Constraint-Aware Zero-Shot Vision-Language Navigation in Continuous Environments
作者: Kehan Chen, Dong An, Yan Huang, Rongtao Xu, Yifei Su, Yonggen Ling, Ian Reid, Liang Wang
分类: cs.RO, cs.CV
发布日期: 2024-12-13 (更新: 2025-04-15)
💡 一句话要点
提出约束感知导航器CA-Nav,解决连续环境中零样本视觉-语言导航问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 零样本学习 连续环境 约束感知 机器人导航
📋 核心要点
- 零样本VLN-CE缺乏训练数据和环境先验,导致智能体难以有效导航。
- CA-Nav将导航分解为约束感知的子指令完成过程,并动态生成导航计划。
- 实验表明,CA-Nav在R2R-CE和RxR-CE上显著提升了导航成功率,并在真实机器人部署中有效。
📝 摘要(中文)
本文研究了连续环境下的零样本视觉-语言导航(VLN-CE)任务。由于缺乏专家演示训练和最小的环境结构先验来指导导航,零样本VLN-CE极具挑战性。为了应对这些挑战,我们提出了一种约束感知导航器(CA-Nav),它将零样本VLN-CE重新定义为一个连续的、约束感知的子指令完成过程。CA-Nav使用两个核心模块:约束感知子指令管理器(CSM)和约束感知值映射器(CVM),不断地将子指令转换为导航计划。CSM将分解的子指令的完成标准定义为约束,并通过约束感知的方式切换子指令来跟踪导航进度。CVM在CSM的约束指导下,动态生成值图,并使用超像素聚类对其进行细化,以提高导航稳定性。CA-Nav在两个VLN-CE基准测试中取得了最先进的性能,在R2R-CE和RxR-CE的验证未见分割上,成功率分别超过了之前最好的方法12%和13%。此外,CA-Nav还在各种室内场景和指令的真实机器人部署中展示了其有效性。
🔬 方法详解
问题定义:论文旨在解决连续环境下的零样本视觉-语言导航(VLN-CE)问题。现有方法在缺乏专家演示和环境结构先验的情况下,难以有效地进行导航,导致成功率较低。痛点在于如何让智能体在没有训练数据的情况下,理解语言指令并自主探索环境。
核心思路:论文的核心思路是将复杂的导航任务分解为一系列约束感知的子指令完成过程。通过显式地定义子指令的完成标准(即约束),并利用这些约束来指导导航计划的生成和执行,从而提高导航的效率和稳定性。这种方法模拟了人类在导航时的分步规划和执行策略。
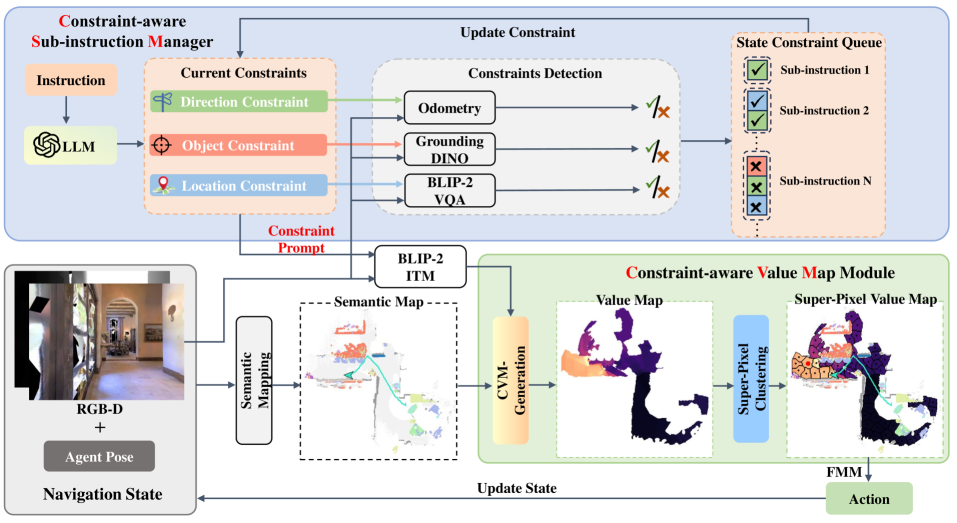
技术框架:CA-Nav包含两个主要模块:约束感知子指令管理器(CSM)和约束感知值映射器(CVM)。CSM负责将指令分解为子指令,并根据环境反馈和预设的约束条件,动态地切换到下一个子指令。CVM则根据当前子指令和CSM提供的约束信息,生成一个值图,用于指导智能体的运动。整个过程是一个循环迭代的过程,直到智能体到达目标位置或达到最大步数。
关键创新:论文的关键创新在于提出了约束感知的导航框架。通过显式地定义和利用约束条件,CA-Nav能够更好地理解语言指令的意图,并生成更有效的导航计划。此外,CVM中使用的超像素聚类技术能够有效地提高导航的稳定性,减少噪声的影响。与现有方法相比,CA-Nav不需要任何训练数据,并且能够更好地适应不同的环境和指令。
关键设计:CSM使用一个循环神经网络(RNN)来跟踪导航进度,并根据环境反馈和约束条件来决定何时切换到下一个子指令。CVM使用一个卷积神经网络(CNN)来处理视觉输入,并生成一个值图,用于指导智能体的运动。超像素聚类算法用于对值图进行平滑处理,以提高导航的稳定性。损失函数的设计旨在鼓励智能体朝着目标方向移动,并避免碰撞。
🖼️ 关键图片


📊 实验亮点
CA-Nav在R2R-CE和RxR-CE的验证未见分割上,成功率分别超过了之前最好的方法12%和13%,取得了显著的性能提升。此外,CA-Nav还在真实机器人部署中展示了其有效性,验证了其在实际应用中的潜力。这些结果表明,约束感知的导航框架能够有效地提高零样本VLN-CE的性能。
🎯 应用场景
该研究成果可应用于机器人导航、虚拟现实、自动驾驶等领域。例如,可以用于开发能够在复杂室内环境中自主导航的机器人,或者为视障人士提供导航辅助。未来,该技术有望扩展到更复杂的环境和任务中,例如户外导航、搜索救援等。
📄 摘要(原文)
We address the task of Vision-Language Navigation in Continuous Environments (VLN-CE) under the zero-shot setting. Zero-shot VLN-CE is particularly challenging due to the absence of expert demonstrations for training and minimal environment structural prior to guide navigation. To confront these challenges, we propose a Constraint-Aware Navigator (CA-Nav), which reframes zero-shot VLN-CE as a sequential, constraint-aware sub-instruction completion process. CA-Nav continuously translates sub-instructions into navigation plans using two core modules: the Constraint-Aware Sub-instruction Manager (CSM) and the Constraint-Aware Value Mapper (CVM). CSM defines the completion criteria for decomposed sub-instructions as constraints and tracks navigation progress by switching sub-instructions in a constraint-aware manner. CVM, guided by CSM's constraints, generates a value map on the fly and refines it using superpixel clustering to improve navigation stability. CA-Nav achieves the state-of-the-art performance on two VLN-CE benchmarks, surpassing the previous best method by 12 percent and 13 percent in Success Rate on the validation unseen splits of R2R-CE and RxR-CE, respectively. Moreover, CA-Nav demonstrates its effectiveness in real-world robot deployments across various indoor scenes and instructions.