3DTTNet: Multimodal Fusion-Based 3D Traversable Terrain Modeling for Off-Road Environments
作者: Zitong Chen, Chao Sun, Shida Nie, Chen Min, Changjiu Ning, Haoyu Li, Bo Wang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-12-11 (更新: 2025-08-06)
备注: 15 pages,13 figures
💡 一句话要点
提出3DTTNet,通过多模态融合进行越野环境下的3D可通行地形建模。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景补全 多模态融合 可通行性分析 越野环境 无人地面车辆
📋 核心要点
- 传统感知算法在非结构化环境中表现不佳,难以应对越野环境中的复杂地形和障碍物。
- 3DTTNet融合激光雷达和单目图像,通过语义场景补全生成密集的通行地形估计,增强环境特征提取。
- 实验表明,3DTTNet在3D可通行区域识别方面显著优于现有方法,场景补全IoU提升达42%。
📝 摘要(中文)
本文针对非结构化道路和复杂障碍物(如不平坦地形、植被和遮挡)给无人地面车辆带来的挑战,提出了一种基于语义场景补全的可通行区域识别方法。论文提出了一种新颖的多模态方法3DTTNet,通过融合激光雷达点云和前视单目图像来生成密集的通行地形估计,从而增强环境特征提取,这对于复杂地形中的精确地形建模至关重要。此外,论文还引入了带有3D可通行性标注的数据集RELLIS-OCC,其中包含了诸如阶梯高度、坡度和不平整度等几何特征。通过全面分析车辆的障碍物跨越条件并结合车辆车身结构约束,生成了四种可通行性成本标签:致命、中等成本、低成本和自由。实验结果表明,3DTTNet在3D可通行区域识别方面优于其他方法,尤其是在具有不规则几何形状和部分遮挡的越野环境中。具体而言,3DTTNet在场景补全IoU方面比其他模型提高了42%。该框架具有可扩展性,可适应各种车辆平台,允许调整占用网格参数以及集成高级动态模型以进行可通行性成本估计。
🔬 方法详解
问题定义:论文旨在解决越野环境下无人地面车辆(UGV)难以准确感知可通行区域的问题。现有方法主要依赖于为结构化道路设计的感知算法,在非结构化环境中,由于地形崎岖、植被遮挡等因素,导致感知精度大幅下降,影响UGV的自主导航能力。
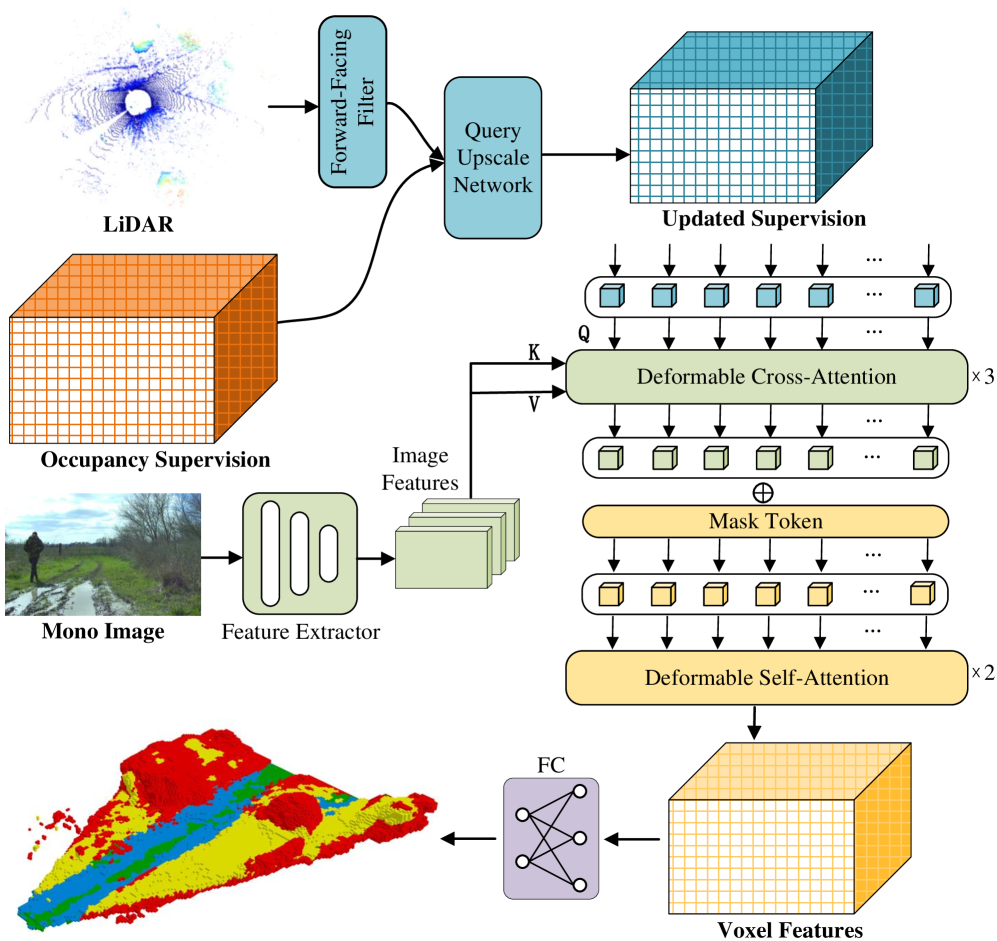
核心思路:论文的核心思路是利用多模态融合,将激光雷达点云提供的几何信息与单目图像提供的纹理信息相结合,互补彼此的不足,从而更全面地提取环境特征。通过语义场景补全技术,将稀疏的激光雷达点云补全为密集的3D场景表示,并结合图像信息进行可通行性分析。
技术框架:3DTTNet的整体框架包含以下几个主要模块:1) 多模态数据输入:接收激光雷达点云和单目图像;2) 特征提取:分别从点云和图像中提取特征;3) 特征融合:将提取的特征进行融合,增强环境信息的表达;4) 语义场景补全:利用融合后的特征进行3D场景补全,生成密集的3D场景表示;5) 可通行性分析:基于补全的3D场景,结合车辆结构约束和地形特征,评估每个区域的可通行性成本,生成可通行性地图。
关键创新:论文的关键创新在于多模态融合策略和可通行性成本评估方法。多模态融合能够有效利用不同传感器数据的优势,提高环境感知的鲁棒性和准确性。可通行性成本评估方法综合考虑了车辆的物理约束和地形特征,能够更准确地评估地形的可通行性。
关键设计:论文的关键设计包括:1) 特征融合方式:采用了何种具体的特征融合方法(例如,注意力机制、级联等),以有效结合不同模态的特征;2) 损失函数设计:设计了针对语义场景补全和可通行性成本评估的损失函数,以优化模型的性能;3) 数据集构建:构建了包含3D可通行性标注的RELLIS-OCC数据集,为模型的训练和评估提供了数据支持。
🖼️ 关键图片


📊 实验亮点
实验结果表明,3DTTNet在RELLIS-OCC数据集上取得了显著的性能提升。与现有方法相比,3DTTNet在场景补全IoU指标上提高了42%,表明其能够更准确地重建越野环境的3D结构。此外,3DTTNet在可通行区域识别方面也表现出优越的性能,能够更准确地判断地形的可通行性,为UGV的自主导航提供可靠的依据。
🎯 应用场景
该研究成果可应用于各种越野环境下的无人地面车辆,例如农业机器人、搜救机器人、军事侦察车辆等。通过提高UGV在复杂地形中的自主导航能力,可以降低人工干预的需求,提高工作效率和安全性。未来,该技术还可以扩展到其他类型的机器人平台,例如无人飞行器和水下机器人。
📄 摘要(原文)
Off-road environments remain significant challenges for autonomous ground vehicles, due to the lack of structured roads and the presence of complex obstacles, such as uneven terrain, vegetation, and occlusions. Traditional perception algorithms, primarily designed for structured environments, often fail in unstructured scenarios. In this paper, traversable area recognition is achieved through semantic scene completion. A novel multimodal method, 3DTTNet, is proposed to generate dense traversable terrain estimations by integrating LiDAR point clouds with monocular images from a forward-facing perspective. By integrating multimodal data, environmental feature extraction is strengthened, which is crucial for accurate terrain modeling in complex terrains. Furthermore, RELLIS-OCC, a dataset with 3D traversable annotations, is introduced, incorporating geometric features such as step height, slope, and unevenness. Through a comprehensive analysis of vehicle obsta cle-crossing conditions and the incorporation of vehicle body structure constraints, four traversability cost labels are generated: lethal, medium-cost, low-cost, and free. Experimental results demonstrate that 3DTTNet outperforms the comparison approaches in 3D traversable area recognition, particularly in off-road environments with irregular geometries and partial occlusions. Specifically, 3DTTNet achieves a 42\% improvement in scene completion IoU compared to other models. The proposed framework is scalable and adaptable to various vehicle platforms, allowing for adjustments to occupancy grid parameters and the integration of advanced dynamic models for traversability cost estimation.