CARP: Visuomotor Policy Learning via Coarse-to-Fine Autoregressive Prediction
作者: Zhefei Gong, Pengxiang Ding, Shangke Lyu, Siteng Huang, Mingyang Sun, Wei Zhao, Zhaoxin Fan, Donglin Wang
分类: cs.RO, cs.CV
发布日期: 2024-12-09 (更新: 2025-08-10)
💡 一句话要点
CARP:通过粗到细自回归预测学习机器人视觉运动策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉运动策略学习 自回归模型 粗到细预测 机器人控制 动作生成
📋 核心要点
- 现有基于扩散的视觉运动策略模型,虽然精度高,但由于多次去噪步骤导致效率低下,且复杂约束限制了灵活性。
- CARP将动作生成分解为多尺度表示学习和粗到细的自回归细化两个阶段,旨在提高动作生成效率和精度。
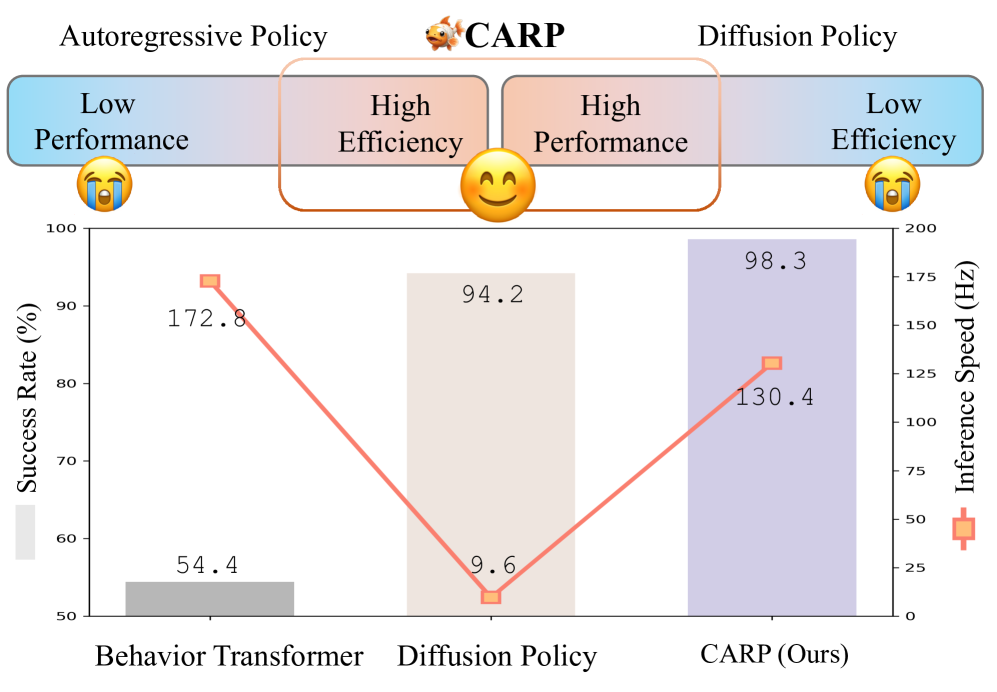
- 实验结果表明,CARP在各种任务中实现了具有竞争力的成功率,推理速度比现有方法快10倍,性能提升高达10%。
📝 摘要(中文)
在机器人视觉运动策略学习中,基于扩散的模型在提高动作轨迹生成精度方面优于传统的自回归模型。然而,由于多次去噪步骤和复杂约束带来的有限灵活性,它们效率较低。本文提出了一种新的视觉运动策略学习范式——粗到细自回归策略(CARP),它将自回归动作生成过程重新定义为一种粗到细的、下一尺度的逼近方法。CARP将动作生成解耦为两个阶段:首先,一个动作自编码器学习整个动作序列的多尺度表示;然后,一个GPT风格的Transformer通过粗到细的自回归过程细化序列预测。这种直接且直观的方法能够生成高度精确和平滑的动作,在保持与自回归策略相当的效率的同时,达到甚至超过基于扩散的策略的性能。我们在各种设置下进行了广泛的评估,包括基于状态和基于图像的模拟基准上的单任务和多任务场景,以及真实世界的任务。CARP实现了具有竞争力的成功率,提升高达10%,并提供比最先进策略快10倍的推理速度,从而为机器人任务中的动作生成建立了一个高性能、高效且灵活的范式。
🔬 方法详解
问题定义:论文旨在解决机器人视觉运动策略学习中,现有基于扩散模型的方法效率低下的问题。扩散模型虽然能生成更准确的动作轨迹,但其多次去噪过程耗时,且难以处理复杂约束,限制了其在实际机器人应用中的潜力。
核心思路:CARP的核心思路是将动作生成过程解耦为两个阶段:首先学习动作序列的多尺度表示,然后通过粗到细的自回归过程逐步细化预测。这种方式旨在结合自回归模型的效率和扩散模型的精度,同时提高对复杂约束的适应性。
技术框架:CARP包含两个主要模块:动作自编码器和GPT风格的Transformer。动作自编码器负责学习动作序列的多尺度表示,将原始动作序列编码成一系列不同尺度的潜在向量。GPT风格的Transformer则利用这些多尺度表示,通过粗到细的自回归方式预测后续的动作序列。整个流程可以概括为:输入视觉信息和历史动作,通过自编码器提取多尺度特征,然后Transformer利用这些特征进行自回归预测。
关键创新:CARP的关键创新在于其粗到细的自回归预测范式。与传统的自回归模型直接预测下一个动作不同,CARP首先预测一个粗略的动作序列,然后逐步细化,从而更好地捕捉动作序列的整体结构和长期依赖关系。这种方法结合了自回归模型的效率和扩散模型的精度,同时避免了扩散模型复杂的去噪过程。
关键设计:动作自编码器采用卷积神经网络结构,用于提取动作序列的多尺度特征。GPT风格的Transformer采用标准的Transformer架构,并针对动作预测任务进行了优化。损失函数包括重构损失和预测损失,用于训练自编码器和Transformer。在训练过程中,采用了数据增强技术,以提高模型的泛化能力。具体的参数设置(如卷积核大小、Transformer层数等)根据不同的任务进行调整。
🖼️ 关键图片

📊 实验亮点
CARP在多个模拟和真实世界的机器人任务中进行了评估,结果表明其性能优于现有的自回归和扩散模型。在成功率方面,CARP实现了高达10%的提升。更重要的是,CARP的推理速度比最先进的策略快10倍,这使得它在实际应用中更具优势。这些结果证明了CARP在机器人视觉运动策略学习方面的有效性和效率。
🎯 应用场景
CARP具有广泛的应用前景,可应用于各种机器人任务,如机械臂操作、自动驾驶、无人机控制等。其高效的推理速度和高精度使其特别适用于需要实时性和准确性的场景。未来,CARP可以进一步扩展到更复杂的任务,例如多智能体协作和人机交互。
📄 摘要(原文)
In robotic visuomotor policy learning, diffusion-based models have achieved significant success in improving the accuracy of action trajectory generation compared to traditional autoregressive models. However, they suffer from inefficiency due to multiple denoising steps and limited flexibility from complex constraints. In this paper, we introduce Coarse-to-Fine AutoRegressive Policy (CARP), a novel paradigm for visuomotor policy learning that redefines the autoregressive action generation process as a coarse-to-fine, next-scale approach. CARP decouples action generation into two stages: first, an action autoencoder learns multi-scale representations of the entire action sequence; then, a GPT-style transformer refines the sequence prediction through a coarse-to-fine autoregressive process. This straightforward and intuitive approach produces highly accurate and smooth actions, matching or even surpassing the performance of diffusion-based policies while maintaining efficiency on par with autoregressive policies. We conduct extensive evaluations across diverse settings, including single-task and multi-task scenarios on state-based and image-based simulation benchmarks, as well as real-world tasks. CARP achieves competitive success rates, with up to a 10% improvement, and delivers 10x faster inference compared to state-of-the-art policies, establishing a high-performance, efficient, and flexible paradigm for action generation in robotic tasks.