Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
作者: Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, Huaping Liu
分类: cs.RO, cs.CV
发布日期: 2024-12-18 (更新: 2024-12-24)
备注: Project page: robovlms.github.io. Added limitations and future works. Fix categorization
💡 一句话要点
构建通用机器人策略:探究视觉-语言-动作模型中的关键因素
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人策略 通用机器人 多模态学习 具身智能
📋 核心要点
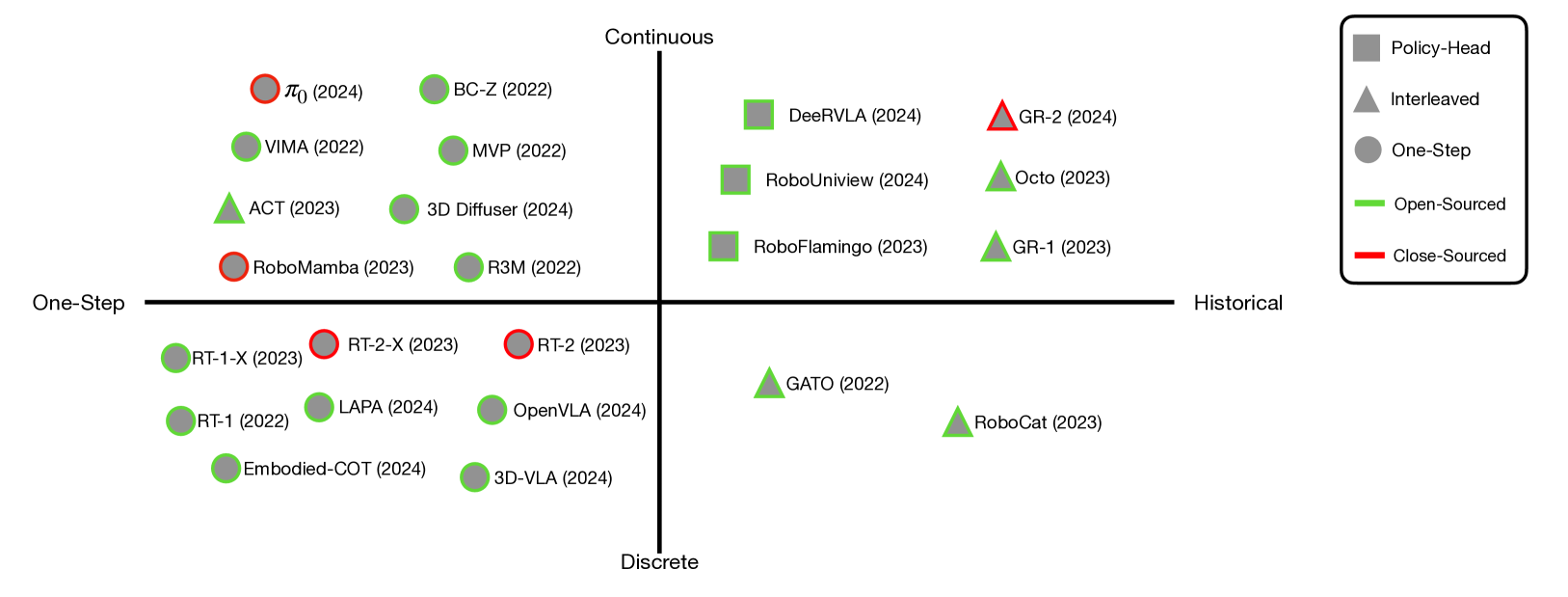
- 现有视觉-语言-动作模型(VLA)在骨干网络、动作预测方式和训练数据等方面差异较大,缺乏系统性的设计理解。
- 本文通过大量实验分析了VLA的关键设计因素,包括骨干网络选择、架构设计和跨环境数据的使用。
- 基于分析结果,提出了RoboVLM框架,在模拟和真实机器人任务中取得了新的state-of-the-art性能,并开源了代码和模型。
📝 摘要(中文)
基础视觉语言模型(VLM)在多模态表征学习、理解和推理方面表现出强大的能力。通过将动作组件注入到VLM中,可以自然地形成视觉-语言-动作模型(VLA),并显示出良好的性能。现有工作已经证明了VLA在多种场景和任务中的有效性和泛化性。然而,从VLM到VLA的迁移并非易事,因为现有的VLA在骨干网络、动作预测公式、数据分布和训练方法上存在差异。本文旨在系统地理解VLA的设计选择,揭示了显著影响VLA性能的关键因素,并重点关注三个基本设计选择:选择哪个骨干网络、如何构建VLA架构以及何时添加跨环境数据。实验结果表明,需要VLA并开发一种新的VLA系列,即RoboVLM,它只需要很少的人工设计,并在三个模拟任务和真实世界实验中实现了新的最先进的性能。通过包含超过8个VLM骨干网络、4个策略架构和超过600个不同设计的实验,为未来的VLA设计提供了详细的指南。此外,高度灵活的RoboVLMs框架支持轻松集成新的VLM和自由组合各种设计选择,并已公开发布,以促进未来的研究。我们开源了所有细节,包括代码、模型、数据集和工具包,以及详细的训练和评估方法。
🔬 方法详解
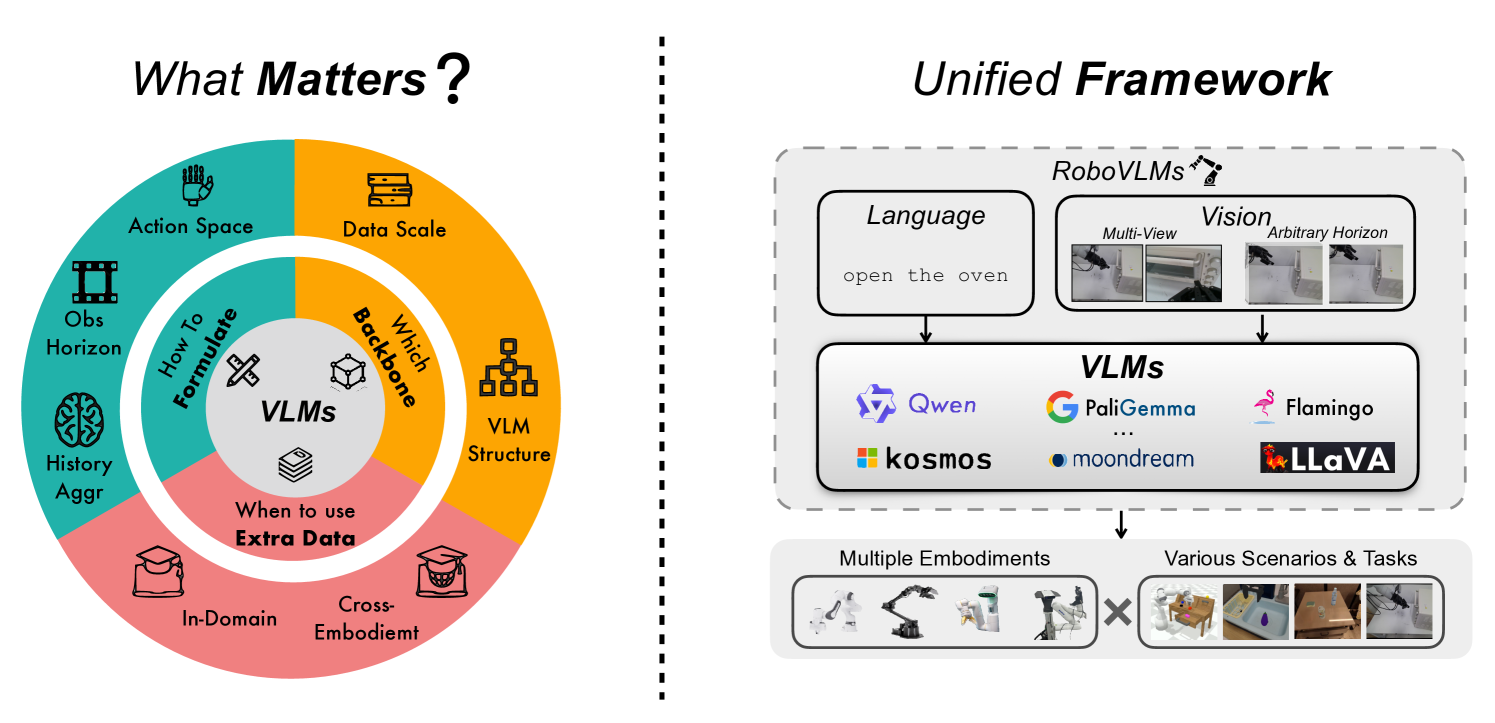
问题定义:现有视觉-语言-动作模型(VLA)的设计缺乏系统性的理解。不同的VLA模型在骨干网络、动作预测公式、数据分布和训练方法上存在显著差异,这使得难以确定哪些设计选择对性能至关重要。因此,需要深入研究VLA的设计空间,以指导未来更有效的VLA模型的开发。
核心思路:本文的核心思路是通过大规模的实验研究,系统地评估不同设计选择对VLA性能的影响。具体来说,作者们探索了不同的VLM骨干网络、VLA架构和跨环境数据的使用,并分析了它们对VLA在机器人任务中的表现的影响。基于这些分析,作者们提出了RoboVLM框架,该框架旨在简化VLA的设计过程,并实现更高的性能。
技术框架:RoboVLM框架的核心是利用预训练的视觉语言模型(VLM)作为骨干网络,并在此基础上添加动作预测模块。该框架支持灵活地选择不同的VLM骨干网络和动作预测架构。此外,RoboVLM框架还考虑了跨环境数据的使用,以提高VLA的泛化能力。整体流程包括:1)选择VLM骨干网络;2)设计动作预测模块;3)使用机器人数据集进行训练;4)在模拟或真实环境中进行评估。
关键创新:本文的关键创新在于对VLA设计空间的系统性探索和分析。通过大量的实验,作者们揭示了哪些设计选择对VLA的性能至关重要,并提出了RoboVLM框架,该框架旨在简化VLA的设计过程,并实现更高的性能。与现有方法相比,RoboVLM框架更加灵活和易于使用,并且在机器人任务中取得了更好的表现。
关键设计:在RoboVLM框架中,关键的设计包括:1)VLM骨干网络的选择,作者们探索了多种不同的VLM骨干网络,如CLIP、ViT等;2)动作预测模块的设计,作者们探索了不同的动作预测架构,如MLP、Transformer等;3)跨环境数据的使用,作者们使用了多种不同的机器人数据集,以提高VLA的泛化能力;4)训练方法,作者们使用了多种不同的训练方法,如监督学习、强化学习等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RoboVLM框架在三个模拟任务和真实世界实验中实现了新的state-of-the-art性能。通过对不同VLM骨干网络、VLA架构和跨环境数据的使用进行评估,作者们为未来的VLA设计提供了详细的指南。例如,实验表明,选择合适的VLM骨干网络和动作预测架构对VLA的性能至关重要。
🎯 应用场景
该研究成果可应用于各种机器人任务,例如物体抓取、导航、操作等。通过构建通用的机器人策略,可以降低机器人开发的成本和难度,并提高机器人的智能化水平。未来,该研究有望推动机器人技术在工业自动化、医疗健康、家庭服务等领域的广泛应用。
📄 摘要(原文)
Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.