FlowPolicy: Enabling Fast and Robust 3D Flow-based Policy via Consistency Flow Matching for Robot Manipulation
作者: Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, Shuaicheng Liu
分类: cs.RO
发布日期: 2024-12-06 (更新: 2024-12-15)
🔗 代码/项目: GITHUB
💡 一句话要点
FlowPolicy:基于一致性流匹配的快速鲁棒3D流策略机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 流匹配 一致性模型 3D视觉 策略学习 单步推理
📋 核心要点
- 基于扩散和流匹配的机器人策略学习方法存在推理效率低下的问题,需要在效率和质量之间进行权衡。
- FlowPolicy通过一致性流匹配,规范化速度场自洽性,实现单步推理,提升策略生成速度。
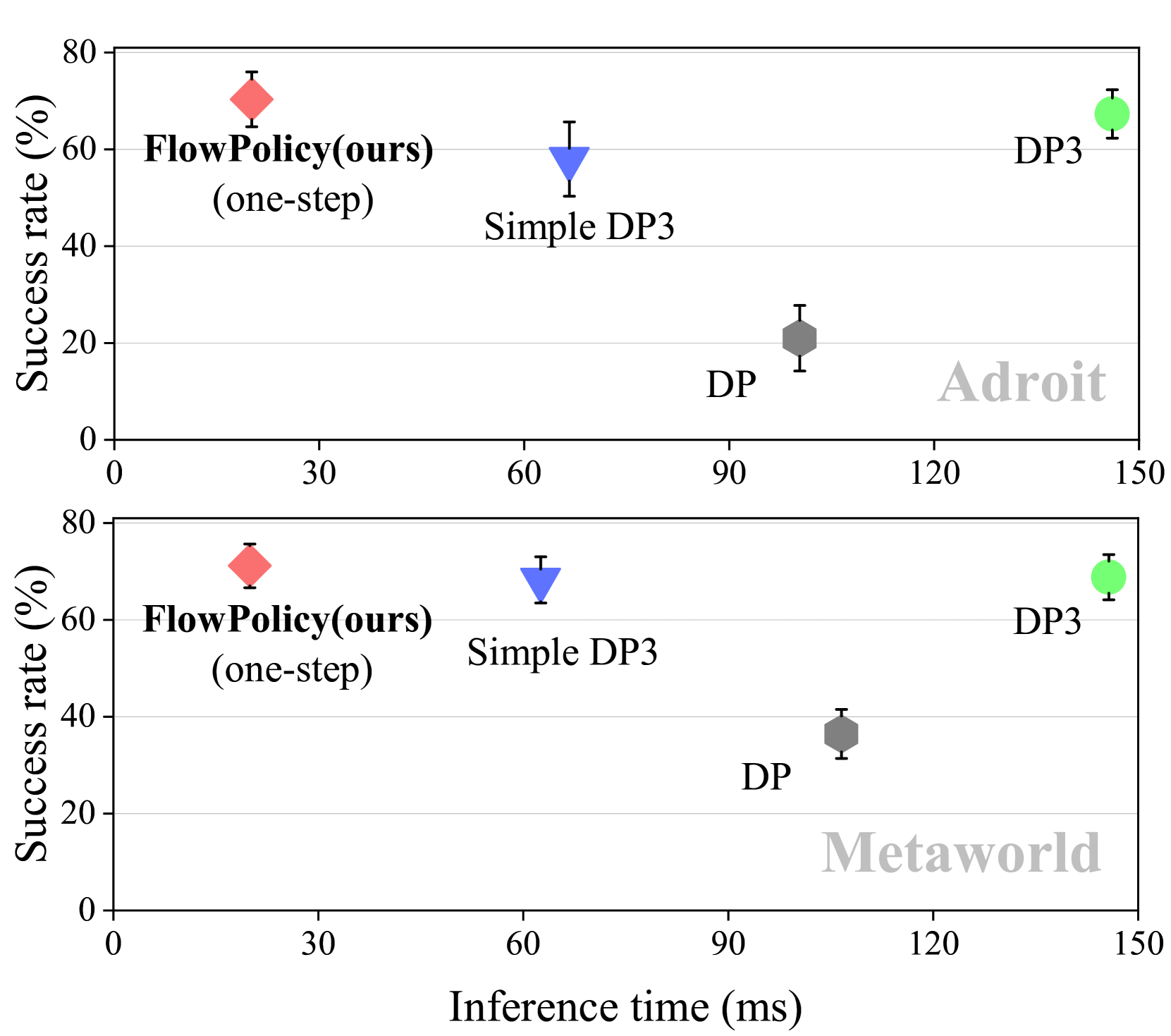
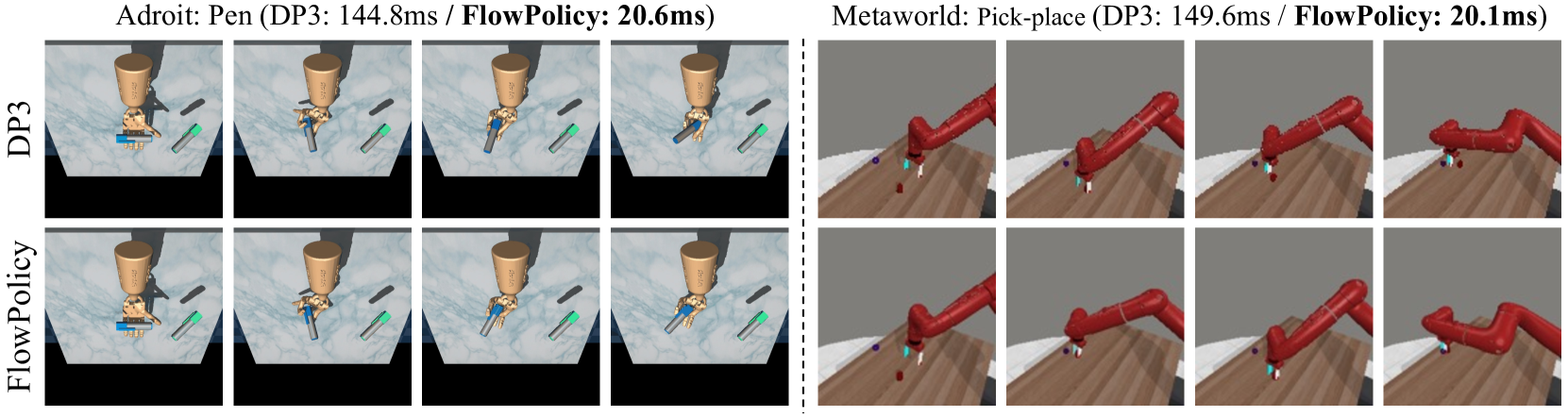
- 实验表明,FlowPolicy在Adroit和Metaworld环境中,推理速度提升7倍,并保持了竞争力的成功率。
📝 摘要(中文)
本文提出FlowPolicy,一个基于一致性流匹配和3D视觉的快速策略生成框架,旨在解决机器人操作中基于扩散和流匹配模型的策略学习效率问题。FlowPolicy通过归一化速度场自洽性来优化流动力学,从而能够通过单步推理导出任务执行策略。具体而言,FlowPolicy以观测到的3D点云为条件,通过一致性流匹配直接定义从不同时间状态到同一动作空间的直线流,并约束其速度值。通过归一化动作空间内速度场的自洽性来近似从噪声到机器人动作的轨迹,从而提高推理效率。在Adroit和Metaworld上的实验验证了FlowPolicy的有效性,与现有方法相比,推理速度提高了7倍,同时保持了具有竞争力的平均成功率。
🔬 方法详解
问题定义:现有基于扩散模型和流匹配模型的机器人操作策略学习方法,在从噪声分布到策略分布的推理过程中,需要进行多次递归迭代,导致推理效率低下,难以满足实时性要求。如何在保证策略质量的前提下,提升策略生成的效率是本文要解决的核心问题。
核心思路:FlowPolicy的核心思路是利用一致性流匹配(Consistency Flow Matching)直接学习从不同时间状态到同一动作空间的映射,并通过规范化速度场的自洽性来约束学习过程。这样,模型就可以通过单步推理,直接从初始状态预测出最终的机器人动作,从而避免了耗时的迭代过程。
技术框架:FlowPolicy的整体框架包括以下几个主要部分:1) 3D点云观测模块,用于获取环境的3D信息;2) 一致性流匹配模块,用于学习从不同时间状态到动作空间的映射;3) 速度场规范化模块,用于约束速度场的自洽性,保证学习的稳定性;4) 策略生成模块,用于根据学习到的映射,生成最终的机器人动作。整个流程以3D点云作为输入,经过上述模块的处理,最终输出机器人执行的动作。
关键创新:FlowPolicy最关键的创新在于引入了一致性流匹配的思想,并将其应用于机器人操作策略学习中。与传统的基于递归迭代的流匹配方法不同,FlowPolicy直接学习从不同时间状态到动作空间的映射,从而实现了单步推理,大大提高了策略生成的效率。此外,通过规范化速度场的自洽性,保证了学习的稳定性和策略的质量。
关键设计:FlowPolicy的关键设计包括:1) 使用3D点云作为输入,能够更好地捕捉环境的几何信息;2) 使用一致性流匹配损失函数,鼓励模型学习从不同时间状态到同一动作空间的映射;3) 使用速度场规范化损失函数,约束速度场的自洽性,保证学习的稳定性;4) 网络结构采用Encoder-Decoder架构,Encoder用于提取3D点云的特征,Decoder用于生成机器人动作。
🖼️ 关键图片

📊 实验亮点
FlowPolicy在Adroit和Metaworld两个机器人操作benchmark上进行了验证。实验结果表明,FlowPolicy在保持与现有方法相当的平均成功率的前提下,推理速度提高了7倍。这表明FlowPolicy在提高机器人操作效率方面具有显著优势,能够有效解决现有方法推理效率低下的问题。
🎯 应用场景
FlowPolicy具有广泛的应用前景,例如可应用于工业自动化、家庭服务机器人、医疗机器人等领域。该方法能够显著提高机器人操作的效率和鲁棒性,使其能够更好地适应复杂多变的环境,完成各种精细操作任务。未来,FlowPolicy有望成为机器人操作领域的重要技术手段,推动机器人技术的进一步发展。
📄 摘要(原文)
Robots can acquire complex manipulation skills by learning policies from expert demonstrations, which is often known as vision-based imitation learning. Generating policies based on diffusion and flow matching models has been shown to be effective, particularly in robotic manipulation tasks. However, recursion-based approaches are inference inefficient in working from noise distributions to policy distributions, posing a challenging trade-off between efficiency and quality. This motivates us to propose FlowPolicy, a novel framework for fast policy generation based on consistency flow matching and 3D vision. Our approach refines the flow dynamics by normalizing the self-consistency of the velocity field, enabling the model to derive task execution policies in a single inference step. Specifically, FlowPolicy conditions on the observed 3D point cloud, where consistency flow matching directly defines straight-line flows from different time states to the same action space, while simultaneously constraining their velocity values, that is, we approximate the trajectories from noise to robot actions by normalizing the self-consistency of the velocity field within the action space, thus improving the inference efficiency. We validate the effectiveness of FlowPolicy in Adroit and Metaworld, demonstrating a 7$\times$ increase in inference speed while maintaining competitive average success rates compared to state-of-the-art methods. Code is available at https://github.com/zql-kk/FlowPolicy.