On-Device Self-Supervised Learning of Low-Latency Monocular Depth from Only Events
作者: Jesse Hagenaars, Yilun Wu, Federico Paredes-Vallés, Stein Stroobants, Guido de Croon
分类: cs.RO, cs.CV
发布日期: 2024-12-09 (更新: 2025-03-25)
备注: Accepted at CVPR 2025
💡 一句话要点
提出一种低延迟单目深度估计的设备端自监督学习方法,适用于资源受限的敏捷机器人。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 自监督学习 单目深度估计 设备端学习 低延迟 机器人视觉 对比度最大化
📋 核心要点
- 现有方法难以在资源受限的机器人上实现高效的事件相机数据自监督学习,尤其是在线学习。
- 该论文通过改进对比度最大化流程,提升了时间和内存效率,从而实现了设备端的低延迟单目深度学习。
- 实验表明,在线学习能提升深度估计精度和避障效果,并在自监督方法中达到领先的深度估计性能。
📝 摘要(中文)
本文提出了一种基于事件相机的低延迟单目深度估计的设备端自监督学习方法。事件相机以极低的功耗提供低延迟感知,非常适合小型无人机等资源受限的敏捷机器人。基于对比度最大化的自监督学习在基于事件的机器人视觉中具有巨大潜力,因为它无需高频ground truth,并允许在机器人的运行环境中进行在线学习。然而,在线、板载学习面临着在保持有竞争力的视觉感知性能的同时,实现足够计算效率以进行实时学习的重大挑战。本文改进了对比度最大化流程的时间和内存效率,使得在设备上学习低延迟单目深度成为可能。实验表明,与仅进行预训练相比,在小型无人机上进行在线学习可以产生更准确的深度估计和更成功的避障行为。基准测试实验表明,所提出的流程不仅高效,而且在自监督方法中实现了最先进的深度估计性能。这项工作挖掘了在线、设备端机器人学习的未开发潜力,有望缩小现实差距并提高性能。
🔬 方法详解
问题定义:论文旨在解决资源受限的敏捷机器人(如小型无人机)上,如何利用事件相机进行低延迟、高精度的单目深度估计的问题。现有方法通常计算效率较低,难以在设备端进行在线自监督学习,导致部署困难和泛化能力不足。
核心思路:论文的核心思路是通过改进对比度最大化流程,降低计算复杂度和内存占用,从而使事件相机的自监督学习能够在资源受限的设备上实时进行。通过在线学习,模型能够适应机器人运行环境的特定特征,提高深度估计的准确性和鲁棒性。
技术框架:整体框架包含事件数据的预处理、特征提取、深度估计网络以及对比度最大化损失函数。事件数据首先被转换为体素网格或事件图像,然后输入到深度估计网络中。网络输出的深度图用于计算对比度损失,并反向传播以更新网络参数。关键在于优化了整个流程,使其能够在设备端实时运行。
关键创新:论文的关键创新在于对对比度最大化流程的优化,使其能够在计算资源有限的设备上高效运行。具体包括:1) 降低了特征提取的计算复杂度;2) 优化了深度估计网络的结构,减少了参数量;3) 改进了对比度损失的计算方法,降低了内存占用。
关键设计:论文中可能包含以下关键设计:1) 使用轻量级的卷积神经网络作为深度估计网络;2) 设计了一种高效的事件数据表示方法,例如稀疏体素网格;3) 采用了一种改进的对比度损失函数,例如基于互信息的损失函数,以提高深度估计的准确性;4) 针对特定硬件平台进行了优化,例如使用TensorRT进行推理加速。
🖼️ 关键图片
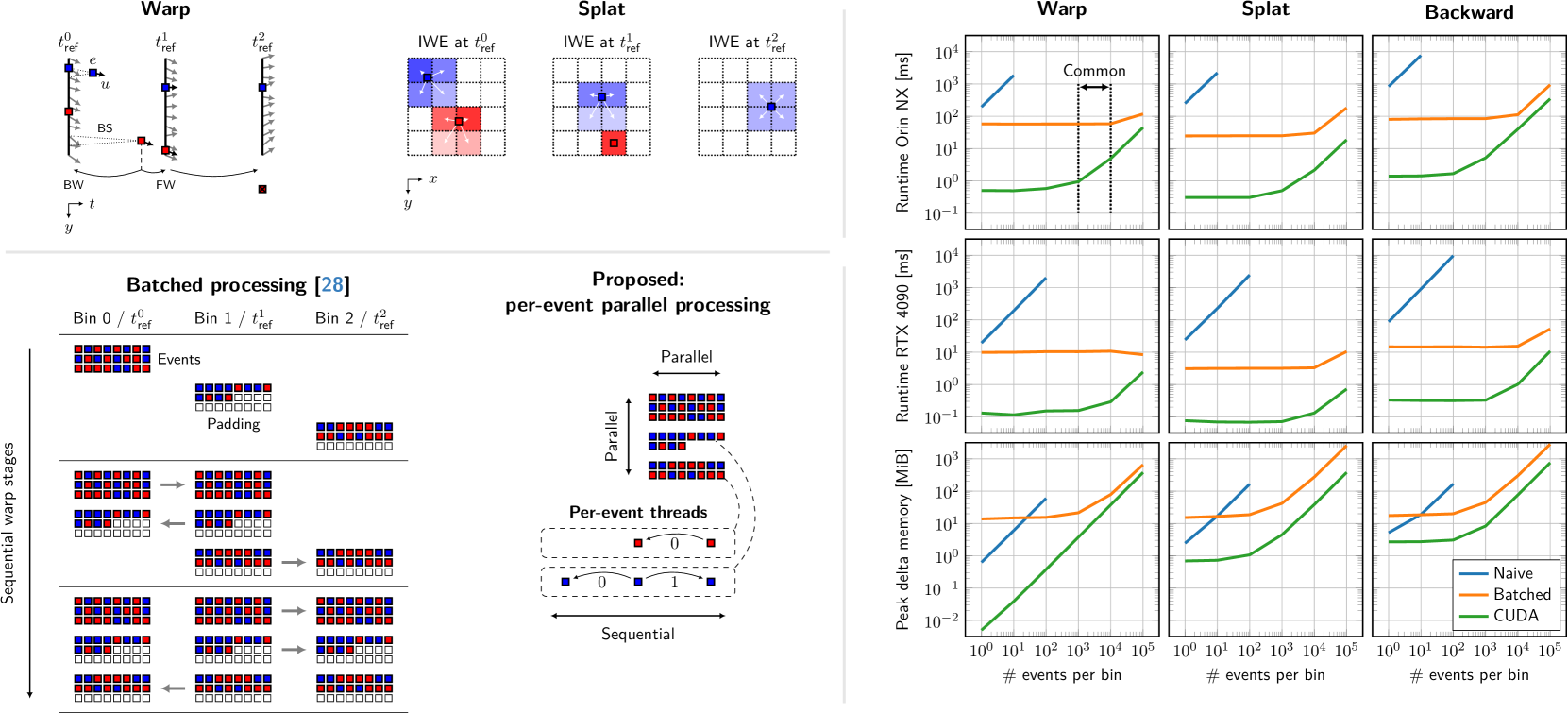


📊 实验亮点
该论文的实验结果表明,所提出的方法在小型无人机上进行在线学习后,深度估计的准确性显著提高,避障成功率也得到了提升。与其他自监督方法相比,该方法在深度估计性能上达到了最先进水平。此外,基准测试实验验证了该方法在设备端的实时性和高效性。
🎯 应用场景
该研究成果可广泛应用于小型无人机、移动机器人、AR/VR等领域。通过在设备端进行自监督学习,机器人能够更好地适应环境变化,提高自主导航、避障和目标识别等任务的性能。此外,该方法还可用于构建低成本、低功耗的视觉感知系统,推动机器人技术的普及。
📄 摘要(原文)
Event cameras provide low-latency perception for only milliwatts of power. This makes them highly suitable for resource-restricted, agile robots such as small flying drones. Self-supervised learning based on contrast maximization holds great potential for event-based robot vision, as it foregoes the need for high-frequency ground truth and allows for online learning in the robot's operational environment. However, online, on-board learning raises the major challenge of achieving sufficient computational efficiency for real-time learning, while maintaining competitive visual perception performance. In this work, we improve the time and memory efficiency of the contrast maximization pipeline, making on-device learning of low-latency monocular depth possible. We demonstrate that online learning on board a small drone yields more accurate depth estimates and more successful obstacle avoidance behavior compared to only pre-training. Benchmarking experiments show that the proposed pipeline is not only efficient, but also achieves state-of-the-art depth estimation performance among self-supervised approaches. Our work taps into the unused potential of online, on-device robot learning, promising smaller reality gaps and better performance.