Reward Machine Inference for Robotic Manipulation
作者: Mattijs Baert, Sam Leroux, Pieter Simoens
分类: cs.RO, cs.LG
发布日期: 2024-12-13
💡 一句话要点
提出基于视觉演示的奖励机推理方法,用于机器人操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 奖励机 从演示学习 强化学习 视觉学习 任务规划 自主学习
📋 核心要点
- 现有方法在机器人操作任务中,依赖预定义命题或稀疏奖励信号的先验知识,限制了其泛化能力。
- 该论文提出一种新的从演示学习方法,联合学习奖励机结构和关键高级事件,无需预定义信息。
- 实验结果表明,该方法推断的奖励机能够准确捕获任务结构,并帮助强化学习智能体学习最优策略。
📝 摘要(中文)
本文提出了一种新颖的从演示学习(LfD)方法,用于直接从机器人操作任务的视觉演示中学习奖励机(RM)。与以往的方法不同,我们的方法不需要预定义的命题或关于底层稀疏奖励信号的先验知识。相反,它联合学习RM结构并识别驱动RM状态之间转换的关键高级事件。我们在基于视觉的操作任务上验证了我们的方法,结果表明,推断出的RM能够准确地捕获任务结构,并使强化学习(RL)智能体能够有效地学习最优策略。
🔬 方法详解
问题定义:现有的机器人操作任务学习方法,特别是基于奖励机的方法,通常需要预定义的命题或关于底层稀疏奖励信号的先验知识。这限制了它们在复杂和未知环境中的应用,因为手动设计这些先验知识既耗时又容易出错。因此,如何从原始视觉数据中自动学习奖励机结构,成为一个重要的挑战。
核心思路:该论文的核心思路是通过观察机器人操作任务的视觉演示,直接学习奖励机的结构和状态转移规则。关键在于,不需要任何预定义的命题或奖励信号,而是通过分析视觉数据中的关键事件来推断任务的逻辑结构。这种方法旨在提高机器人学习的自主性和泛化能力。
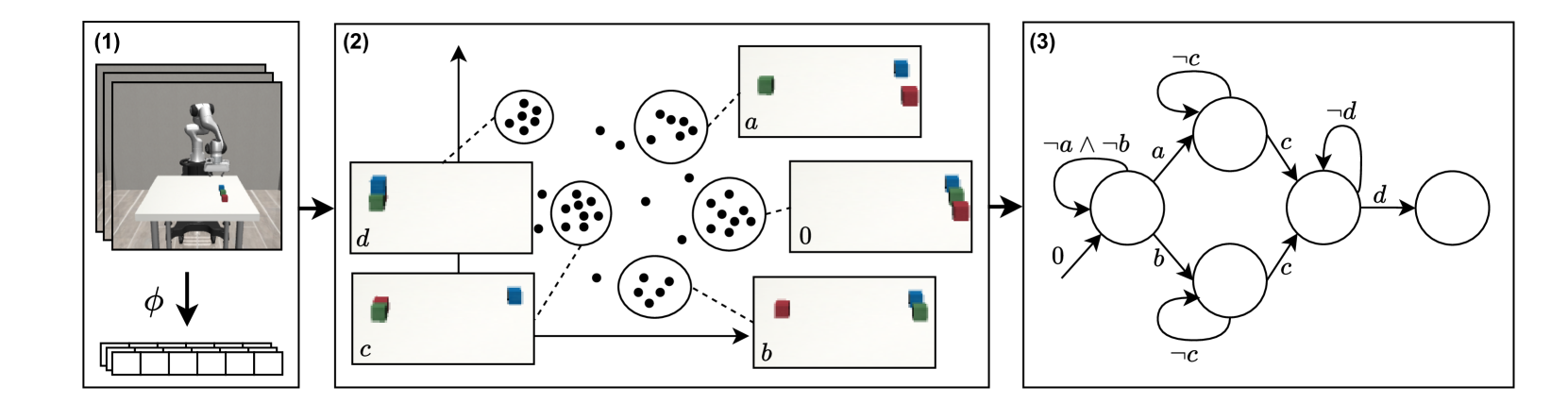
技术框架:该方法主要包含以下几个阶段:1) 视觉数据收集:收集机器人操作任务的视觉演示数据。2) 关键事件识别:使用深度学习模型(具体模型未知)从视觉数据中识别关键的高级事件。这些事件代表了任务执行过程中的重要状态变化。3) 奖励机结构学习:基于识别的关键事件,学习奖励机的状态和状态转移规则。这可能涉及到聚类、图模型或其他结构学习技术(具体方法未知)。4) 强化学习策略优化:使用学习到的奖励机作为强化学习的奖励函数,训练机器人智能体学习最优策略。
关键创新:该论文最重要的创新点在于,它提出了一种完全基于视觉演示的奖励机学习方法,无需任何预定义的命题或奖励信号。这与以往的方法形成了鲜明对比,大大提高了机器人学习的自主性和灵活性。通过联合学习奖励机结构和关键事件,该方法能够更好地理解任务的逻辑结构,并为强化学习提供更有效的奖励信号。
关键设计:论文中关于关键设计部分的细节描述较少,以下是一些可能的关键设计(基于常识推断):1) 关键事件识别模型的选择和训练:选择合适的深度学习模型(例如,Transformer或卷积神经网络)来识别视觉数据中的关键事件,并使用大量的视觉演示数据进行训练。2) 奖励机结构学习算法:设计一种有效的算法来学习奖励机的状态和状态转移规则,例如,基于聚类的状态划分方法或基于图模型的结构学习方法。3) 奖励函数设计:根据学习到的奖励机结构,设计合适的奖励函数,以指导强化学习智能体学习最优策略。4) 强化学习算法选择:选择合适的强化学习算法(例如,Q-learning或Actor-Critic方法)来训练机器人智能体。
🖼️ 关键图片


📊 实验亮点
论文通过视觉操作任务验证了所提方法的有效性。实验结果表明,该方法能够准确地从视觉演示中推断出奖励机结构,并使强化学习智能体能够有效地学习最优策略。具体的性能数据和对比基线未知,但摘要强调了该方法在捕获任务结构和学习最优策略方面的有效性。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务,例如装配、抓取、导航等。通过从视觉演示中自动学习任务结构,可以大大降低机器人编程的难度,提高机器人的自主性和适应性。未来,该方法有望应用于更复杂的任务,例如人机协作、智能制造等领域,实现更智能、更高效的机器人系统。
📄 摘要(原文)
Learning from Demonstrations (LfD) and Reinforcement Learning (RL) have enabled robot agents to accomplish complex tasks. Reward Machines (RMs) enhance RL's capability to train policies over extended time horizons by structuring high-level task information. In this work, we introduce a novel LfD approach for learning RMs directly from visual demonstrations of robotic manipulation tasks. Unlike previous methods, our approach requires no predefined propositions or prior knowledge of the underlying sparse reward signals. Instead, it jointly learns the RM structure and identifies key high-level events that drive transitions between RM states. We validate our method on vision-based manipulation tasks, showing that the inferred RM accurately captures task structure and enables an RL agent to effectively learn an optimal policy.