Grasp What You Want: Embodied Dexterous Grasping System Driven by Your Voice
作者: Junliang Li, Kai Ye, Haolan Kang, Mingxuan Liang, Yuhang Wu, Zhenhua Liu, Huiping Zhuang, Rui Huang, Yongquan Chen
分类: cs.RO
发布日期: 2024-12-14
💡 一句话要点
提出EDGS系统,通过语音驱动灵巧手抓取,解决复杂环境下人机交互问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 灵巧抓取 语音控制 视觉-语言模型 人机交互
📋 核心要点
- 现有机器人难以仅通过语音命令准确理解人类意图,传统夹爪系统缺乏自然交互和复杂操作能力。
- EDGS系统利用视觉-语言模型融合语音和视觉信息,提升复杂场景下目标物体属性的对齐。
- 该系统借鉴人手抓取机制,设计了鲁棒、精确、高效的抓取策略,并在实验中验证了其有效性。
📝 摘要(中文)
本文提出了一种具身灵巧抓取系统(EDGS),旨在解决人机交互中复杂环境下的物体抓取问题。该系统利用视觉-语言模型(VLM)融合语音指令和视觉信息,显著增强了目标物体多维属性在复杂场景中的对齐。受人手-物体交互的启发,开发了一种鲁棒、精确且高效的抓取策略,该策略结合了拇指-物体轴、多指包裹以及指尖与物体接触力学等原则。实验评估了指代表达分割中的指代表达表征丰富(RERE),结果表明系统能够准确检测和匹配指代表达。大量实验证实,EDGS能够有效处理复杂的抓取任务,实现稳定和高成功率,突显了其在具身人工智能领域进一步发展的潜力。
🔬 方法详解
问题定义:论文旨在解决复杂、非结构化环境中,机器人如何根据人类的语音指令,准确抓取目标物体的问题。现有方法通常依赖于简单的夹爪或吸盘,缺乏灵巧操作能力,并且难以准确理解语音指令中的语义信息,导致抓取成功率低,人机交互体验差。
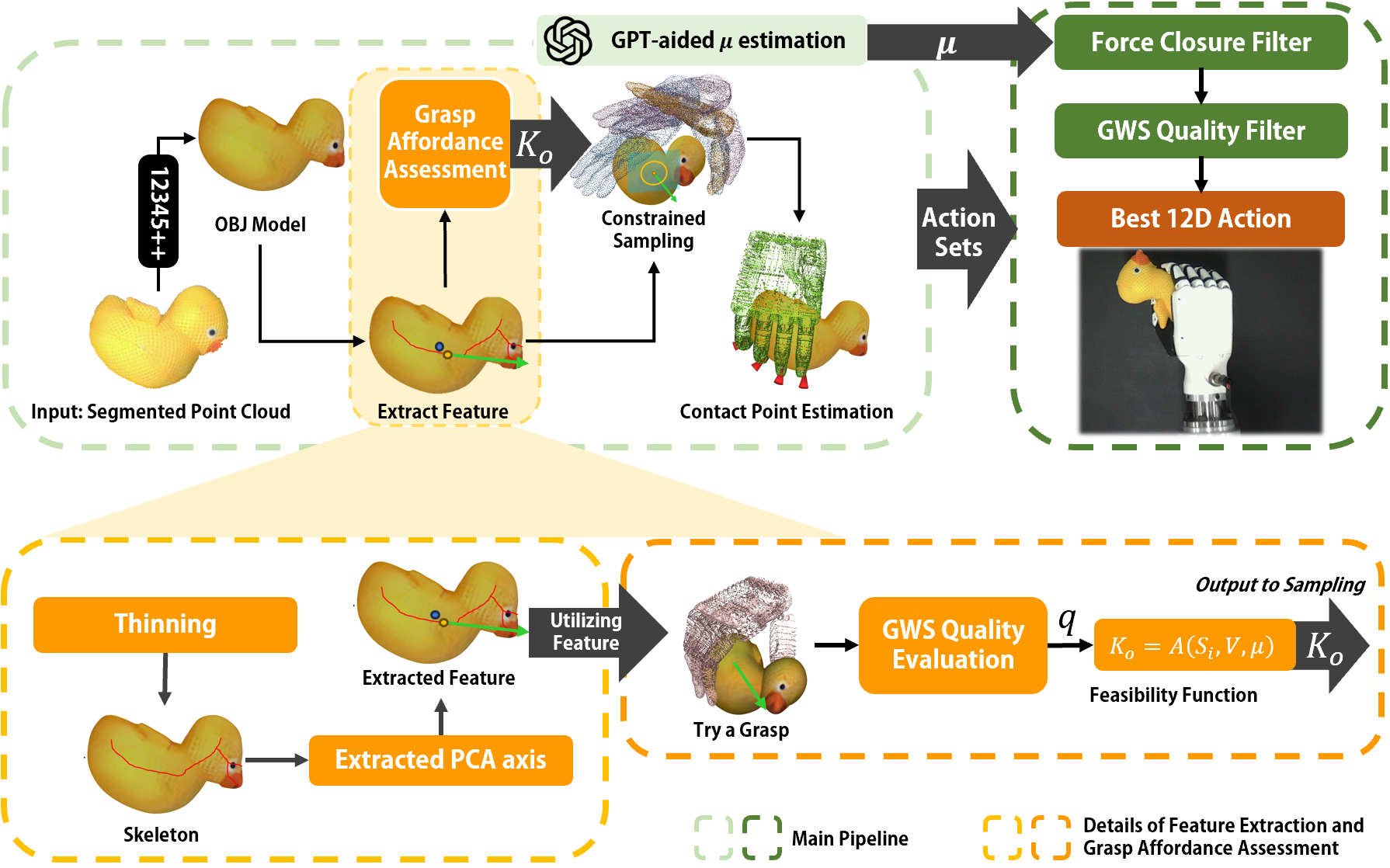
核心思路:论文的核心思路是利用视觉-语言模型(VLM)将语音指令和视觉信息进行融合,从而更准确地理解人类的意图。同时,借鉴人手抓取物体的机制,设计一种鲁棒、精确且高效的灵巧抓取策略,使机器人能够像人一样灵活地抓取各种形状和大小的物体。
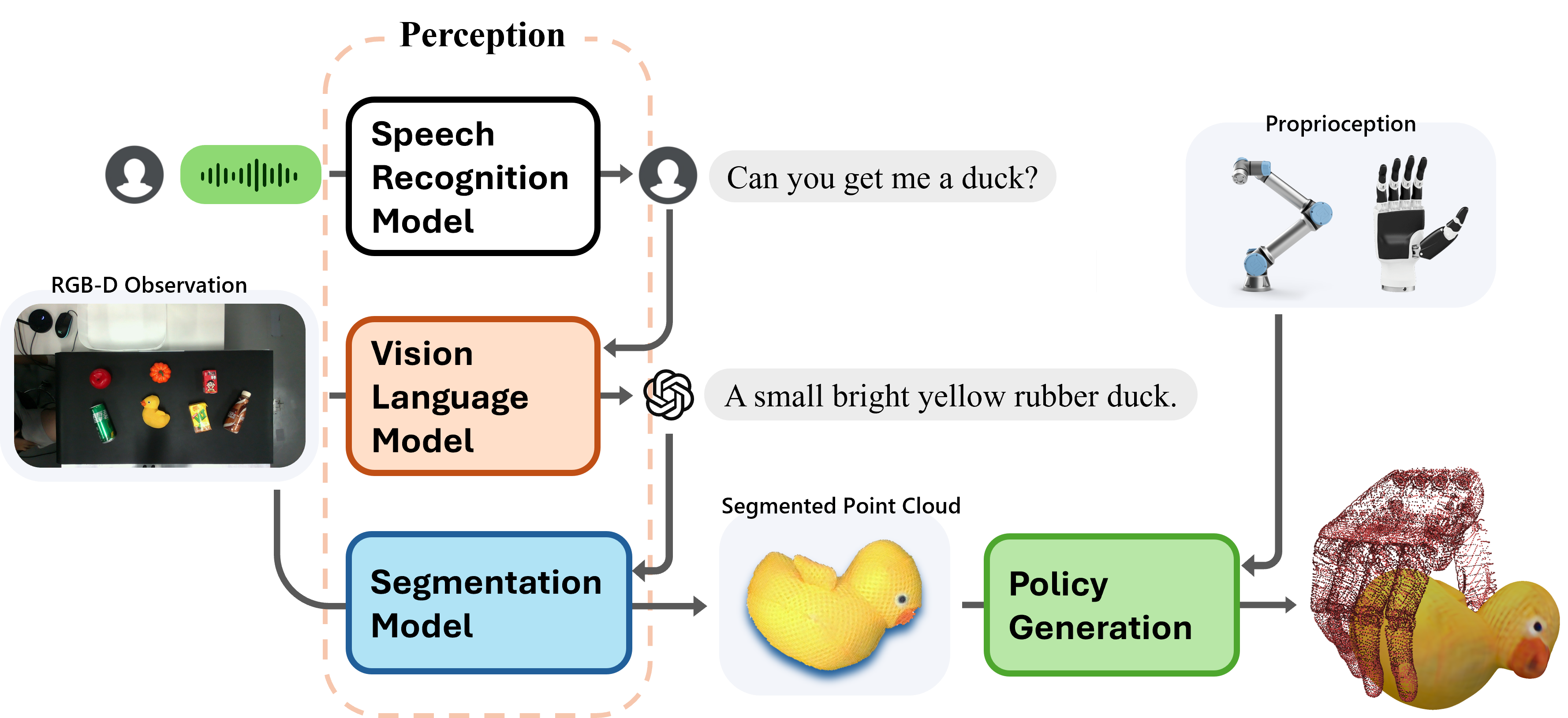
技术框架:EDGS系统主要包含以下几个模块:1) 语音识别模块:将人类的语音指令转换为文本信息。2) 视觉感知模块:利用摄像头获取环境的视觉信息,包括物体的形状、大小、位置等。3) 视觉-语言融合模块:利用VLM将语音指令和视觉信息进行融合,生成目标物体的语义表示。4) 抓取策略生成模块:根据目标物体的语义表示,生成合适的抓取姿态和抓取轨迹。5) 灵巧手控制模块:控制灵巧手执行抓取动作。
关键创新:论文的关键创新在于以下几个方面:1) 提出了一种基于VLM的语义-物体对齐方法,能够更准确地理解语音指令中的语义信息。2) 设计了一种借鉴人手抓取机制的灵巧抓取策略,能够实现鲁棒、精确且高效的抓取。3) 提出了指代表达表征丰富(RERE)的概念,并设计了相应的实验来评估系统的指代表达分割能力。
关键设计:论文中关于VLM的具体模型选择、损失函数设计以及灵巧手的控制算法等技术细节未知。但整体框架强调了多模态信息融合和模仿人类抓取行为的重要性。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了EDGS系统在复杂抓取任务中的有效性,实现了较高的抓取成功率和稳定性。具体性能数据和对比基线未知,但实验结果表明,该系统能够准确检测和匹配指代表达,并能够根据语音指令抓取目标物体,突显了其在具身人工智能领域的潜力。
🎯 应用场景
该研究成果可应用于智能家居、仓储物流、医疗康复等领域。例如,在智能家居中,机器人可以根据用户的语音指令抓取物品;在仓储物流中,机器人可以自动分拣和搬运货物;在医疗康复中,机器人可以辅助患者进行康复训练。该研究有助于提升人机交互的自然性和效率,推动机器人技术在实际生活中的应用。
📄 摘要(原文)
In recent years, as robotics has advanced, human-robot collaboration has gained increasing importance. However, current robots struggle to fully and accurately interpret human intentions from voice commands alone. Traditional gripper and suction systems often fail to interact naturally with humans, lack advanced manipulation capabilities, and are not adaptable to diverse tasks, especially in unstructured environments. This paper introduces the Embodied Dexterous Grasping System (EDGS), designed to tackle object grasping in cluttered environments for human-robot interaction. We propose a novel approach to semantic-object alignment using a Vision-Language Model (VLM) that fuses voice commands and visual information, significantly enhancing the alignment of multi-dimensional attributes of target objects in complex scenarios. Inspired by human hand-object interactions, we develop a robust, precise, and efficient grasping strategy, incorporating principles like the thumb-object axis, multi-finger wrapping, and fingertip interaction with an object's contact mechanics. We also design experiments to assess Referring Expression Representation Enrichment (RERE) in referring expression segmentation, demonstrating that our system accurately detects and matches referring expressions. Extensive experiments confirm that EDGS can effectively handle complex grasping tasks, achieving stability and high success rates, highlighting its potential for further development in the field of Embodied AI.