Learning to Adapt through Bio-Inspired Gait Strategies for Versatile Quadruped Locomotion
作者: Joseph Humphreys, Chengxu Zhou
分类: cs.RO
发布日期: 2024-12-12 (更新: 2025-06-22)
备注: 19 pages, 8 figures, journal paper
💡 一句话要点
提出一种生物启发式步态策略,提升四足机器人复杂地形的适应性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 步态控制 深度强化学习 生物启发式 零样本学习
📋 核心要点
- 现有四足机器人运动控制方法依赖固定步态,难以适应复杂地形和动态变化。
- 该论文提出一种生物启发式DRL控制框架,融合步态转换、记忆和实时调整策略。
- 实验表明,该框架在真实地形上实现了零样本部署,性能显著优于基线控制器。
📝 摘要(中文)
腿足机器人必须适应步态才能在不可预测的环境中导航,这是动物可以轻松掌握的挑战。然而,大多数四足机器人运动的深度强化学习(DRL)方法依赖于固定的步态,限制了对地形和动态状态变化的适应性。本文表明,整合动物运动的三个核心原则——步态转换策略、步态记忆和实时运动调整,能够使DRL控制框架在多种步态之间流畅切换并从不稳定状态中恢复,所有这些都无需外部传感。该框架由生物力学启发的指标指导,这些指标捕获效率、稳定性和系统限制,并统一起来以告知最佳步态选择。由此产生的框架实现了在各种真实地形上的盲零样本部署,并且显著优于基线控制器。通过将生物学原理嵌入到数据驱动的控制中,这项工作标志着朝着鲁棒、高效和通用的机器人运动迈出了一步,突出了动物运动智能如何塑造下一代自适应机器。
🔬 方法详解
问题定义:现有四足机器人运动控制方法主要依赖于固定的步态模式,这使得它们在面对复杂、崎岖或动态变化的地形时,适应能力严重不足。这些方法通常需要大量的环境感知信息,并且难以在真实世界中实现鲁棒的零样本泛化。因此,如何使四足机器人能够像动物一样,根据环境和自身状态灵活地切换步态,是本研究要解决的核心问题。
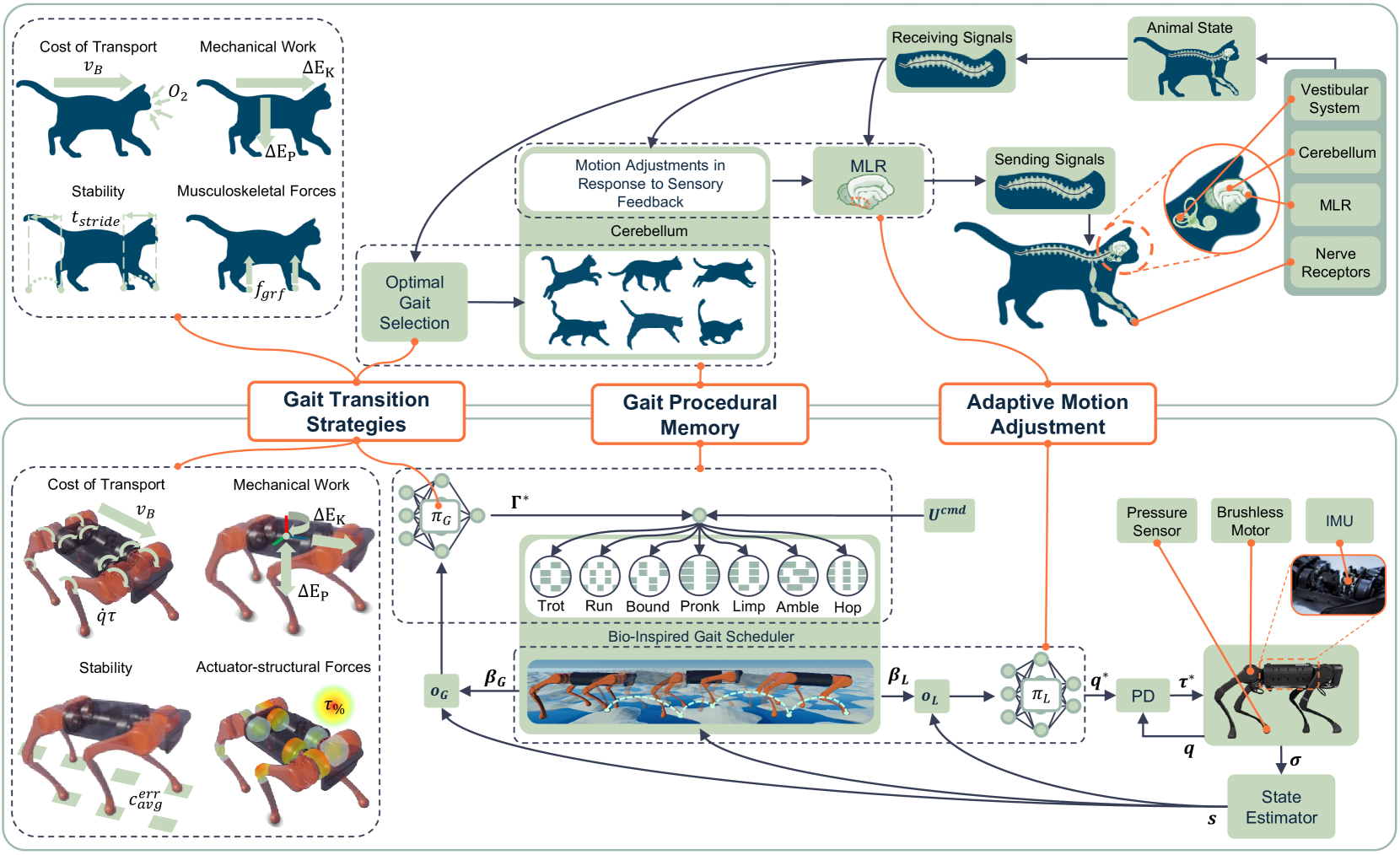
核心思路:该论文的核心思路是借鉴动物运动的生物学原理,将这些原理融入到深度强化学习的控制框架中。具体来说,它模拟了动物的步态转换策略、步态记忆以及实时运动调整能力,使得机器人能够根据自身状态和环境变化,动态地选择和调整步态。这种生物启发式的设计旨在提高机器人的适应性和鲁棒性,使其能够在未知环境中实现高效稳定的运动。
技术框架:该框架主要包含以下几个模块:1) 基于DRL的运动控制器,负责生成低级别的动作指令;2) 步态选择模块,根据生物力学启发的指标(如效率、稳定性和系统限制)来选择合适的步态;3) 步态记忆模块,用于存储和回忆历史步态信息,从而实现更平滑的步态转换;4) 实时运动调整模块,根据实时的状态反馈对运动轨迹进行微调,以应对突发情况。这些模块协同工作,使得机器人能够实现灵活的步态切换和运动控制。
关键创新:该论文最重要的技术创新点在于将生物学原理与深度强化学习相结合,提出了一种生物启发式的步态控制框架。与传统的基于固定步态的控制方法相比,该框架能够根据环境和自身状态动态地选择和调整步态,从而显著提高了机器人的适应性和鲁棒性。此外,该框架无需外部传感器,仅依靠本体感知即可实现零样本泛化,这大大降低了部署成本和复杂性。
关键设计:在步态选择模块中,论文设计了一系列生物力学启发的指标,用于评估不同步态的性能。这些指标包括能量消耗、稳定性裕度和关节力矩限制等。通过将这些指标统一到一个优化目标中,可以实现最佳的步态选择。此外,在DRL训练过程中,论文采用了课程学习策略,逐步增加环境的复杂性,从而提高了模型的泛化能力。具体的网络结构和损失函数细节未知。
🖼️ 关键图片
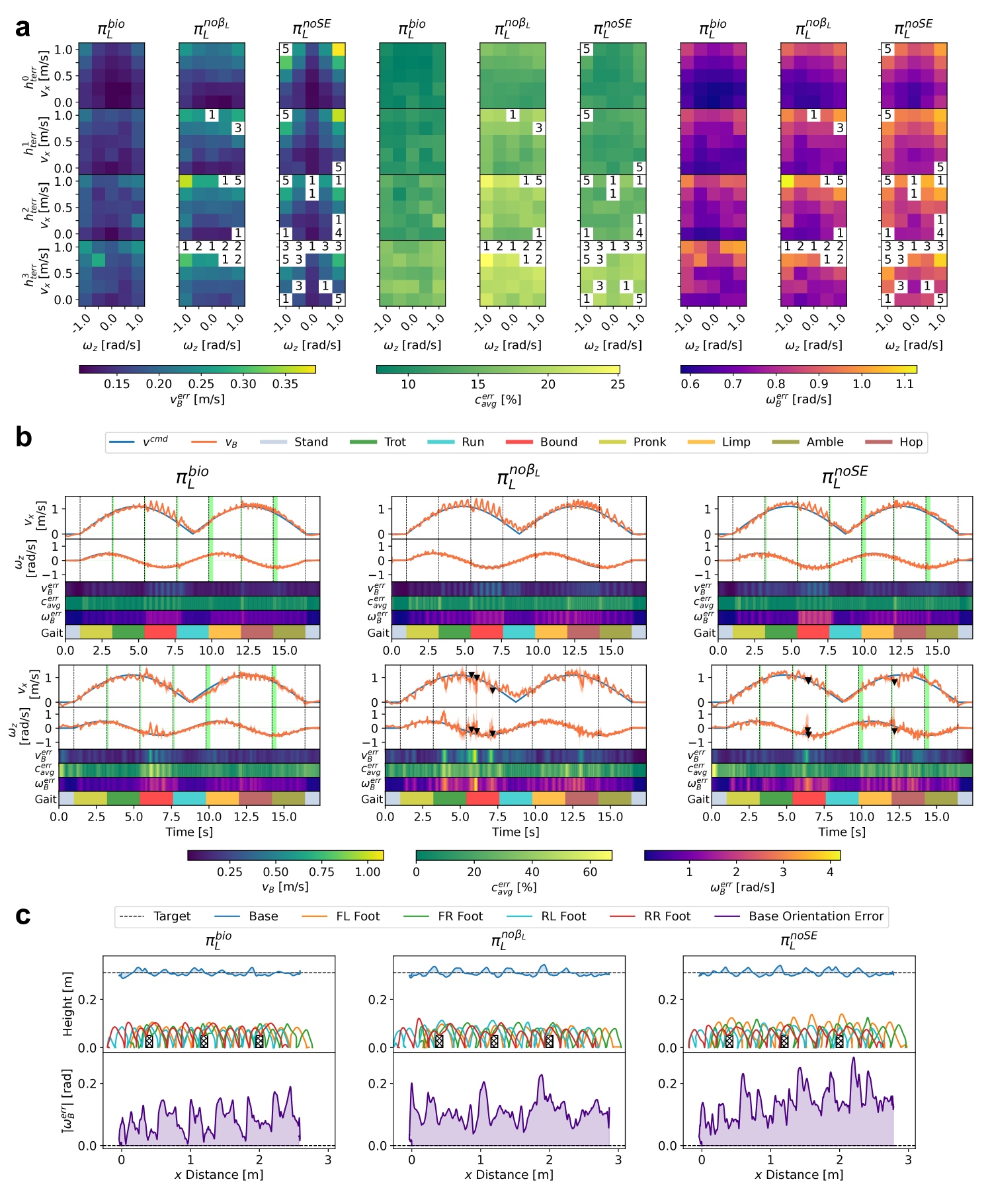
📊 实验亮点
该研究提出的生物启发式控制框架在多种真实地形上实现了盲零样本部署,无需任何微调。实验结果表明,该框架在复杂地形上的运动效率和稳定性显著优于传统的基于固定步态的控制器。具体的性能提升数据未知,但摘要中明确指出是“substantially significantly outperforms baseline controllers”。
🎯 应用场景
该研究成果可应用于搜救、勘探、物流等领域。在灾难现场,四足机器人可以利用其强大的地形适应能力,进入人类难以到达的区域进行搜索和救援。在复杂地形的勘探任务中,机器人可以自主导航并收集数据。此外,该技术还可以用于开发更智能、更高效的物流机器人,提高仓储和配送效率。未来,该研究有望推动腿足机器人技术的发展,使其在更多领域发挥重要作用。
📄 摘要(原文)
Legged robots must adapt their gait to navigate unpredictable environments, a challenge that animals master with ease. However, most deep reinforcement learning (DRL) approaches to quadruped locomotion rely on a fixed gait, limiting adaptability to changes in terrain and dynamic state. Here we show that integrating three core principles of animal locomotion-gait transition strategies, gait memory and real-time motion adjustments enables a DRL control framework to fluidly switch among multiple gaits and recover from instability, all without external sensing. Our framework is guided by biomechanics-inspired metrics that capture efficiency, stability and system limits, which are unified to inform optimal gait selection. The resulting framework achieves blind zero-shot deployment across diverse, real-world terrains and substantially significantly outperforms baseline controllers. By embedding biological principles into data-driven control, this work marks a step towards robust, efficient and versatile robotic locomotion, highlighting how animal motor intelligence can shape the next generation of adaptive machines.