Video2Reward: Generating Reward Function from Videos for Legged Robot Behavior Learning
作者: Runhao Zeng, Dingjie Zhou, Qiwei Liang, Junlin Liu, Hui Li, Changxin Huang, Jianqiang Li, Xiping Hu, Fuchun Sun
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-12-07
备注: 8 pages, 6 figures, ECAI2024
期刊: Proceedings of the 27th European Conference on Artificial Intelligence (ECAI 2024), Santiago de Compostela, Spain, October 19-24, 2024. Frontiers in Artificial Intelligence and Applications, vol. 392, IOS Press, pp. 4369-4376
DOI: 10.3233/FAIA241014
💡 一句话要点
Video2Reward:提出一种基于视频生成奖励函数的腿式机器人行为学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 腿式机器人 行为学习 奖励函数生成 强化学习 视频分析 大型语言模型 运动控制
📋 核心要点
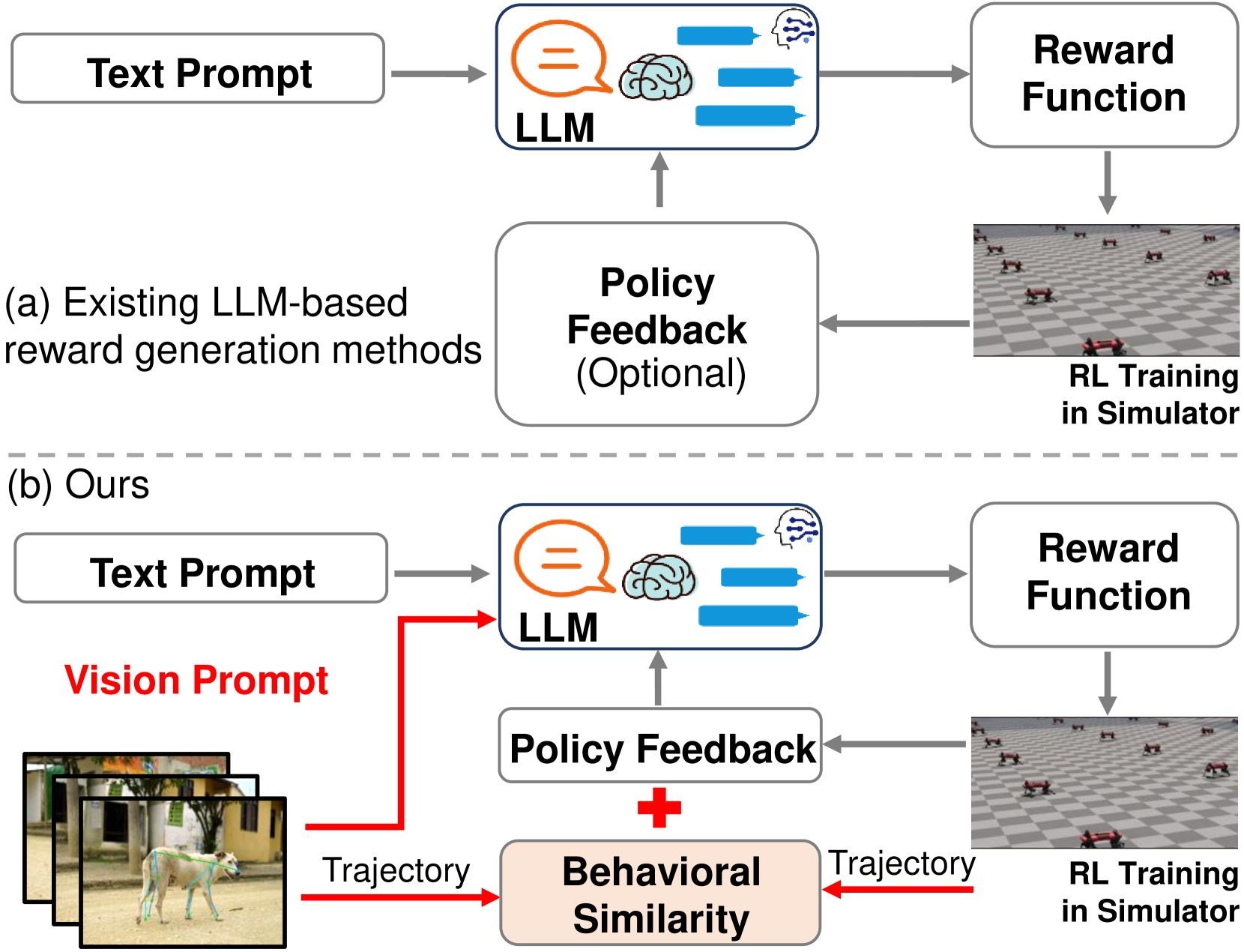
- 现有基于文本描述的LLM奖励函数生成方法,难以实现腿式机器人行为学习的可控性和精确性。
- Video2Reward方法通过视频提取关键点轨迹,输入LLM生成奖励函数,并利用视频反馈迭代优化奖励函数。
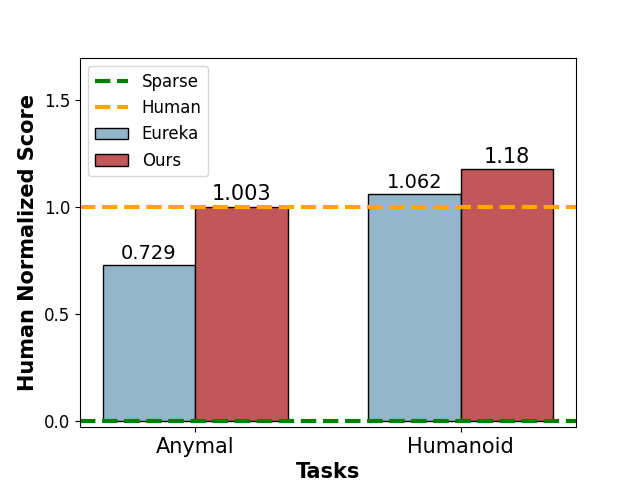
- 实验表明,该方法在双足和四足机器人运动控制任务上,性能超越现有LLM方法37.6%以上,并能快速学习多种运动行为。
📝 摘要(中文)
腿式机器人的行为学习由于其固有的不稳定性和复杂的约束而面临重大挑战。最近的研究提出了使用大型语言模型(LLM)生成强化学习中的奖励函数,从而取代了专家手动设计奖励的需求。然而,这种依赖文本描述来定义学习目标的方法,无法实现具有明确方向性的可控和精确的行为学习。本文提出了一种新的video2reward方法,该方法直接从描述要模仿和学习的行为的视频中生成奖励函数。具体来说,我们首先处理包含目标行为的视频,通过video2text转换模块将视频中个体的运动信息转换为表示为坐标的关键点轨迹。然后,将这些轨迹输入到LLM中以生成奖励函数,进而用于训练策略。为了提高奖励函数的质量,我们开发了一种视频辅助的迭代奖励细化方案,该方案以可视方式评估学习到的行为,并向LLM提供文本反馈。这种反馈引导LLM不断细化奖励函数,最终促进更高效的行为学习。在双足和四足机器人运动控制任务上的实验结果表明,我们的方法在人类归一化得分方面超过了最先进的基于LLM的奖励生成方法37.6%以上。更重要的是,通过切换视频输入,我们发现我们的方法可以快速学习行走和跑步等不同的运动行为。
🔬 方法详解
问题定义:现有基于大型语言模型(LLM)的奖励函数生成方法,依赖于文本描述来定义学习目标,这在腿式机器人行为学习中存在局限性。文本描述难以精确表达复杂的运动细节和约束,导致学习到的行为缺乏可控性和精确性。专家手动设计奖励函数成本高昂且需要专业知识。
核心思路:Video2Reward的核心思路是从视频中提取运动信息,直接生成奖励函数,避免了文本描述的模糊性。通过将视频转换为关键点轨迹,保留了运动的细节信息。利用LLM的泛化能力,将关键点轨迹映射到奖励函数。同时,引入视频辅助的迭代优化机制,通过视觉评估和文本反馈,不断改进奖励函数,提升学习效果。
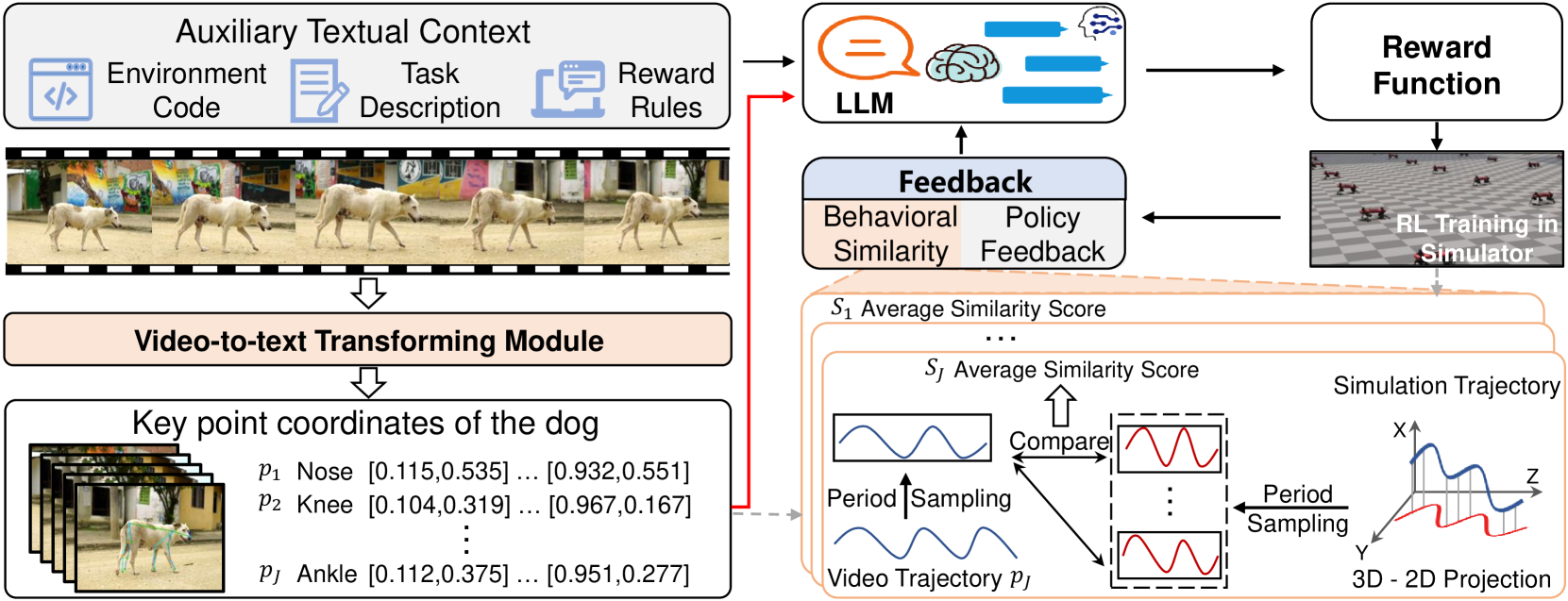
技术框架:Video2Reward方法包含以下几个主要模块:1) Video2Text转换模块:将包含目标行为的视频转换为关键点轨迹,表示为坐标序列。2) LLM奖励函数生成模块:将关键点轨迹输入到LLM中,生成初始的奖励函数。3) 视频辅助迭代奖励细化模块:通过视觉评估学习到的行为,并向LLM提供文本反馈,指导LLM不断细化奖励函数。4) 强化学习训练模块:使用生成的奖励函数训练腿式机器人的控制策略。
关键创新:Video2Reward方法最重要的创新点在于直接从视频生成奖励函数,避免了对文本描述的依赖。这种方法能够更精确地捕捉运动细节,实现更可控和精确的行为学习。此外,视频辅助的迭代优化机制,能够不断改进奖励函数,提升学习效率和性能。
关键设计:Video2Text转换模块使用现有的姿态估计模型提取视频中的关键点。LLM可以使用预训练的语言模型,并通过微调来适应奖励函数生成任务。视频辅助迭代奖励细化模块的关键在于设计有效的视觉评估指标和文本反馈策略。例如,可以评估学习到的行为与目标行为的关键点轨迹之间的距离,并根据距离的大小生成相应的文本反馈。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Video2Reward方法在双足和四足机器人运动控制任务上,性能超越了最先进的基于LLM的奖励生成方法37.6%以上(以人类归一化得分衡量)。通过切换不同的视频输入,该方法能够快速学习行走、跑步等不同的运动行为,验证了其泛化能力和高效性。消融实验验证了视频辅助迭代奖励细化模块的有效性。
🎯 应用场景
Video2Reward方法可广泛应用于腿式机器人的行为学习,例如,可以通过模仿人类或动物的运动视频,使机器人学习行走、跑步、跳跃等复杂动作。该方法还可以用于康复训练、运动分析等领域,通过分析运动视频,生成个性化的训练方案和评估报告。未来,该方法有望应用于更广泛的机器人控制任务,例如,无人驾驶、工业自动化等。
📄 摘要(原文)
Learning behavior in legged robots presents a significant challenge due to its inherent instability and complex constraints. Recent research has proposed the use of a large language model (LLM) to generate reward functions in reinforcement learning, thereby replacing the need for manually designed rewards by experts. However, this approach, which relies on textual descriptions to define learning objectives, fails to achieve controllable and precise behavior learning with clear directionality. In this paper, we introduce a new video2reward method, which directly generates reward functions from videos depicting the behaviors to be mimicked and learned. Specifically, we first process videos containing the target behaviors, converting the motion information of individuals in the videos into keypoint trajectories represented as coordinates through a video2text transforming module. These trajectories are then fed into an LLM to generate the reward function, which in turn is used to train the policy. To enhance the quality of the reward function, we develop a video-assisted iterative reward refinement scheme that visually assesses the learned behaviors and provides textual feedback to the LLM. This feedback guides the LLM to continually refine the reward function, ultimately facilitating more efficient behavior learning. Experimental results on tasks involving bipedal and quadrupedal robot motion control demonstrate that our method surpasses the performance of state-of-the-art LLM-based reward generation methods by over 37.6% in terms of human normalized score. More importantly, by switching video inputs, we find our method can rapidly learn diverse motion behaviors such as walking and running.