Visual IRL for Human-Like Robotic Manipulation
作者: Ehsan Asali, Prashant Doshi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-12-16
💡 一句话要点
提出Visual IRL,使协作机器人在操作任务中学习并执行类人动作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 人机协作 机器人操作 视觉伺服 神经符号动力学
📋 核心要点
- 现有机器人操作方法难以模仿人类的自然动力学,导致人机协作效率低下。
- Visual IRL利用RGB-D关键点作为状态特征,通过逆强化学习学习人类操作的奖励函数,并迁移到机器人。
- 实验表明,该方法在农产品加工和液体倾倒任务中,实现了更类人化的机器人操作。
📝 摘要(中文)
本文提出了一种新颖的方法,使协作机器人(cobots)能够学习操作任务并以类人的方式执行。该方法属于从观察中学习(LfO)范例,机器人通过观察人类行为来学习执行任务,与从头开始编程相比,这有助于更快地集成到工业环境中。我们引入了Visual IRL,它直接使用观察到的人类任务执行的每一帧中的RGB-D关键点作为状态特征,输入到逆强化学习(IRL)。反向学习的奖励函数(将关键点映射到奖励值)使用一种新颖的神经符号动力学模型从人类转移到cobot,该模型将人类运动学映射到cobot手臂。该模型允许类似的末端执行器定位,同时最小化关节调整,旨在在机器人操作中保留人类运动的自然动力学。与先前仅关注末端执行器放置的技术相比,我们的方法将人类手臂的多个关节角度映射到相应的cobot关节。此外,它使用逆运动学模型来最小化关节角度的调整,以实现精确的末端执行器定位。我们在两个不同的实际操作任务中评估了这种方法的性能。第一个任务是农产品加工,包括根据洋葱是否有瑕疵来挑选、检查和放置洋葱。第二个任务是液体倾倒,机器人拿起瓶子,将内容物倒入指定的容器中,并处理空瓶子。我们的结果表明,类人机器人操作取得了进展,从而提高了制造应用中的人机兼容性。
🔬 方法详解
问题定义:现有机器人操作方法通常只关注末端执行器的精确位置,而忽略了人类操作的自然动力学和关节运动模式。这导致机器人动作僵硬、不自然,难以与人类协同工作。因此,需要一种方法使机器人能够学习并模仿人类的操作方式,从而提高人机协作的效率和安全性。
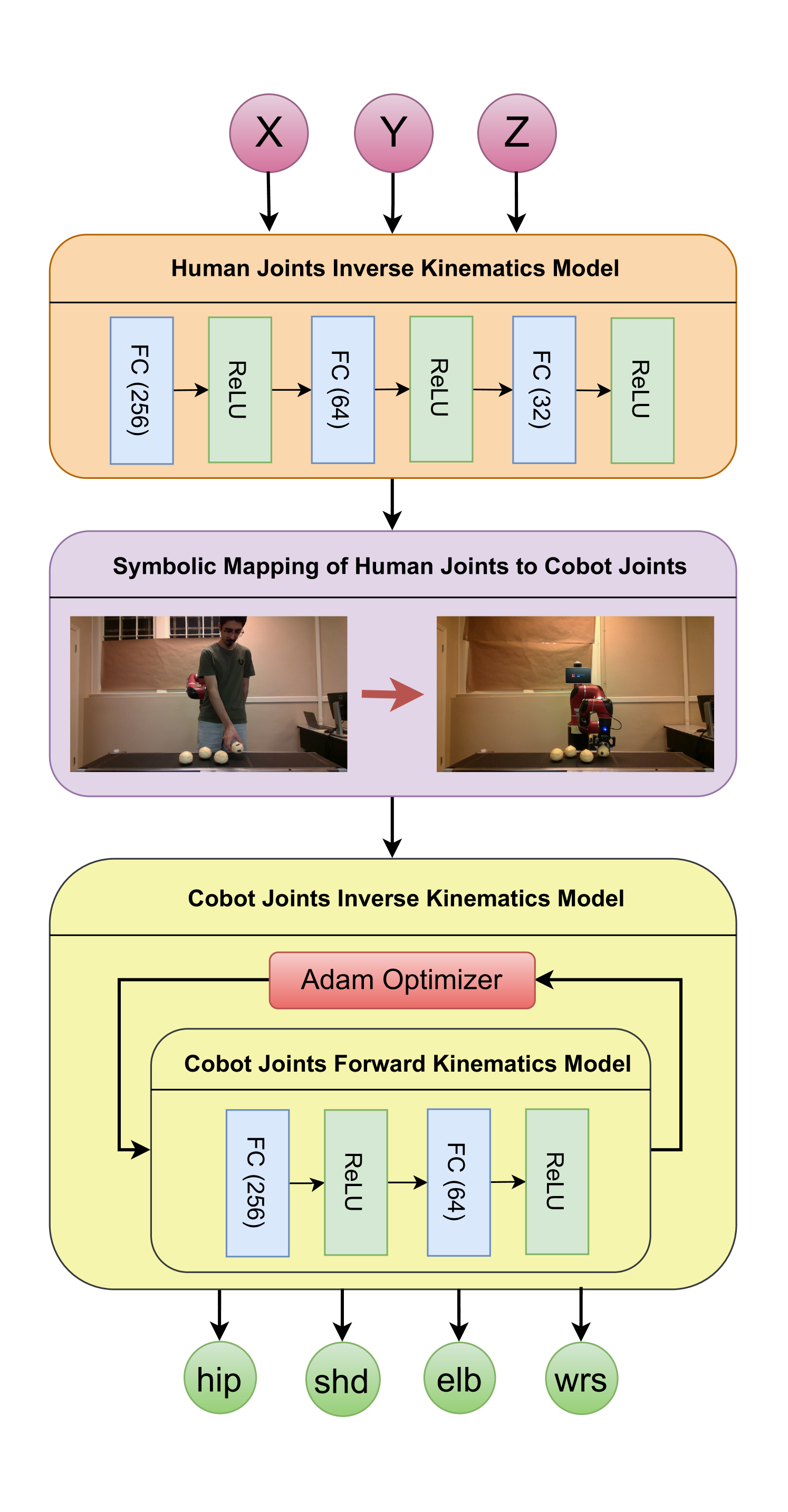
核心思路:本文的核心思路是利用逆强化学习(IRL)从人类的视觉演示中学习奖励函数,然后将该奖励函数迁移到机器人上,使机器人能够以类似人类的方式执行操作任务。通过直接使用RGB-D关键点作为状态特征,可以捕捉人类操作的视觉信息,并通过神经符号动力学模型将人类运动学映射到机器人手臂,从而实现类人化的动作。
技术框架:该方法主要包含以下几个阶段:1) 人类演示数据采集:使用RGB-D相机记录人类执行操作任务的视频,并提取每一帧中的关键点。2) 逆强化学习:使用提取的关键点作为状态特征,通过逆强化学习算法学习人类操作的奖励函数。3) 神经符号动力学模型:构建一个神经符号动力学模型,将人类手臂的关节角度映射到机器人手臂的关节角度。4) 机器人控制:使用学习到的奖励函数和神经符号动力学模型,控制机器人执行操作任务。
关键创新:该方法最重要的技术创新点在于:1) Visual IRL:直接使用RGB-D关键点作为状态特征,避免了手动设计特征的复杂性。2) 神经符号动力学模型:该模型能够将人类运动学映射到机器人手臂,同时最小化关节调整,从而保留人类运动的自然动力学。3) 多关节映射:与以往只关注末端执行器位置的方法不同,该方法将人类手臂的多个关节角度映射到相应的机器人关节。
关键设计:在逆强化学习中,使用了最大熵IRL算法来学习奖励函数。神经符号动力学模型包含一个神经网络和一个符号模型,神经网络用于学习人类和机器人之间的关节角度映射关系,符号模型用于进行逆运动学计算,以确保末端执行器的精确位置。损失函数包括奖励最大化项、关节角度差异最小化项和末端执行器位置误差最小化项。
🖼️ 关键图片


📊 实验亮点
在农产品加工任务中,该方法能够使机器人以更接近人类的方式挑选和放置洋葱,减少了对洋葱的损伤。在液体倾倒任务中,机器人能够平稳地倾倒液体,避免了溢出。与传统的机器人控制方法相比,该方法能够显著提高机器人操作的自然性和流畅性,从而提高了人机协作的效率。
🎯 应用场景
该研究成果可广泛应用于各种人机协作的制造场景,例如:自动化装配线、食品加工、医疗手术等。通过使机器人能够模仿人类的操作方式,可以提高生产效率、降低劳动强度,并改善人机协作的安全性。此外,该方法还可以应用于机器人辅助康复训练等领域,帮助患者恢复运动能力。
📄 摘要(原文)
We present a novel method for collaborative robots (cobots) to learn manipulation tasks and perform them in a human-like manner. Our method falls under the learn-from-observation (LfO) paradigm, where robots learn to perform tasks by observing human actions, which facilitates quicker integration into industrial settings compared to programming from scratch. We introduce Visual IRL that uses the RGB-D keypoints in each frame of the observed human task performance directly as state features, which are input to inverse reinforcement learning (IRL). The inversely learned reward function, which maps keypoints to reward values, is transferred from the human to the cobot using a novel neuro-symbolic dynamics model, which maps human kinematics to the cobot arm. This model allows similar end-effector positioning while minimizing joint adjustments, aiming to preserve the natural dynamics of human motion in robotic manipulation. In contrast with previous techniques that focus on end-effector placement only, our method maps multiple joint angles of the human arm to the corresponding cobot joints. Moreover, it uses an inverse kinematics model to then minimally adjust the joint angles, for accurate end-effector positioning. We evaluate the performance of this approach on two different realistic manipulation tasks. The first task is produce processing, which involves picking, inspecting, and placing onions based on whether they are blemished. The second task is liquid pouring, where the robot picks up bottles, pours the contents into designated containers, and disposes of the empty bottles. Our results demonstrate advances in human-like robotic manipulation, leading to more human-robot compatibility in manufacturing applications.