Progressive-Resolution Policy Distillation: Leveraging Coarse-Resolution Simulations for Time-Efficient Fine-Resolution Policy Learning
作者: Yuki Kadokawa, Hirotaka Tahara, Takamitsu Matsubara
分类: cs.RO, cs.LG
发布日期: 2024-12-10 (更新: 2025-07-22)
备注: accepted for IEEE Transactions on Automation Science and Engineering (T-ASE)
期刊: IEEE Transactions on Automation Science and Engineering 2025
DOI: 10.1109/TASE.2025.3590068
💡 一句话要点
提出渐进分辨率策略蒸馏,加速挖掘机岩石挖掘任务中的强化学习策略训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 策略蒸馏 分辨率策略 岩石挖掘 模拟仿真
📋 核心要点
- 挖掘机在土方工程中常遇到岩石,需要熟练操作员。现有强化学习方法在高分辨率模拟中训练策略成本高昂。
- 论文提出渐进分辨率策略蒸馏(PRPD),通过在不同分辨率模拟中逐步迁移策略,加速高分辨率策略学习。
- 实验表明,PRPD在保持任务成功率的同时,显著减少了采样时间,验证了其在岩石挖掘任务中的有效性。
📝 摘要(中文)
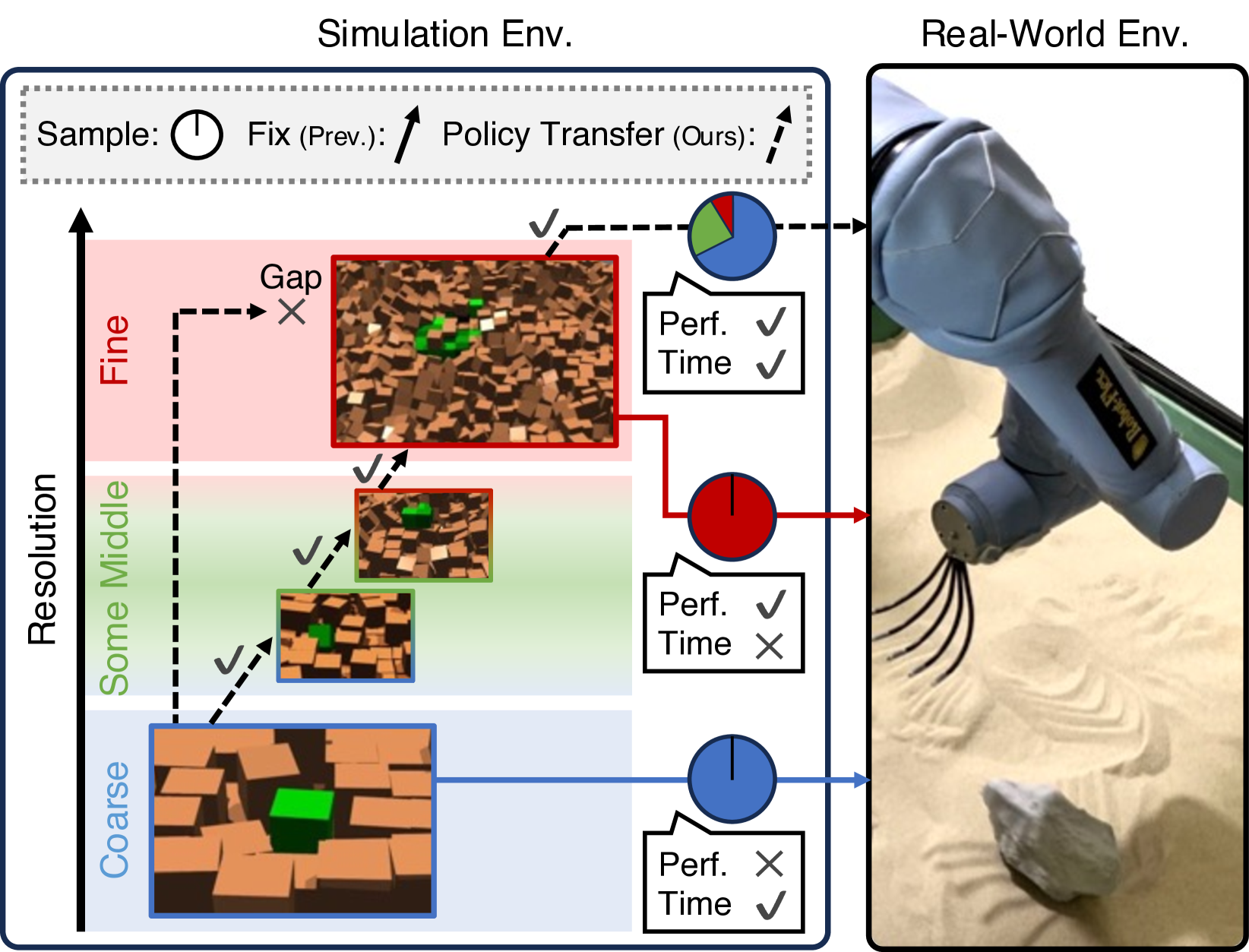
本文提出了一种用于挖掘机自主挖掘的强化学习框架,特别针对岩石挖掘场景。该框架利用岩石挖掘模拟器,通过调整模拟器中粒子大小/数量来定义分辨率。高分辨率模拟更接近真实环境,但计算成本高,样本收集困难;低分辨率模拟样本收集快,但与真实环境存在偏差。为了结合两者的优点,本文探索了使用低分辨率模拟中训练的策略来预训练高分辨率模拟中的策略。为此,提出了一种名为渐进分辨率策略蒸馏(PRPD)的新策略学习框架,通过一系列中间分辨率模拟进行保守的策略迁移,避免因领域差异导致的策略迁移失败。在岩石挖掘模拟器和九个真实岩石环境中的验证表明,PRPD在保持与高分辨率模拟策略学习相当的任务成功率的同时,将采样时间减少到1/7以下。
🔬 方法详解
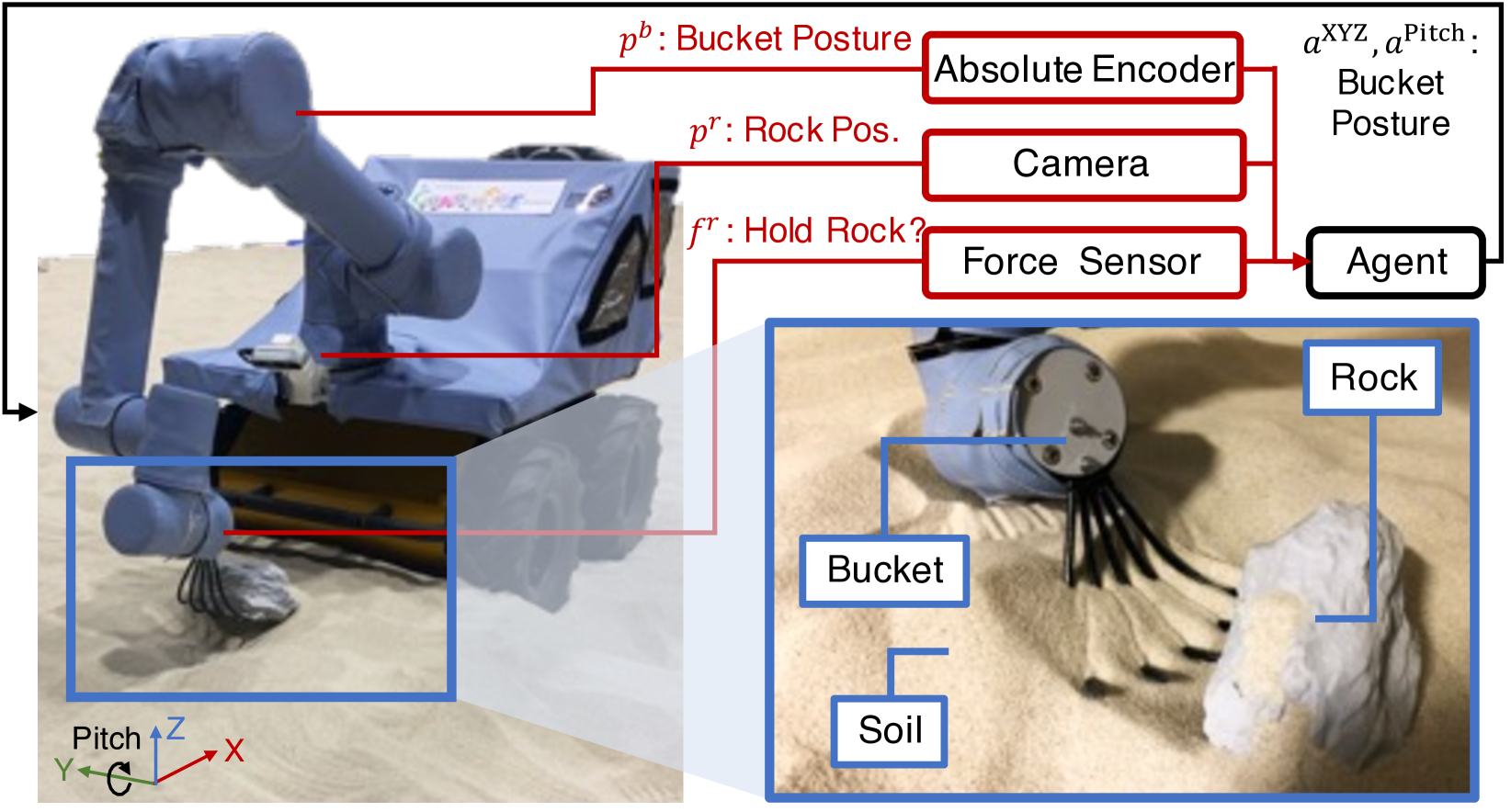
问题定义:挖掘机在复杂土石环境下的自主挖掘是一个具有挑战性的强化学习问题。直接在高分辨率的真实感模拟环境中训练策略,计算成本巨大,采样效率低下,难以在实际应用中推广。而低分辨率模拟虽然计算速度快,但与真实环境的差异较大,导致训练出的策略难以直接迁移到真实环境。
核心思路:论文的核心思路是利用低分辨率模拟快速生成初始策略,然后通过一系列中间分辨率的模拟环境,逐步将策略迁移到高分辨率的模拟环境中。这种渐进式的策略迁移可以有效避免因领域差异过大导致的策略崩溃,同时也能充分利用低分辨率模拟的计算优势。
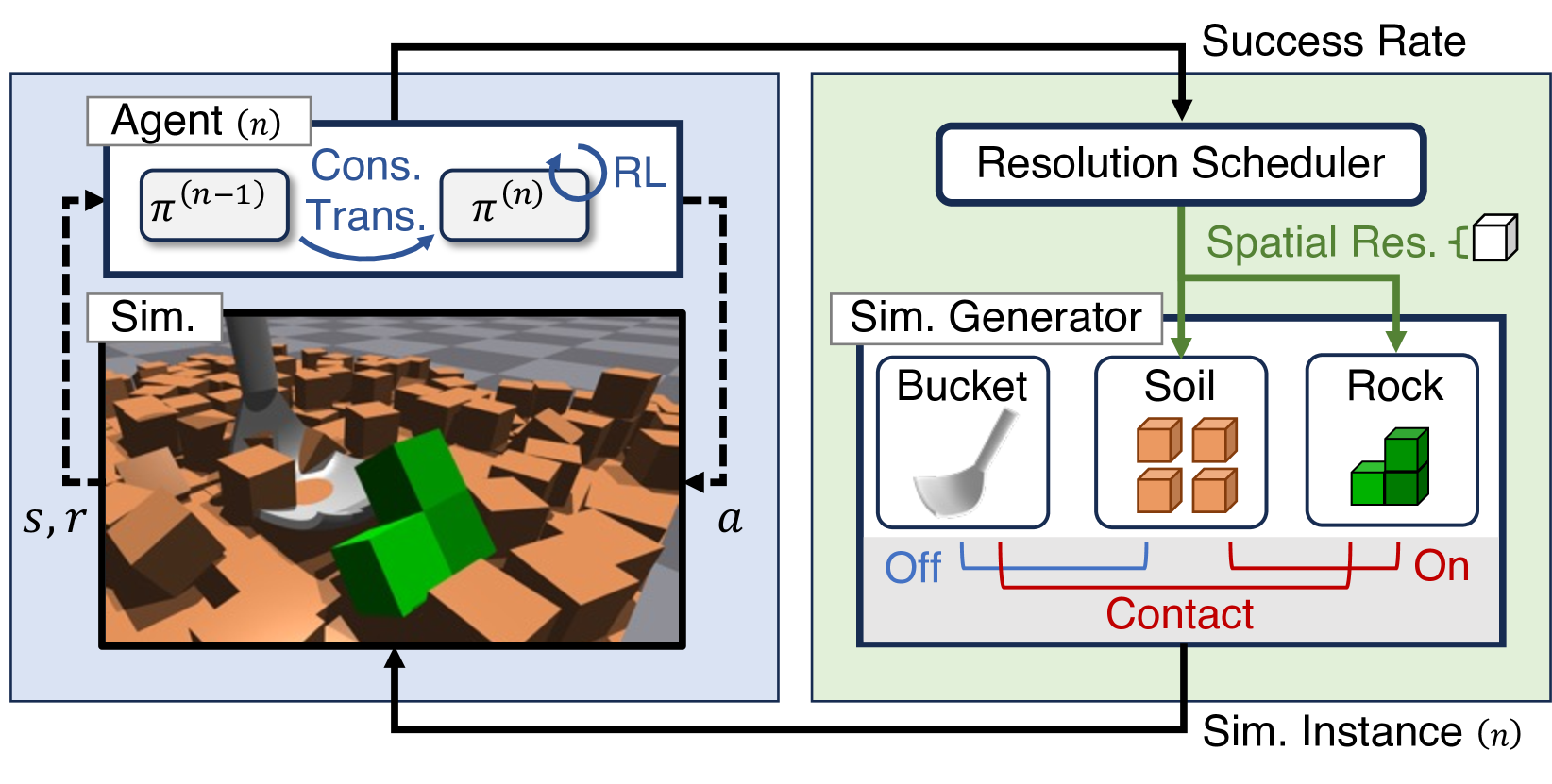
技术框架:PRPD框架包含以下几个主要阶段:1) 在低分辨率模拟环境中训练初始策略;2) 定义一系列中间分辨率的模拟环境;3) 采用保守策略迁移方法,将策略从低分辨率环境逐步迁移到高分辨率环境。在每个分辨率级别,使用蒸馏方法将先前分辨率的策略知识迁移到当前分辨率的策略中;4) 在高分辨率模拟环境中对最终策略进行微调。
关键创新:PRPD的关键创新在于其渐进式的分辨率策略迁移方法。与直接在高分辨率环境训练或直接从低分辨率环境迁移策略相比,PRPD通过逐步缩小模拟环境与真实环境之间的差距,有效避免了策略迁移失败的问题。此外,保守策略迁移策略保证了策略在迁移过程中的稳定性。
关键设计:PRPD的关键设计包括:1) 分辨率级别的选择:需要根据具体任务和模拟器的特性,合理选择中间分辨率的数量和级别;2) 保守策略迁移方法:论文可能采用了如KL散度约束等方法,限制策略在迁移过程中的变化幅度,保证策略的稳定性;3) 蒸馏损失函数的设计:用于衡量不同分辨率策略之间的差异,指导策略迁移过程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PRPD方法在保持与高分辨率模拟策略学习相当的任务成功率的同时,将采样时间减少到1/7以下。在九个真实岩石环境中的验证进一步证明了该方法在实际应用中的有效性和泛化能力。这些结果表明,PRPD是一种高效且实用的强化学习策略训练方法。
🎯 应用场景
该研究成果可应用于建筑、矿业等领域的自动化挖掘设备。通过降低强化学习策略训练的计算成本,加速算法落地,提高挖掘效率和安全性,减少对人工操作的依赖。未来可扩展到其他复杂环境下的机器人控制任务,例如自动驾驶、农业机器人等。
📄 摘要(原文)
In earthwork and construction, excavators often encounter large rocks mixed with various soil conditions, requiring skilled operators. This paper presents a framework for achieving autonomous excavation using reinforcement learning (RL) through a rock excavation simulator. In the simulation, resolution can be defined by the particle size/number in the whole soil space. Fine-resolution simulations closely mimic real-world behavior but demand significant calculation time and challenging sample collection, while coarse-resolution simulations enable faster sample collection but deviate from real-world behavior. To combine the advantages of both resolutions, we explore using policies developed in coarse-resolution simulations for pre-training in fine-resolution simulations. To this end, we propose a novel policy learning framework called Progressive-Resolution Policy Distillation (PRPD), which progressively transfers policies through some middle-resolution simulations with conservative policy transfer to avoid domain gaps that could lead to policy transfer failure. Validation in a rock excavation simulator and nine real-world rock environments demonstrated that PRPD reduced sampling time to less than 1/7 while maintaining task success rates comparable to those achieved through policy learning in a fine-resolution simulation.