NaVILA: Legged Robot Vision-Language-Action Model for Navigation
作者: An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, Xiaolong Wang
分类: cs.RO, cs.CV
发布日期: 2024-12-05 (更新: 2025-02-17)
备注: Website: https://navila-bot.github.io/
💡 一句话要点
提出NaVILA,解决腿足机器人视觉-语言-动作导航问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 腿足机器人 视觉语言导航 强化学习 机器人控制 人机交互
📋 核心要点
- 现有方法难以将人类语言指令直接转化为腿足机器人的低级别关节动作,导致导航困难。
- NaVILA通过VLA模型生成中间级语言动作指令,再由视觉运动强化学习策略执行,实现了解耦。
- 实验表明,NaVILA在现有和新基准测试中均优于现有方法,并在真实机器人实验中验证了其有效性。
📝 摘要(中文)
本文旨在解决腿足机器人的视觉-语言导航问题,该方法不仅为人类提供了一种灵活的指令方式,而且使机器人能够在更具挑战性和杂乱的场景中导航。然而,将人类语言指令转化为低级别的腿部关节动作并非易事。我们提出了NaVILA,一个双层框架,将视觉-语言-动作模型(VLA)与运动技能相结合。NaVILA并非直接从VLA预测低级动作,而是首先生成具有空间信息的中间级动作,以语言形式表示(例如,“向前移动75厘米”),作为视觉运动强化学习策略的输入以供执行。NaVILA在现有基准测试中显著优于以前的方法。在IsaacLab中开发的包含更逼真场景、低级控制和真实机器人实验的新基准测试中,也证明了相同的优势。
🔬 方法详解
问题定义:论文旨在解决腿足机器人在复杂环境中,如何根据人类的自然语言指令进行导航的问题。现有的方法通常难以直接将高级的语言指令映射到低级别的机器人动作控制,导致导航效果不佳,尤其是在充满挑战和杂乱的场景中。
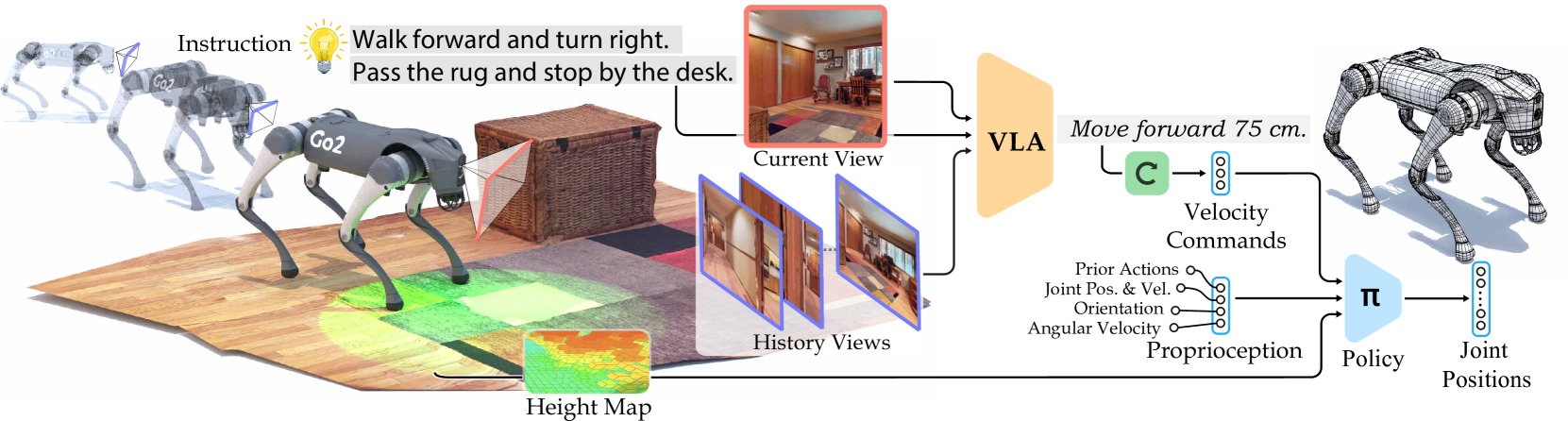
核心思路:论文的核心思路是将导航任务分解为两个层次:首先,利用视觉-语言-动作模型(VLA)将人类指令转化为中间级别的、带有空间信息的语言动作描述(例如“向前移动75厘米”);然后,利用视觉运动强化学习策略,将这些中间级别的指令转化为具体的机器人动作,从而实现导航。这种解耦的设计降低了直接从语言到动作的复杂性。
技术框架:NaVILA框架包含两个主要模块:视觉-语言-动作模型(VLA)和视觉运动强化学习策略。VLA模型接收视觉输入(来自机器人摄像头)和语言指令,输出中间级别的语言动作描述。视觉运动强化学习策略接收VLA的输出和视觉输入,生成低级别的机器人动作指令,控制机器人的运动。整个流程是端到端的,可以进行联合训练。
关键创新:NaVILA的关键创新在于引入了中间级别的语言动作描述,作为连接高级语言指令和低级机器人动作的桥梁。这种设计将复杂的导航任务分解为两个相对简单的子任务,降低了学习难度,提高了导航的鲁棒性和泛化能力。与直接预测低级动作的方法相比,NaVILA更易于训练和调试。
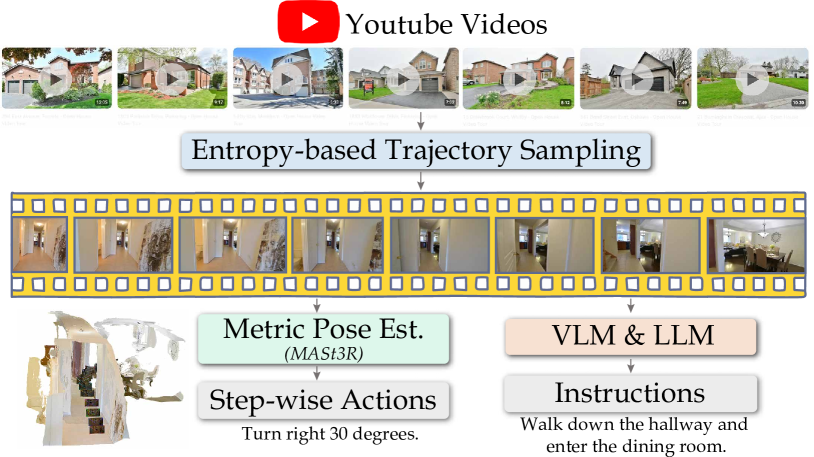
关键设计:VLA模型可以使用Transformer架构,将视觉和语言信息进行融合,并预测中间级别的语言动作描述。视觉运动强化学习策略可以使用Actor-Critic算法,通过奖励函数来引导机器人学习如何根据VLA的输出和视觉输入进行导航。奖励函数可以包括目标距离、动作平滑性等因素。论文中使用了IsaacLab进行仿真环境的搭建和训练。
🖼️ 关键图片

📊 实验亮点
NaVILA在现有基准测试中显著优于以前的方法,具体性能数据未知,但摘要强调了“substantially improves”。此外,该论文还在IsaacLab中开发了新的基准测试,包含更逼真的场景、低级控制和真实机器人实验,进一步验证了NaVILA的有效性。真实机器人实验的结果也证明了该方法在实际应用中的可行性。
🎯 应用场景
NaVILA技术可应用于物流配送、家庭服务、安防巡逻等领域,使腿足机器人能够根据人类指令在复杂环境中自主导航。该研究有助于提升机器人的智能化水平和人机交互能力,具有广阔的应用前景和重要的社会价值。未来,该技术有望进一步推广到其他类型的机器人和导航任务中。
📄 摘要(原文)
This paper proposes to solve the problem of Vision-and-Language Navigation with legged robots, which not only provides a flexible way for humans to command but also allows the robot to navigate through more challenging and cluttered scenes. However, it is non-trivial to translate human language instructions all the way to low-level leg joint actions. We propose NaVILA, a 2-level framework that unifies a Vision-Language-Action model (VLA) with locomotion skills. Instead of directly predicting low-level actions from VLA, NaVILA first generates mid-level actions with spatial information in the form of language, (e.g., "moving forward 75cm"), which serves as an input for a visual locomotion RL policy for execution. NaVILA substantially improves previous approaches on existing benchmarks. The same advantages are demonstrated in our newly developed benchmarks with IsaacLab, featuring more realistic scenes, low-level controls, and real-world robot experiments. We show more results at https://navila-bot.github.io/