Should We Learn Contact-Rich Manipulation Policies from Sampling-Based Planners?
作者: Huaijiang Zhu, Tong Zhao, Xinpei Ni, Jiuguang Wang, Kuan Fang, Ludovic Righetti, Tao Pang
分类: cs.RO
发布日期: 2024-12-12 (更新: 2025-04-27)
💡 一句话要点
提出基于采样的规划器改进方法,提升接触丰富操作策略学习效果
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 接触丰富操作 行为克隆 采样规划 扩散模型 机器人学习
📋 核心要点
- 接触丰富的操作任务因其复杂的多点接触协调,难以通过人工遥操作获取高质量的训练数据。
- 该研究改进了基于采样的规划器,通过优先考虑演示数据的一致性来降低数据熵,提升策略学习效果。
- 实验表明,结合扩散模型和行为克隆,该方法能够有效学习策略并实现零样本迁移到真实机器人硬件。
📝 摘要(中文)
行为克隆(BC)在机器人操作中的巨大成功主要局限于可以通过人工遥操作有效收集演示数据的任务。然而,对于需要复杂的多点接触协调的接触丰富操作任务,由于当前遥操作界面的限制,演示数据的收集非常困难。本文研究了如何利用基于模型的规划和优化来生成接触丰富灵巧操作任务的训练数据。分析表明,流行的基于采样的规划器,如快速探索随机树(RRT),虽然在运动规划方面效率很高,但产生的演示数据具有不利的高熵。这促使我们修改数据生成流程,在保持解决方案多样性的同时,优先考虑演示数据的一致性。结合基于扩散的目标条件BC方法,我们的方法能够有效地学习策略,并零样本迁移到硬件上,用于两个具有挑战性的接触丰富操作任务。
🔬 方法详解
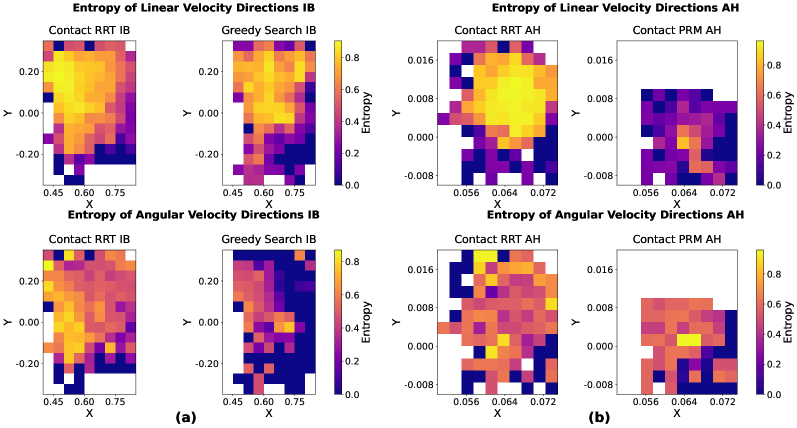
问题定义:现有行为克隆方法在接触丰富的操作任务中面临挑战,因为这些任务的演示数据难以通过人工遥操作获得。基于采样的规划器(如RRT)虽然可以生成轨迹,但其高熵特性导致学习到的策略泛化能力较差,难以在真实环境中应用。
核心思路:论文的核心思路是改进基于采样的规划器,使其生成的演示数据更具一致性,从而降低数据熵。通过优先考虑演示数据的一致性,可以提高行为克隆的学习效率和泛化能力,使得学习到的策略更容易迁移到真实机器人硬件上。
技术框架:整体框架包含三个主要阶段:1) 使用改进的基于采样的规划器生成演示数据;2) 使用扩散模型对生成的数据进行增强;3) 使用行为克隆方法训练目标条件策略。改进的规划器旨在生成更一致的轨迹,扩散模型用于增加数据的多样性,行为克隆则用于学习从状态到动作的映射。
关键创新:最重要的技术创新点在于对基于采样的规划器的改进,使其能够生成更一致的演示数据。与传统的RRT等方法相比,改进后的规划器在探索空间的同时,更加注重已生成轨迹的质量和一致性,从而降低了数据的熵。
关键设计:论文中可能涉及的关键设计包括:1) 用于衡量轨迹一致性的指标;2) 在采样过程中如何平衡探索和一致性;3) 扩散模型的具体结构和训练方式;4) 行为克隆所使用的网络结构和损失函数。具体的参数设置和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片


📊 实验亮点
该方法在两个具有挑战性的接触丰富操作任务上进行了验证,并实现了零样本迁移到真实机器人硬件。实验结果表明,与直接使用RRT生成的演示数据相比,使用改进后的规划器生成的数据训练得到的策略具有更高的成功率和更好的泛化能力。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要复杂接触交互的机器人操作任务,例如灵巧手操作、装配、抓取等。通过改进数据生成流程,可以降低对人工演示数据的依赖,提高机器人自主学习能力,从而在工业自动化、医疗机器人等领域发挥重要作用。未来,该方法有望扩展到更复杂的任务和更广泛的机器人平台。
📄 摘要(原文)
The tremendous success of behavior cloning (BC) in robotic manipulation has been largely confined to tasks where demonstrations can be effectively collected through human teleoperation. However, demonstrations for contact-rich manipulation tasks that require complex coordination of multiple contacts are difficult to collect due to the limitations of current teleoperation interfaces. We investigate how to leverage model-based planning and optimization to generate training data for contact-rich dexterous manipulation tasks. Our analysis reveals that popular sampling-based planners like rapidly exploring random tree (RRT), while efficient for motion planning, produce demonstrations with unfavorably high entropy. This motivates modifications to our data generation pipeline that prioritizes demonstration consistency while maintaining solution diversity. Combined with a diffusion-based goal-conditioned BC approach, our method enables effective policy learning and zero-shot transfer to hardware for two challenging contact-rich manipulation tasks.