TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
作者: Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé, Andrey Kolobov, Furong Huang, Jianwei Yang
分类: cs.RO, cs.AI
发布日期: 2024-12-13 (更新: 2025-06-05)
💡 一句话要点
TraceVLA:视觉轨迹提示增强通用机器人策略的时空感知能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 视觉语言动作模型 时空感知 视觉轨迹提示 机器人操作
📋 核心要点
- 现有VLA模型在处理机器人交互中的时空动态方面存在不足,难以有效完成复杂操作任务。
- 论文提出视觉轨迹提示方法,通过视觉编码状态-动作轨迹,增强VLA模型对时空信息的感知能力。
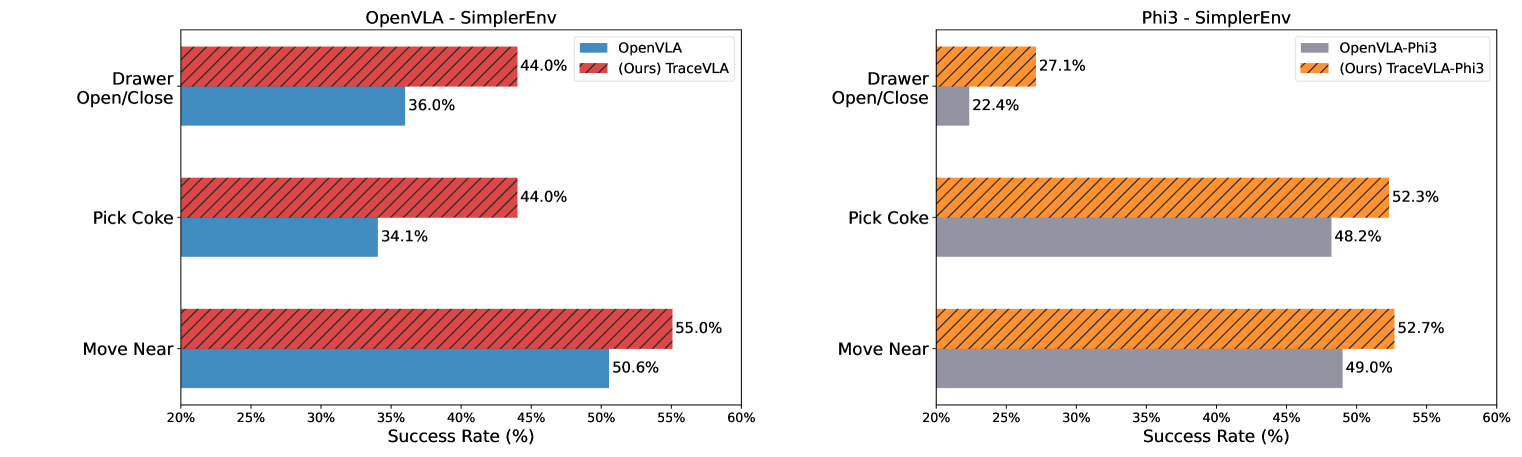
- 实验表明,TraceVLA在模拟和真实机器人任务中均优于OpenVLA,并展现出良好的泛化能力。
📝 摘要(中文)
大型视觉-语言-动作(VLA)模型在海量机器人数据集上进行预训练,为机器人学习提供了有前景的通用策略,但它们在交互式机器人中的时空动态方面仍然存在不足,使其在处理复杂的任务(如操作)时效果不佳。本文提出了一种简单而有效的视觉轨迹提示方法,通过视觉编码状态-动作轨迹来促进VLA模型对动作预测的时空感知。我们通过使用视觉轨迹提示在收集的15万个机器人操作轨迹数据集上微调OpenVLA,开发了一种新的TraceVLA模型。在SimplerEnv中的137个配置和真实WidowX机器人上的4个任务的评估表明,TraceVLA表现出最先进的性能,在SimplerEnv上优于OpenVLA 10%,在真实机器人任务上优于3.5倍,并在不同的机器人形态和场景中表现出强大的泛化能力。为了进一步验证我们方法的有效性和通用性,我们提出了一个基于4B Phi-3-Vision的紧凑型VLA模型,该模型在Open-X-Embodiment上进行了预训练,并在我们的数据集上进行了微调,在显著提高推理效率的同时,可以与7B OpenVLA基线相媲美。
🔬 方法详解
问题定义:现有的大型视觉-语言-动作模型(VLA)在机器人操作任务中,难以有效处理时空动态信息,导致在复杂操作任务中表现不佳。这些模型通常缺乏对过去状态和动作序列的有效记忆和利用,从而难以预测未来的动作。
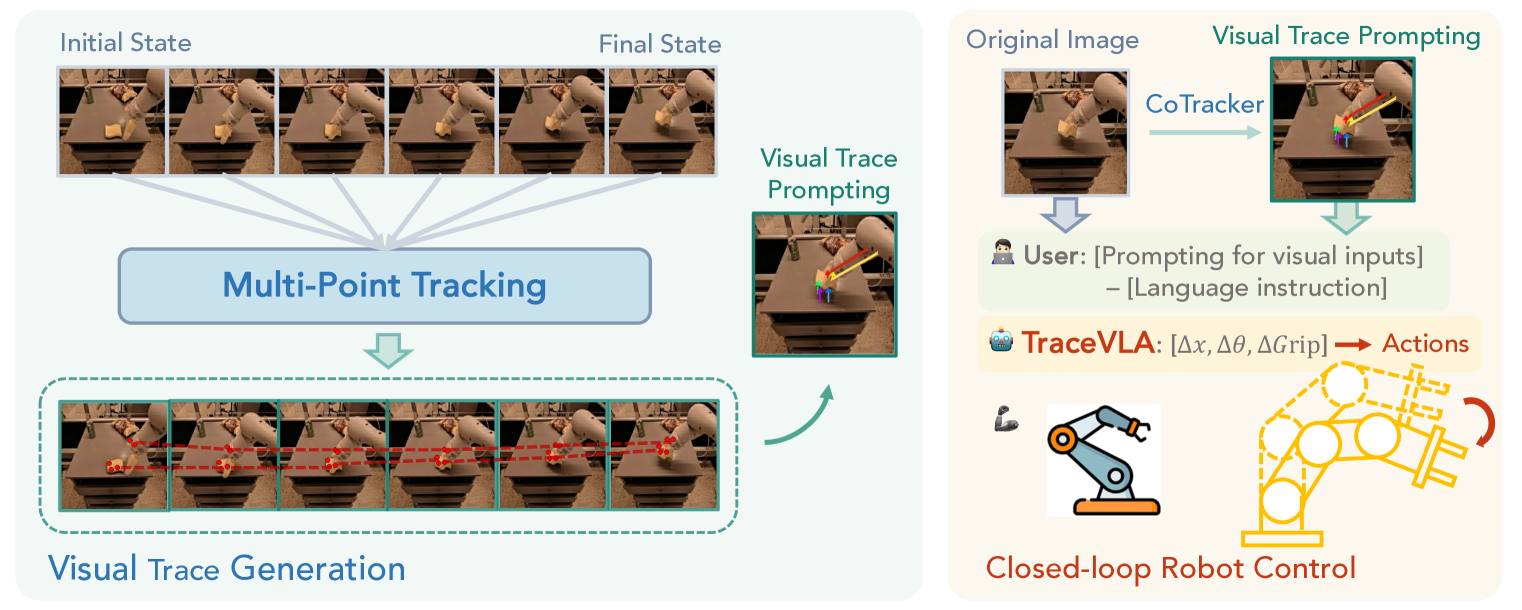
核心思路:论文的核心思路是通过视觉轨迹提示(Visual Trace Prompting)来增强VLA模型对时空信息的感知能力。具体来说,就是将过去的状态-动作轨迹以视觉化的方式编码,并作为模型的输入,从而让模型能够更好地理解和利用历史信息。
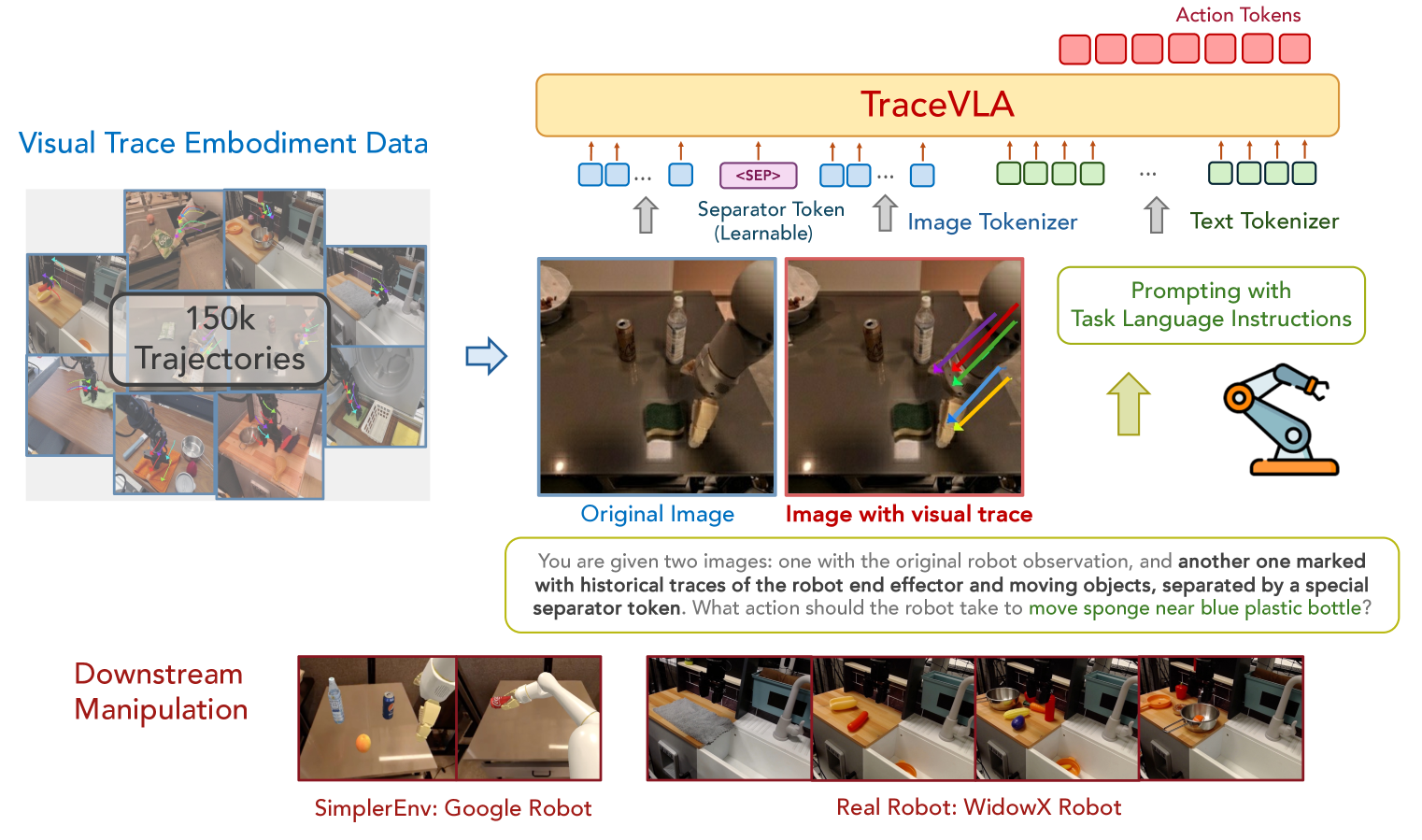
技术框架:TraceVLA模型基于OpenVLA进行微调。整体流程如下:1)收集机器人操作轨迹数据集;2)将状态-动作轨迹编码为视觉轨迹提示;3)使用视觉轨迹提示微调OpenVLA模型;4)评估TraceVLA模型在模拟和真实机器人任务中的性能。主要模块包括:视觉轨迹编码器、VLA模型(OpenVLA)、动作预测模块。
关键创新:关键创新在于视觉轨迹提示方法。与传统的直接输入状态和动作序列的方法不同,视觉轨迹提示将历史信息编码为图像,从而可以利用卷积神经网络等视觉模型来提取时空特征。这种方法可以更有效地利用历史信息,并提高模型的泛化能力。
关键设计:视觉轨迹编码器将状态-动作轨迹转换为图像。具体来说,可以将每个状态和动作表示为一个图像,然后将这些图像拼接在一起,形成一个视觉轨迹提示。损失函数采用标准的交叉熵损失函数,用于训练VLA模型预测正确的动作。网络结构基于OpenVLA,并添加了视觉轨迹编码器作为输入。
🖼️ 关键图片
📊 实验亮点
TraceVLA在SimplerEnv上超越OpenVLA 10%,在真实机器人任务上性能提升3.5倍。基于4B Phi-3-Vision的紧凑型VLA模型,在Open-X-Embodiment上预训练并在作者数据集上微调后,性能可与7B OpenVLA基线媲美,同时显著提高了推理效率。实验结果表明,视觉轨迹提示方法能够有效提升VLA模型在机器人操作任务中的性能和泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过增强机器人对时空信息的感知能力,可以提高机器人在复杂环境中的适应性和鲁棒性。此外,该方法还可以应用于其他需要时空推理的任务,例如视频理解、自动驾驶等。未来,该技术有望推动机器人智能化水平的提升,使其能够更好地服务于人类。
📄 摘要(原文)
Although large vision-language-action (VLA) models pretrained on extensive robot datasets offer promising generalist policies for robotic learning, they still struggle with spatial-temporal dynamics in interactive robotics, making them less effective in handling complex tasks, such as manipulation. In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate VLA models' spatial-temporal awareness for action prediction by encoding state-action trajectories visually. We develop a new TraceVLA model by finetuning OpenVLA on our own collected dataset of 150K robot manipulation trajectories using visual trace prompting. Evaluations of TraceVLA across 137 configurations in SimplerEnv and 4 tasks on a physical WidowX robot demonstrate state-of-the-art performance, outperforming OpenVLA by 10% on SimplerEnv and 3.5x on real-robot tasks and exhibiting robust generalization across diverse embodiments and scenarios. To further validate the effectiveness and generality of our method, we present a compact VLA model based on 4B Phi-3-Vision, pretrained on the Open-X-Embodiment and finetuned on our dataset, rivals the 7B OpenVLA baseline while significantly improving inference efficiency.