Implementing TD3 to train a Neural Network to fly a Quadcopter through an FPV Gate
作者: Patrick Thomas, Kevin Schroeder, Jonathan Black
分类: cs.RO, cs.LG
发布日期: 2024-12-18
💡 一句话要点
应用TD3算法训练神经网络,实现四旋翼飞行器通过FPV门
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 TD3算法 四旋翼飞行器 FPV导航 无人机控制
📋 核心要点
- 深度强化学习在求解最优解不明确的环境中展现出强大的策略开发能力。
- 本文采用TD3算法训练神经网络,控制四旋翼飞行器速度,使其能够穿越FPV门。
- 通过实验验证,训练后的策略能够成功引导无人机在真实环境中穿越目标门。
📝 摘要(中文)
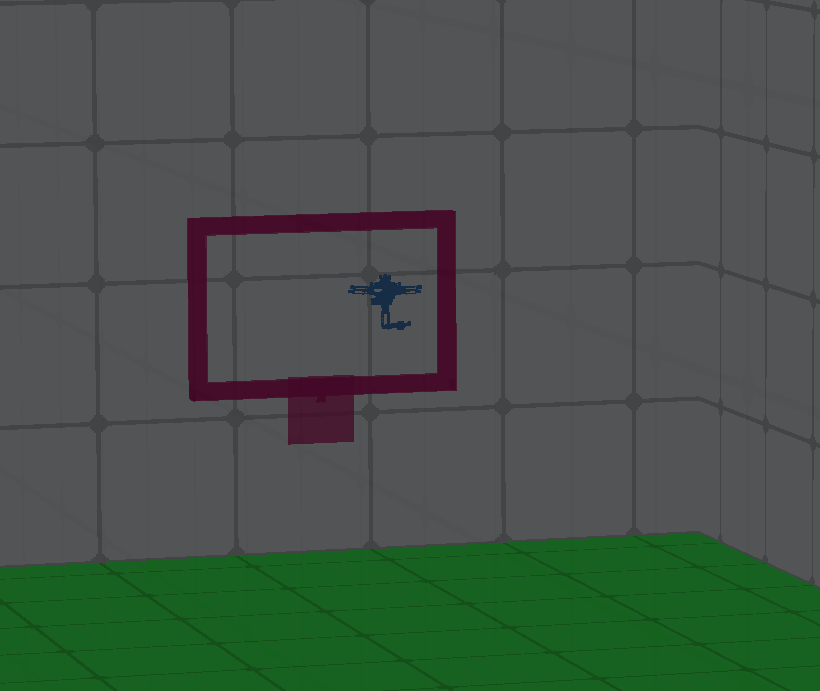
本文旨在使用Twin Delayed Deep Deterministic Policy Gradients (TD3) 算法训练一个神经网络,使其能够作为四旋翼飞行器的速度控制器。四旋翼飞行器的目标是快速飞过一个门,同时避免撞到门。通过在实验室环境中将训练好的策略部署到四旋翼飞行器上,我们将训练好的策略迁移到现实世界。最后,我们证明了训练好的策略能够在现实世界中引导无人机到达目标门。
🔬 方法详解
问题定义:现有方法在复杂环境下,难以精确控制四旋翼飞行器穿越FPV门,尤其是在存在环境干扰和模型不确定性的情况下,鲁棒性和泛化性不足。传统PID控制难以适应快速变化的环境,需要人工精细调参。
核心思路:利用TD3算法的优势,学习一个能够直接从视觉输入(FPV)到速度控制的策略。TD3通过引入双重评论家网络和延迟策略更新,能够有效抑制Q值过估计问题,提高训练的稳定性和策略的可靠性。
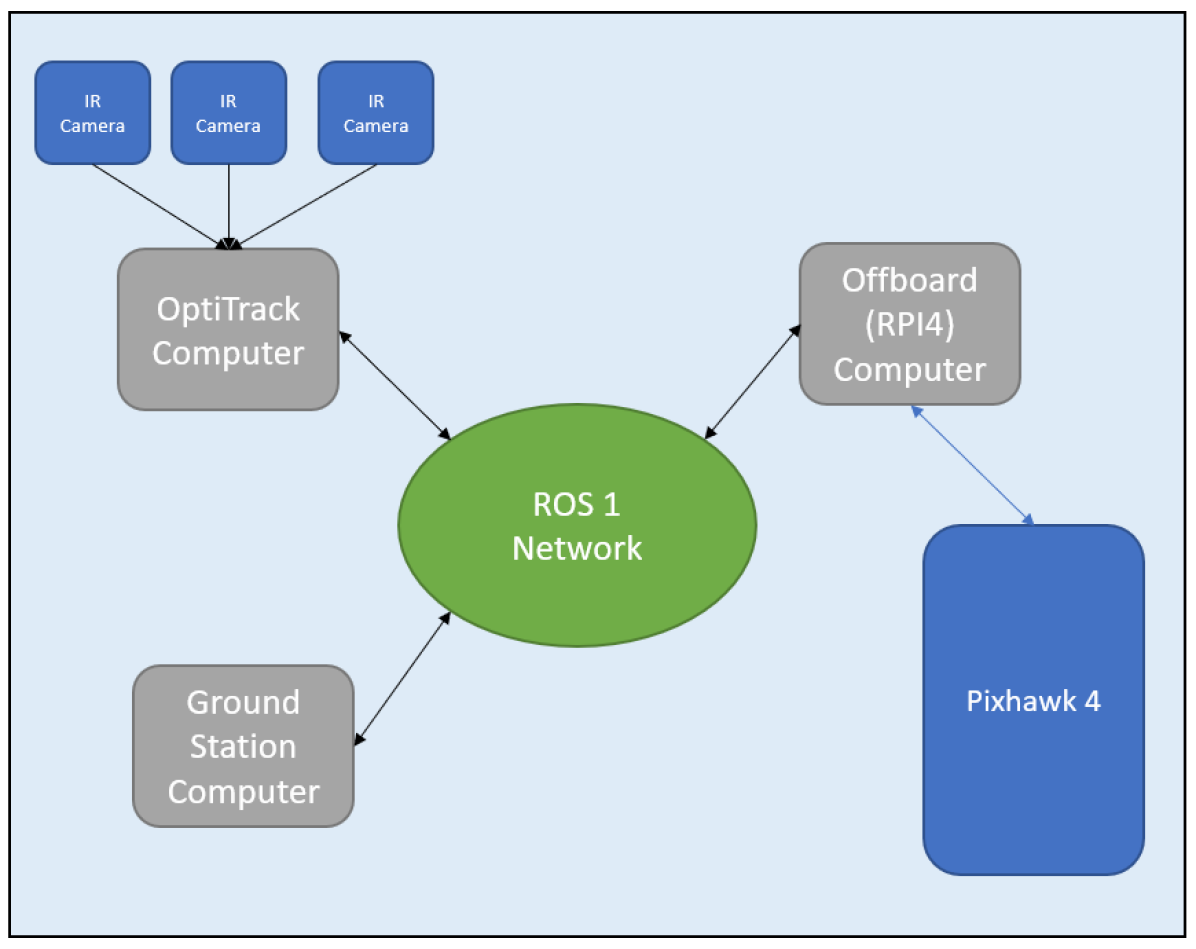
技术框架:整体框架包括环境模拟器(用于训练)和真实四旋翼飞行器平台(用于部署)。训练阶段,TD3算法与环境交互,学习最优策略。具体流程为:1)四旋翼飞行器通过FPV相机获取环境信息;2)神经网络(Actor)根据当前状态输出控制指令(速度);3)环境根据控制指令更新状态,并返回奖励;4)TD3算法利用状态、动作、奖励和下一个状态更新Actor和Critic网络。
关键创新:将TD3算法应用于四旋翼飞行器的速度控制,实现端到端的视觉导航。通过深度强化学习,无需人工设计复杂的控制规则,即可学习到适应环境的控制策略。TD3算法本身通过双重评论家网络和延迟策略更新,提高了训练的稳定性和策略的可靠性,降低了Q值过估计的风险。
关键设计:Actor网络和Critic网络均采用深度神经网络。状态输入包括FPV图像和四旋翼飞行器的当前速度。动作输出为四旋翼飞行器的速度控制指令。奖励函数的设计至关重要,包括引导无人机靠近门的奖励、避免碰撞的惩罚以及鼓励快速穿越的奖励。TD3算法的关键参数包括学习率、折扣因子、目标网络更新频率等,需要根据具体环境进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用TD3算法训练的神经网络能够成功引导四旋翼飞行器在真实环境中穿越FPV门。虽然论文中没有给出具体的性能数据,但强调了训练后的策略在真实环境中的有效性,证明了该方法具有良好的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于无人机自主导航、物流配送、安防巡检等领域。通过深度强化学习,无人机能够适应复杂环境,实现自主飞行和任务执行。未来,该技术有望应用于更广泛的机器人控制领域,例如自动驾驶、工业机器人等。
📄 摘要(原文)
Deep Reinforcement learning has shown to be a powerful tool for developing policies in environments where an optimal solution is unclear. In this paper, we attempt to apply Twin Delayed Deep Deterministic Policy Gradients to train a neural network to act as a velocity controller for a quadcopter. The quadcopter's objective is to quickly fly through a gate while avoiding crashing into the gate. We transfer our trained policy to the real world by deploying it on a quadcopter in a laboratory environment. Finally, we demonstrate that the trained policy is able to navigate the drone to the gate in the real world.