RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
作者: Charles Xu, Qiyang Li, Jianlan Luo, Sergey Levine
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-12-13
💡 一句话要点
RLDG:通过强化学习蒸馏机器人通用策略,提升操作任务性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 强化学习 策略蒸馏 通用策略 模仿学习
📋 核心要点
- 现有的机器人基础模型依赖于训练数据质量,限制了通用策略的性能。
- RLDG利用强化学习生成高质量训练数据,用于微调通用策略,提升性能和泛化能力。
- 真实世界实验表明,RLDG训练的策略在操作任务中成功率提升高达40%,并能更好泛化。
📝 摘要(中文)
本文提出了一种名为强化学习蒸馏通用策略(RLDG)的方法,该方法利用强化学习为通用策略的微调生成高质量的训练数据。通过在连接器插入和组装等精确操作任务上的大量真实世界实验,证明了使用RL生成的数据训练的通用策略始终优于使用人类演示训练的策略,成功率提高了高达40%,同时更好地泛化到新任务。详细的分析表明,这种性能提升源于优化的动作分布和改进的状态覆盖。研究结果表明,将特定任务的强化学习与通用策略蒸馏相结合,为开发更强大、更高效的机器人操作系统提供了一种有前景的方法,该方法既保持了基础模型的灵活性,又实现了专用控制器的性能。
🔬 方法详解
问题定义:现有机器人通用策略的性能受限于训练数据的质量,特别是人类演示数据可能存在次优性或覆盖范围不足的问题。这导致策略在复杂操作任务中表现不佳,泛化能力受限。
核心思路:RLDG的核心思想是利用强化学习(RL)来生成高质量的训练数据,然后使用这些数据来蒸馏(finetune)预训练的通用策略。通过RL,可以探索更优的动作序列和更广泛的状态空间,从而克服人类演示数据的局限性。
技术框架:RLDG包含两个主要阶段:1) RL数据生成阶段:使用强化学习算法(具体算法未知)训练一个特定任务的策略。该策略在真实环境中与机器人交互,生成高质量的轨迹数据,包括状态、动作和奖励。2) 策略蒸馏阶段:使用RL生成的数据集来微调预训练的通用策略。通过监督学习的方式,让通用策略学习模仿RL策略的行为,从而获得更好的性能和泛化能力。
关键创新:RLDG的关键创新在于将强化学习与通用策略蒸馏相结合,利用RL生成高质量的训练数据,克服了传统方法依赖人类演示数据的局限性。这种方法既能保持通用策略的灵活性,又能提升其在特定任务上的性能。
关键设计:论文中没有详细说明RL算法的具体选择和超参数设置,以及通用策略的网络结构和损失函数。这些细节可能因具体任务而异,需要在实际应用中进行调整。损失函数可能包括行为克隆损失(模仿RL策略的动作)和正则化项(防止过拟合)。
🖼️ 关键图片
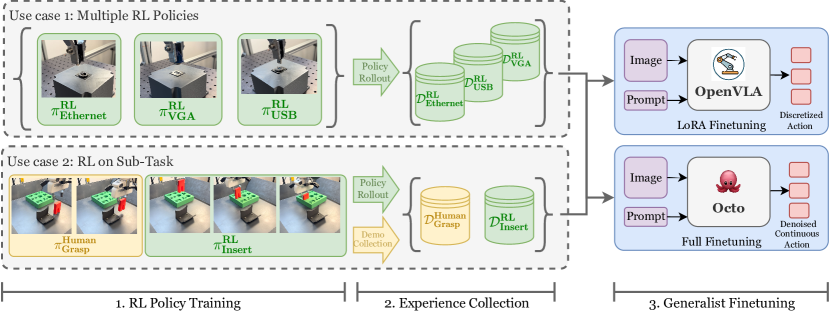
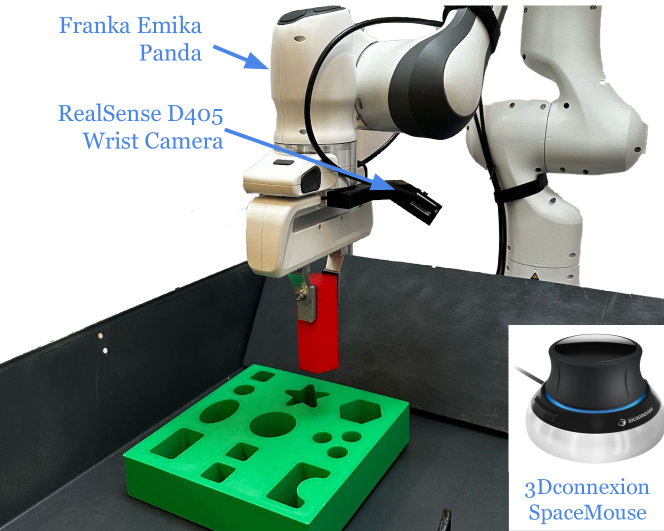

📊 实验亮点
RLDG在真实世界的精确操作任务(如连接器插入和组装)中表现出色,相较于使用人类演示数据训练的通用策略,成功率提升高达40%。此外,RLDG训练的策略在泛化到新任务时也表现出更好的性能,表明该方法能够有效提升通用策略的鲁棒性和适应性。
🎯 应用场景
RLDG方法具有广泛的应用前景,可用于提升各种机器人操作任务的性能,例如工业自动化中的装配、物流中的拣选和放置、以及家庭服务机器人中的复杂操作。通过结合通用策略的灵活性和强化学习的优化能力,RLDG有望推动机器人技术在更广泛的领域得到应用。
📄 摘要(原文)
Recent advances in robotic foundation models have enabled the development of generalist policies that can adapt to diverse tasks. While these models show impressive flexibility, their performance heavily depends on the quality of their training data. In this work, we propose Reinforcement Learning Distilled Generalists (RLDG), a method that leverages reinforcement learning to generate high-quality training data for finetuning generalist policies. Through extensive real-world experiments on precise manipulation tasks like connector insertion and assembly, we demonstrate that generalist policies trained with RL-generated data consistently outperform those trained with human demonstrations, achieving up to 40% higher success rates while generalizing better to new tasks. We also provide a detailed analysis that reveals this performance gain stems from both optimized action distributions and improved state coverage. Our results suggest that combining task-specific RL with generalist policy distillation offers a promising approach for developing more capable and efficient robotic manipulation systems that maintain the flexibility of foundation models while achieving the performance of specialized controllers. Videos and code can be found on our project website https://generalist-distillation.github.io