Distributional Reinforcement Learning based Integrated Decision Making and Control for Autonomous Surface Vehicles
作者: Xi Lin, Paul Szenher, Yewei Huang, Brendan Englot
分类: cs.RO
发布日期: 2024-12-12
备注: IEEE Robotics and Automation Letters (RA-L)
💡 一句话要点
提出基于分布强化学习的自主水面艇集成决策与控制系统,解决复杂水域导航难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主水面艇 分布强化学习 导航控制 COLREGs 连续动作空间
📋 核心要点
- 现有ASV在复杂水域导航中面临感知误差、船舶密集和空间受限等挑战,难以有效遵守COLREGs。
- 提出基于分布强化学习的导航系统,结合激光雷达和里程计数据,在连续动作空间生成推力指令。
- Gazebo仿真结果表明,该系统能根据场景灵活决策,在导航安全性和效率上优于现有方法。
📝 摘要(中文)
随着近年来对自主水面艇(ASV)的需求不断增长,预计未来部署用于各种海上任务的ASV数量将迅速增加。然而,ASV在充满障碍物和拥挤的航道中执行基于传感器的自主导航仍然具有挑战性,其中感知误差、密集聚集的船只以及浮标附近有限的操纵空间可能会导致难以遵守《国际海上避碰规则公约》(COLREGs)。为了解决这些问题,我们提出了一种基于分布强化学习的新型导航系统,该系统可以与船载激光雷达和里程计传感器协同工作,以在连续动作空间中生成任意推力指令。在高保真Gazebo仿真中对所提出的系统进行的全面评估表明,该系统能够根据遇到的场景决定是遵守COLREGs还是采取其他有益的行动,与使用最先进的分布强化学习、非分布强化学习和经典方法的系统相比,在导航安全性和效率方面提供了卓越的性能。
🔬 方法详解
问题定义:论文旨在解决自主水面艇(ASV)在复杂、拥挤的水域中进行安全高效导航的问题。现有方法,包括传统的控制算法和非分布强化学习方法,在处理感知不确定性、动态环境以及遵守COLREGs方面存在不足,容易导致碰撞或效率低下。这些方法难以在安全性和效率之间取得良好的平衡,尤其是在需要灵活决策的情况下。
核心思路:论文的核心思路是利用分布强化学习(Distributional Reinforcement Learning)来建模环境的不确定性,并学习在不同场景下采取最优行动策略。通过预测回报的分布而不是单一的期望值,该系统能够更好地评估风险,并在遵守COLREGs和采取其他有益行动之间做出权衡。这种方法允许ASV在保证安全的前提下,更灵活地适应复杂环境。
技术框架:该导航系统主要包含以下几个模块:1) 感知模块,利用激光雷达和里程计数据进行环境感知和状态估计;2) 分布强化学习智能体,基于感知信息学习导航策略;3) 动作执行模块,将智能体输出的动作指令转化为ASV的推力控制指令。整体流程是:感知模块获取环境信息,传递给分布强化学习智能体,智能体根据当前状态选择动作,动作执行模块将动作转化为推力指令控制ASV运动。
关键创新:该论文的关键创新在于将分布强化学习应用于ASV的导航控制。与传统的强化学习方法不同,分布强化学习能够学习回报的完整分布,从而更好地处理环境的不确定性。这使得ASV能够更准确地评估风险,并在安全性和效率之间做出更明智的决策。此外,该系统能够直接输出连续动作空间中的推力指令,避免了离散动作空间带来的局限性。
关键设计:该系统使用C51算法作为分布强化学习的基础,网络结构采用深度神经网络,输入包括激光雷达扫描数据和里程计信息,输出是推力指令。损失函数基于C51算法的分类交叉熵损失,用于训练神经网络。奖励函数的设计考虑了安全性(避免碰撞)、效率(尽快到达目标)和遵守COLREGs三个方面。具体参数设置未知。
🖼️ 关键图片

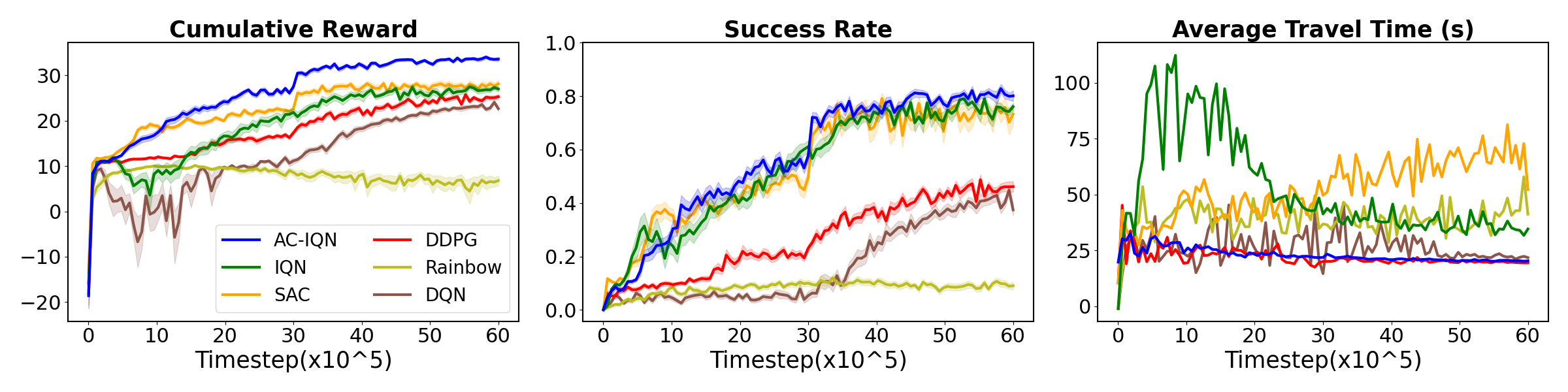
📊 实验亮点
在高保真Gazebo仿真中,该系统与基于传统强化学习(非分布强化学习)和经典控制方法的系统进行了对比。实验结果表明,该系统在导航安全性和效率方面均优于其他方法。具体而言,该系统能够更有效地避免碰撞,并更快地到达目标,同时更好地遵守COLREGs。具体的性能提升数据未知。
🎯 应用场景
该研究成果可广泛应用于自主水面艇的各种任务,例如港口巡逻、环境监测、搜救行动和货物运输。通过提高ASV在复杂水域的导航安全性和效率,该系统能够降低运营成本,减少人为干预,并提高任务的可靠性。未来,该技术有望推动智能航运和海洋工程的发展。
📄 摘要(原文)
With the growing demands for Autonomous Surface Vehicles (ASVs) in recent years, the number of ASVs being deployed for various maritime missions is expected to increase rapidly in the near future. However, it is still challenging for ASVs to perform sensor-based autonomous navigation in obstacle-filled and congested waterways, where perception errors, closely gathered vehicles and limited maneuvering space near buoys may cause difficulties in following the Convention on the International Regulations for Preventing Collisions at Sea (COLREGs). To address these issues, we propose a novel Distributional Reinforcement Learning based navigation system that can work with onboard LiDAR and odometry sensors to generate arbitrary thrust commands in continuous action space. Comprehensive evaluations of the proposed system in high-fidelity Gazebo simulations show its ability to decide whether to follow COLREGs or take other beneficial actions based on the scenarios encountered, offering superior performance in navigation safety and efficiency compared to systems using state-of-the-art Distributional RL, non-Distributional RL and classical methods.