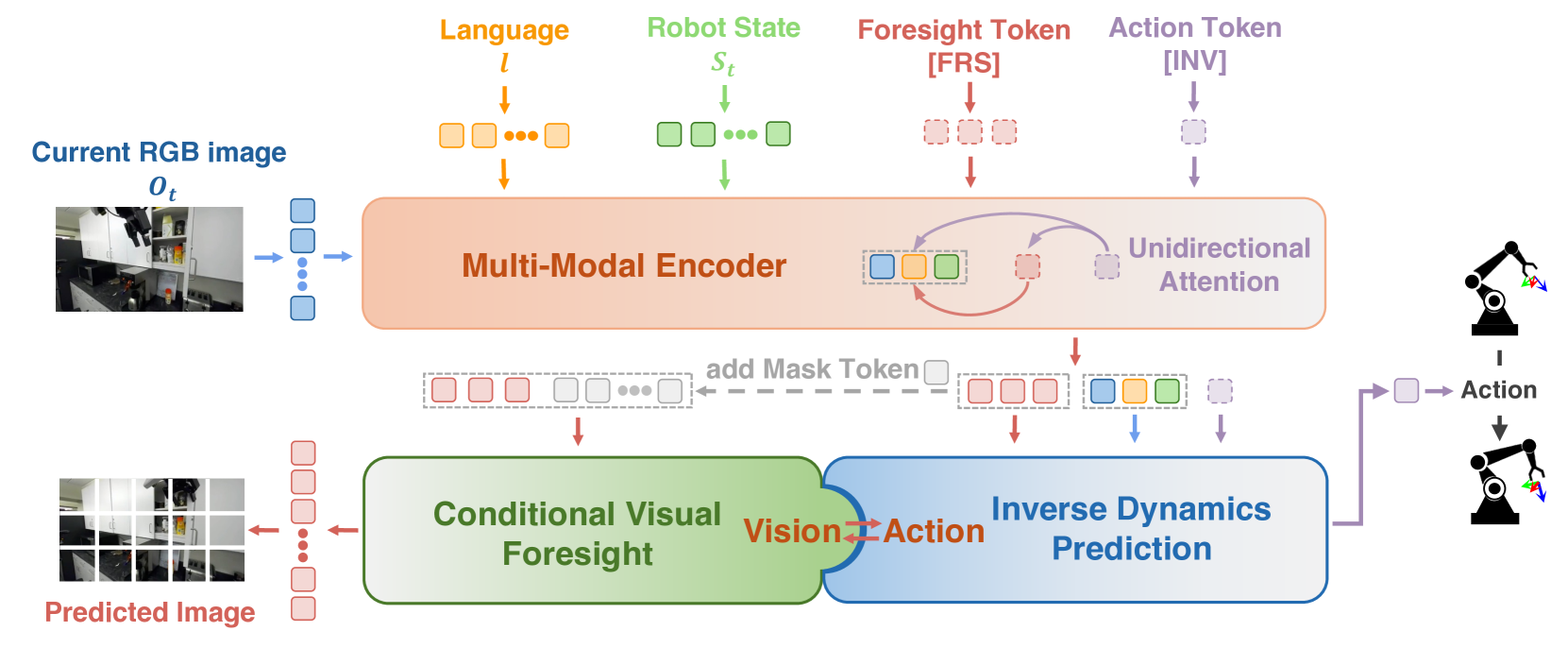
技术框架:PIDM模型的核心是一个Transformer网络(Seer),它接收机器人的当前视觉状态和历史动作作为输入,并预测未来的视觉状态。然后,一个逆动力学模型利用预测的未来视觉状态和当前状态来计算所需的动作。整个框架通过端到端的方式进行训练,以最小化预测的视觉状态和实际视觉状态之间的差异,以及预测的动作和实际动作之间的差异。主要模块包括:视觉编码器、Transformer预测器、逆动力学模型和动作解码器。
关键创新:PIDM的关键创新在于它将视觉预测和逆动力学控制结合在一个端到端的学习框架中。这种结合允许模型同时学习视觉表征和动作策略,从而提高了其泛化能力和鲁棒性。此外,使用Transformer网络作为预测器可以有效地捕捉视觉状态和动作之间的长期依赖关系。
关键设计:Seer模型使用Transformer作为核心架构,用于处理视觉状态和动作序列。视觉编码器将原始图像转换为低维特征向量。Transformer预测器使用多层自注意力机制来预测未来的视觉状态。逆动力学模型将预测的未来状态和当前状态作为输入,并输出所需的动作。损失函数包括视觉预测损失和动作预测损失。模型在大规模机器人数据集(如DROID)上进行预训练,然后在特定任务的数据集上进行微调。
🖼️ 关键图片
📊 实验亮点
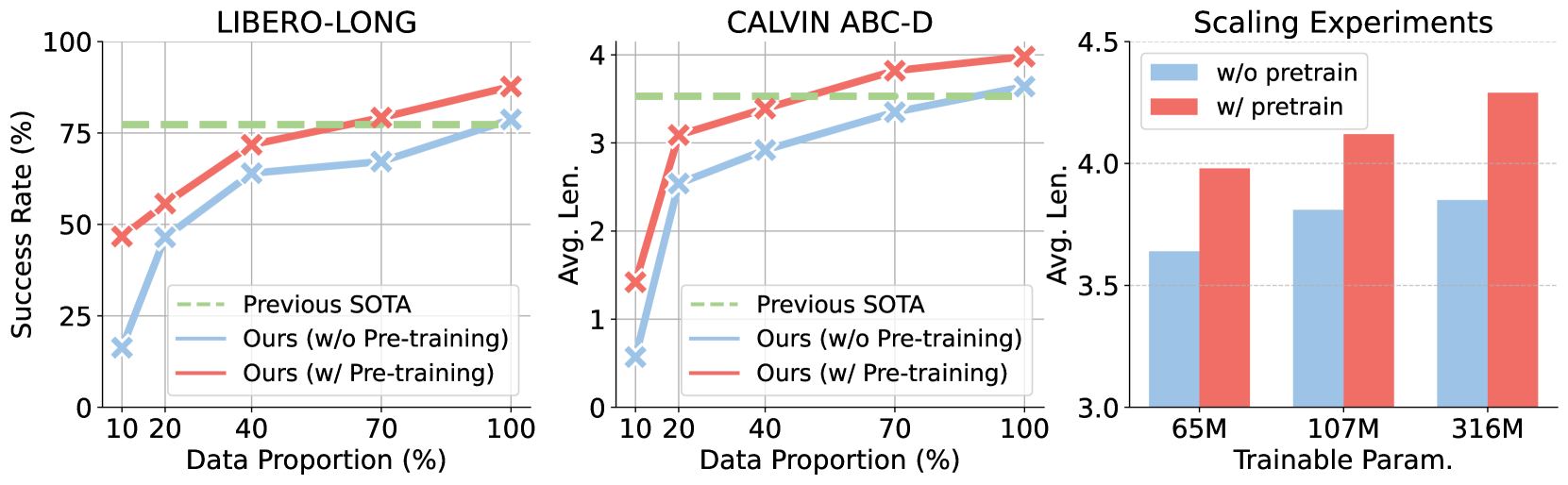
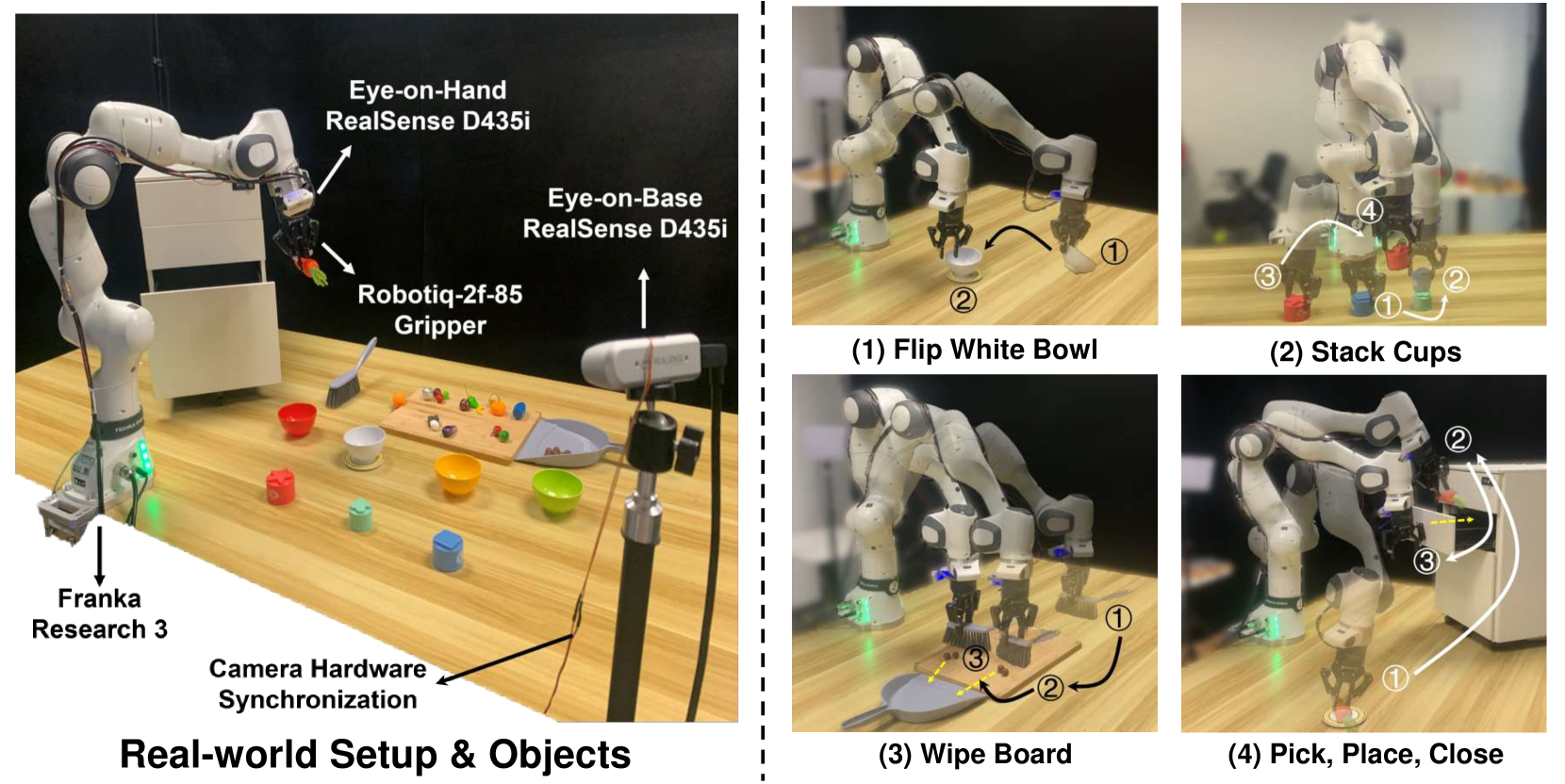
Seer模型在LIBERO-LONG基准测试中取得了13%的改进,在CALVIN ABC-D中取得了21%的改进,在真实世界任务中取得了43%的改进。特别是在CALVIN ABC-D基准测试中创造了新的state-of-the-art,平均长度达到4.28。此外,Seer在真实场景中,对于新颖物体、光照条件和高强度干扰下表现出卓越的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务,例如自动化装配、物流分拣、家庭服务机器人等。通过提升机器人的泛化能力和鲁棒性,可以使其更好地适应复杂和动态的真实世界环境,从而提高工作效率和安全性。未来,该方法有望应用于更复杂的机器人系统,例如多机器人协作和自主导航。
📄 摘要(原文)
Current efforts to learn scalable policies in robotic manipulation primarily fall into two categories: one focuses on "action," which involves behavior cloning from extensive collections of robotic data, while the other emphasizes "vision," enhancing model generalization by pre-training representations or generative models, also referred to as world models, using large-scale visual datasets. This paper presents an end-to-end paradigm that predicts actions using inverse dynamics models conditioned on the robot's forecasted visual states, named Predictive Inverse Dynamics Models (PIDM). By closing the loop between vision and action, the end-to-end PIDM can be a better scalable action learner. In practice, we use Transformers to process both visual states and actions, naming the model Seer. It is initially pre-trained on large-scale robotic datasets, such as DROID, and can be adapted to realworld scenarios with a little fine-tuning data. Thanks to large-scale, end-to-end training and the synergy between vision and action, Seer significantly outperforms previous methods across both simulation and real-world experiments. It achieves improvements of 13% on the LIBERO-LONG benchmark, 21% on CALVIN ABC-D, and 43% in real-world tasks. Notably, Seer sets a new state-of-the-art on CALVIN ABC-D benchmark, achieving an average length of 4.28, and exhibits superior generalization for novel objects, lighting conditions, and environments under high-intensity disturbances on real-world scenarios. Code and models are publicly available at https://github.com/OpenRobotLab/Seer/.