ManipGPT: Is Affordance Segmentation by Large Vision Models Enough for Articulated Object Manipulation?
作者: Taewhan Kim, Hojin Bae, Zeming Li, Xiaoqi Li, Iaroslav Ponomarenko, Ruihai Wu, Hao Dong
分类: cs.RO, cs.CV
发布日期: 2024-12-13 (更新: 2025-10-09)
备注: 8 pages, 6 figures
💡 一句话要点
ManipGPT:利用大型视觉模型进行可动对象操作的Affordance分割
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 Affordance分割 视觉Transformer Sim-to-Real 可动对象
📋 核心要点
- 现有机器人操作方法计算密集,难以适应动态环境,限制了其在复杂场景中的应用。
- ManipGPT利用大型预训练视觉Transformer,通过少量数据微调,预测可动对象最佳交互区域。
- 实验表明,ManipGPT在模拟和真实环境中均能有效生成零件级别的Affordance掩码,提升操作性能。
📝 摘要(中文)
视觉可操作性Affordance已成为机器人领域的一种变革性方法,专注于在操作之前感知交互区域。传统方法依赖于像素采样来识别成功的交互样本,或者处理点云以进行Affordance映射。然而,这些方法计算量大,难以适应多样化和动态环境。本文介绍了ManipGPT,一个旨在利用大型预训练视觉Transformer(ViT)预测可动对象最佳交互区域的框架。我们创建了一个包含9.9k张模拟和真实图像的数据集,以弥合视觉Sim-to-Real差距,并增强现实世界的适用性。通过在这个小数据集上微调视觉Transformer,我们显著提高了零件级别的Affordance分割性能,使模型的上下文分割能力适应于机器人操作场景。通过生成零件级别的Affordance掩码,并结合阻抗自适应策略,从而有效地消除了对复杂数据集或感知系统的需求,实现了在模拟和真实环境中的有效操作。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,传统方法依赖大量数据和复杂感知系统,难以有效识别可动对象交互区域的问题。现有方法计算成本高昂,泛化能力不足,难以适应真实世界的复杂环境。
核心思路:论文的核心思路是利用大型预训练视觉Transformer的强大特征提取和分割能力,通过少量数据微调,使其能够准确预测可动对象的Affordance区域。通过这种方式,减少了对大量训练数据的依赖,并提高了模型在真实环境中的泛化能力。
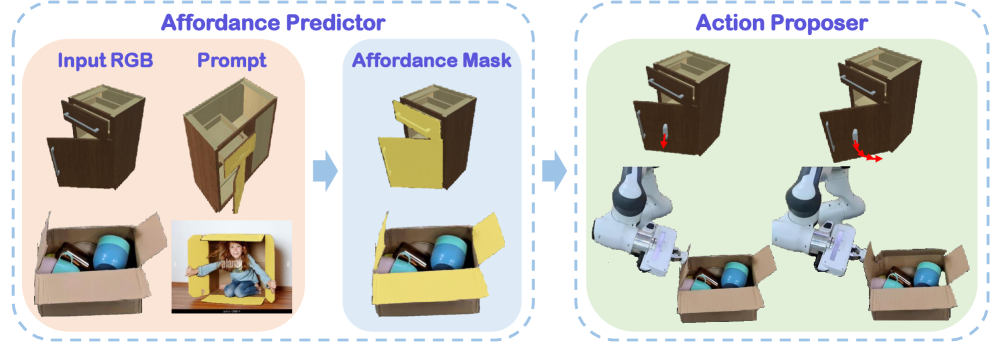
技术框架:ManipGPT框架主要包含两个阶段:1) 数据集构建:构建包含模拟和真实图像的混合数据集,以弥合Sim-to-Real差距。2) 模型微调:在构建的数据集上微调预训练的视觉Transformer,使其能够生成零件级别的Affordance掩码。框架还结合了阻抗自适应策略,进一步提升操作性能。
关键创新:论文的关键创新在于利用大型预训练模型进行Affordance分割,并结合Sim-to-Real的数据集构建方法,实现了在少量数据下对真实世界可动对象操作的有效预测。与传统方法相比,ManipGPT减少了对大量数据的依赖,并提高了模型的泛化能力。
关键设计:论文的关键设计包括:1) 混合数据集:包含模拟和真实图像,以提高模型的Sim-to-Real泛化能力。2) 视觉Transformer微调:使用少量数据微调预训练的视觉Transformer,使其适应Affordance分割任务。3) 阻抗自适应策略:结合阻抗自适应策略,进一步提升操作的鲁棒性和精度。具体的损失函数和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文构建了一个包含9.9k张模拟和真实图像的数据集,并在此基础上微调了视觉Transformer。实验结果表明,ManipGPT能够有效生成零件级别的Affordance掩码,并在模拟和真实环境中实现有效的可动对象操作。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于各种机器人操作场景,例如智能家居、工业自动化、医疗机器人等。通过准确预测可动对象的Affordance区域,机器人可以更安全、高效地完成各种操作任务,提高生产效率和服务质量。未来,该方法有望扩展到更复杂的环境和对象,实现更智能化的机器人操作。
📄 摘要(原文)
Visual actionable affordance has emerged as a transformative approach in robotics, focusing on perceiving interaction areas prior to manipulation. Traditional methods rely on pixel sampling to identify successful interaction samples or processing pointclouds for affordance mapping. However, these approaches are computationally intensive and struggle to adapt to diverse and dynamic environments. This paper introduces ManipGPT, a framework designed to predict optimal interaction areas for articulated objects using a large pre-trained vision transformer (ViT). We create a dataset of 9.9k simulated and real images to bridge the visual sim-to-real gap and enhance real-world applicability. By fine-tuning the vision transformer on this small dataset, we significantly improve part-level affordance segmentation, adapting the model's in-context segmentation capabilities to robot manipulation scenarios. This enables effective manipulation across simulated and real-world environments by generating part-level affordance masks, paired with an impedance adaptation policy, sufficiently eliminating the need for complex datasets or perception systems.