Modality-Driven Design for Multi-Step Dexterous Manipulation: Insights from Neuroscience
作者: Naoki Wake, Atsushi Kanehira, Daichi Saito, Jun Takamatsu, Kazuhiro Sasabuchi, Hideki Koike, Katsushi Ikeuchi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-12-15
备注: 8 pages, 5 figures, 2 tables. Last updated on December 14th, 2024
💡 一句话要点
提出神经科学启发的模态驱动方法,解决多步骤灵巧操作问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧操作 多步骤任务 模态驱动 神经科学 机器人控制
📋 核心要点
- 现有机器人灵巧操作研究较少关注多步骤任务,且常用端到端模型,忽略了不同步骤对不同模态信息的依赖。
- 受神经科学启发,将复杂操作分解为触达、抓取、旋转等子任务,并为每个子任务设计模态驱动的策略。
- 在真实机器人上验证了该方法的可行性,证明了模态驱动设计在多步骤灵巧操作中的有效性。
📝 摘要(中文)
多步骤灵巧操作是家庭场景中的一项基本技能,但在机器人领域仍未得到充分探索。本文提出了一种模块化方法,其中操作过程的每个步骤都基于有效的模态输入,采用专门的策略来处理,而不是依赖于单一的端到端模型。为了证明这一点,一个灵巧的机器人手执行了一项涉及拾取和旋转盒子的操作任务。在神经科学的指导下,该任务被分解为三个子技能:1) 触达,2) 抓取和抬起,3) 手内旋转,这些子技能分别基于人类大脑中使用的主要感觉模态。从实际角度出发,每个子技能都使用不同的方法来解决:经典控制器、视觉-语言-动作模型和带有力反馈的强化学习策略。我们在真实的机器人上测试了该流程,以证明我们方法的可行性。这项研究的关键贡献在于提出了一种神经科学启发的、模态驱动的多步骤灵巧操作方法。
🔬 方法详解
问题定义:论文旨在解决机器人灵巧操作中多步骤任务的挑战。现有方法,特别是端到端模型,难以有效处理复杂操作,并且忽略了不同操作步骤对不同感觉模态(如视觉、触觉、力觉)的依赖性。这导致了操作的鲁棒性和效率降低。
核心思路:论文的核心思路是借鉴神经科学的研究成果,将复杂的多步骤操作分解为若干个子任务,并针对每个子任务选择最合适的模态信息作为输入,设计专门的控制策略。这种模态驱动的设计能够更有效地利用不同感觉信息,提高操作的精度和鲁棒性。
技术框架:整体框架包含三个主要模块,对应于三个子任务:1) 触达(Reaching):使用经典控制器,可能依赖于视觉信息来引导机械臂到达目标物体附近。2) 抓取和抬起(Grasping and Lifting):使用视觉-语言-动作模型,结合视觉信息和语言指令来完成抓取动作。3) 手内旋转(In-hand Rotation):使用带有力反馈的强化学习策略,通过力传感器获取的触觉信息来优化旋转动作。这三个模块顺序执行,完成整个多步骤操作。
关键创新:该论文的关键创新在于提出了一个神经科学启发的模态驱动设计方法。与传统的端到端方法不同,该方法强调针对不同操作步骤选择最合适的模态信息,并设计专门的控制策略。这种方法能够更有效地利用不同感觉信息,提高操作的精度和鲁棒性。
关键设计:具体的技术细节包括:1) 触达模块可能使用基于视觉伺服的经典PID控制器。2) 抓取模块的视觉-语言-动作模型可能采用Transformer架构,将视觉特征和语言指令编码为联合表示,然后解码为机械臂的控制指令。3) 手内旋转模块的强化学习策略可能使用Actor-Critic算法,力反馈信息作为状态输入,优化旋转动作的策略。
🖼️ 关键图片


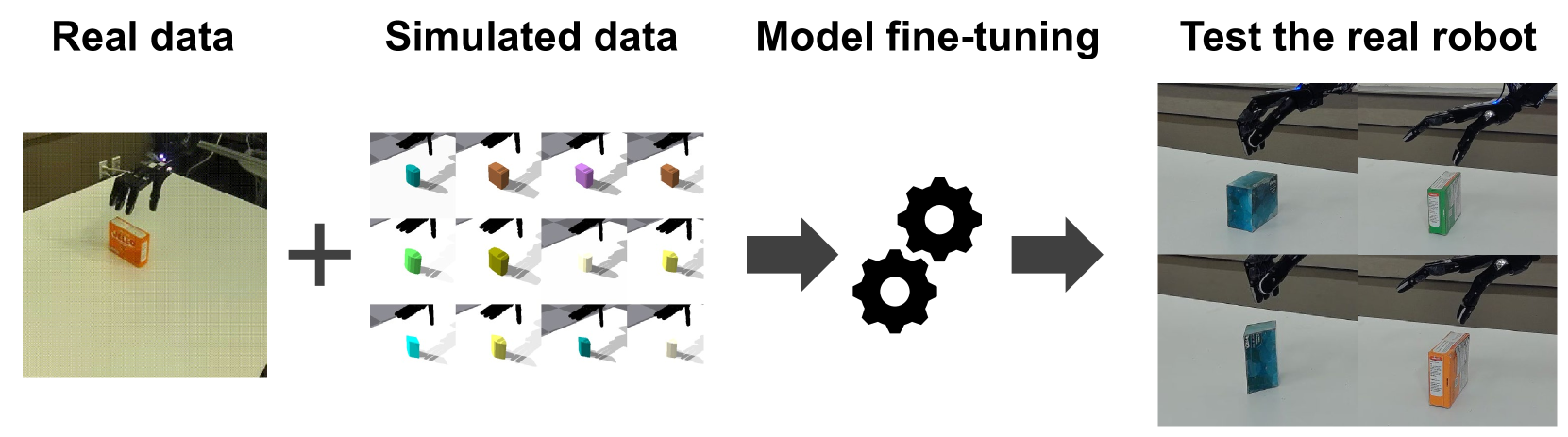
📊 实验亮点
该论文在真实机器人上验证了所提出的模态驱动方法的可行性。虽然论文中没有给出具体的性能数据,但通过实验证明了该方法能够成功完成多步骤的灵巧操作任务,例如拾取和旋转盒子。与传统的端到端方法相比,该方法在理论上具有更高的鲁棒性和可解释性,为未来的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于家庭服务机器人、工业自动化等领域。例如,机器人可以执行更复杂的家务任务,如整理物品、烹饪等。在工业领域,可以用于精密装配、物料搬运等场景,提高生产效率和自动化水平。未来,该方法有望推广到更多复杂操作任务中。
📄 摘要(原文)
Multi-step dexterous manipulation is a fundamental skill in household scenarios, yet remains an underexplored area in robotics. This paper proposes a modular approach, where each step of the manipulation process is addressed with dedicated policies based on effective modality input, rather than relying on a single end-to-end model. To demonstrate this, a dexterous robotic hand performs a manipulation task involving picking up and rotating a box. Guided by insights from neuroscience, the task is decomposed into three sub-skills, 1)reaching, 2)grasping and lifting, and 3)in-hand rotation, based on the dominant sensory modalities employed in the human brain. Each sub-skill is addressed using distinct methods from a practical perspective: a classical controller, a Vision-Language-Action model, and a reinforcement learning policy with force feedback, respectively. We tested the pipeline on a real robot to demonstrate the feasibility of our approach. The key contribution of this study lies in presenting a neuroscience-inspired, modality-driven methodology for multi-step dexterous manipulation.