Reinforcement Learning from Wild Animal Videos
作者: Elliot Chane-Sane, Constant Roux, Olivier Stasse, Nicolas Mansard
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-12-05
备注: Project website: https://elliotchanesane31.github.io/RLWAV/
💡 一句话要点
提出基于野生动物视频的强化学习方法,用于机器人运动技能学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人运动控制 模仿学习 视频分类 四足机器人
📋 核心要点
- 现有机器人运动技能学习方法依赖人工设计的参考轨迹或奖励函数,泛化性差,难以适应复杂环境。
- RLWAV方法利用大量野生动物视频作为运动先验知识,通过视频分类器和强化学习,使机器人模仿动物的运动方式。
- 实验表明,该方法成功地将学习到的策略迁移到真实的四足机器人Solo上,实现了行走、跳跃等多种技能。
📝 摘要(中文)
本文提出了一种名为“基于野生动物视频的强化学习”(RLWAV)的方法,旨在通过观察互联网上大量的野生动物视频(如自然纪录片)来学习腿式机器人的运动技能。这些视频提供了丰富多样的运动示例,可以为机器人如何运动提供信息。该方法首先在一个大型动物视频数据集上训练一个视频分类器,以识别动物在其自然栖息地中的RGB视频片段中的动作。然后,训练一个多技能策略来控制物理模拟器中的机器人,使用第三人称视角摄像头捕捉机器人运动视频的分类得分作为强化学习的奖励。最后,将学习到的策略直接迁移到真实的四足机器人Solo上。值得注意的是,尽管野生动物和机器人之间在领域和形态上存在巨大差距,但该方法能够使策略学习到多种技能,如行走、跳跃和静止,而无需依赖参考轨迹或特定技能的奖励。
🔬 方法详解
问题定义:现有机器人运动控制方法通常依赖于人工设计的参考轨迹或奖励函数,这需要大量的领域知识和手动调整,难以泛化到不同的环境和任务中。此外,从零开始训练机器人运动策略通常需要大量的计算资源和时间。因此,如何利用现有的运动数据,例如野生动物的视频,来高效地学习机器人的运动技能是一个重要的挑战。
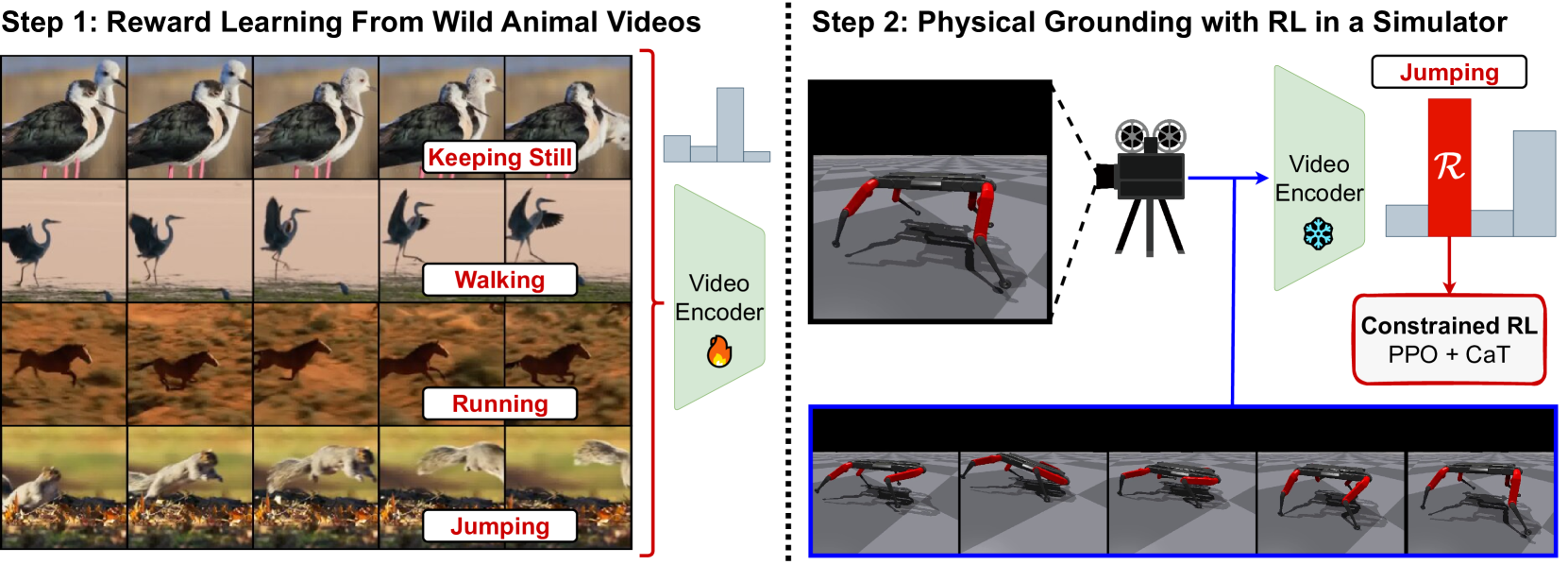
核心思路:本文的核心思路是利用野生动物视频中蕴含的丰富运动信息,通过模仿学习的方式来训练机器人的运动策略。具体来说,首先训练一个视频分类器,用于识别视频中动物的动作类型。然后,将该分类器的输出作为强化学习的奖励信号,引导机器人在模拟环境中学习相应的运动技能。这种方法避免了人工设计奖励函数的复杂性,并且可以利用大量的现有视频数据来加速学习过程。
技术框架:RLWAV方法主要包含以下几个阶段:1) 视频分类器训练:使用大规模的动物视频数据集训练一个视频分类器,用于识别视频中动物的动作类型。2) 强化学习训练:在物理模拟器中,使用强化学习算法训练机器人的运动策略。奖励函数基于视频分类器的输出,鼓励机器人模仿视频中动物的动作。3) 策略迁移:将学习到的策略迁移到真实的机器人上,并在真实环境中进行测试。
关键创新:该方法最重要的创新点在于利用视频分类器的输出来作为强化学习的奖励信号。这种方法将视觉信息和运动控制相结合,使得机器人可以直接从视频中学习运动技能,而无需人工设计复杂的奖励函数。此外,该方法还能够利用大量的现有视频数据来加速学习过程。
关键设计:在视频分类器训练阶段,使用了大规模的动物视频数据集,并采用了先进的视频分类模型。在强化学习训练阶段,使用了第三人称视角的摄像头来捕捉机器人的运动视频,并将该视频输入到视频分类器中,得到奖励信号。此外,还采用了合适的强化学习算法和参数设置,以保证学习的稳定性和效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RLWAV方法能够成功地将学习到的策略迁移到真实的四足机器人Solo上,实现了行走、跳跃和静止等多种技能。尽管野生动物和机器人之间在领域和形态上存在巨大差距,但该方法仍然能够有效地学习到机器人的运动策略。与传统的强化学习方法相比,该方法无需人工设计奖励函数,并且可以利用大量的现有视频数据来加速学习过程。
🎯 应用场景
该研究成果可应用于各种腿式机器人的运动控制,例如搜救机器人、巡检机器人和家用服务机器人。通过模仿动物的运动方式,可以使机器人在复杂环境中更加灵活和高效地移动。此外,该方法还可以扩展到其他类型的机器人,例如无人机和水下机器人,从而实现更加智能和自主的运动控制。
📄 摘要(原文)
We propose to learn legged robot locomotion skills by watching thousands of wild animal videos from the internet, such as those featured in nature documentaries. Indeed, such videos offer a rich and diverse collection of plausible motion examples, which could inform how robots should move. To achieve this, we introduce Reinforcement Learning from Wild Animal Videos (RLWAV), a method to ground these motions into physical robots. We first train a video classifier on a large-scale animal video dataset to recognize actions from RGB clips of animals in their natural habitats. We then train a multi-skill policy to control a robot in a physics simulator, using the classification score of a third-person camera capturing videos of the robot's movements as a reward for reinforcement learning. Finally, we directly transfer the learned policy to a real quadruped Solo. Remarkably, despite the extreme gap in both domain and embodiment between animals in the wild and robots, our approach enables the policy to learn diverse skills such as walking, jumping, and keeping still, without relying on reference trajectories nor skill-specific rewards.