A Dynamic Safety Shield for Safe and Efficient Reinforcement Learning of Navigation Tasks
作者: Murad Dawood, Ahmed Shokry, Maren Bennewitz
分类: cs.RO, math.OC
发布日期: 2024-12-05 (更新: 2025-04-18)
备注: Accepted in L4DC2025
💡 一句话要点
提出动态安全盾,用于导航任务中安全高效的强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 安全强化学习 机器人导航 动态安全盾 安全探索
📋 核心要点
- 传统强化学习在机器人导航中面临安全挑战,早期训练阶段碰撞频繁,影响学习效率。
- 提出动态安全盾,融合优化控制器的鲁棒性和强化学习的长期预测能力,自适应调整控制器参数。
- 实验表明,该方法在模拟和真实环境中均优于现有方法,显著提高了导航任务的安全性与效率。
📝 摘要(中文)
强化学习(RL)已成功应用于各种机器人应用,其性能优于传统方法。然而,RL的安全性以及向现实世界的迁移仍然是一个开放的挑战。安全强化学习是解决这一挑战并确保智能体在训练和执行期间安全性的一个重要领域。安全RL可以通过约束RL和安全探索方法来实现。前者在训练过程中学习安全约束,以在训练结束时实现安全行为,但代价是在训练早期阶段发生大量碰撞。后者通过强制执行安全约束作为硬约束来提供强大的安全性,这可以防止碰撞,但会阻碍RL智能体的探索,从而导致较低的奖励和较差的性能。为了克服这些缺点,我们提出了一种新的安全盾,它将基于优化的控制器的鲁棒性与RL智能体的长期预测能力相结合,允许RL智能体自适应地调整控制器的参数。我们的方法能够改善RL智能体在导航任务中的探索,同时最大限度地减少碰撞次数。在模拟实验中表明,我们的方法在不同的具有挑战性的环境中,在已到达目标与碰撞的比率方面优于最先进的基线。目标与碰撞的比率指标强调了最小化碰撞次数的重要性,同时学习完成任务。与经典安全盾相比,我们的方法实现了更高的已到达目标数量,并且与约束RL方法相比,碰撞次数更少。最后,我们在真实世界的实验中展示了所提出方法的性能。
🔬 方法详解
问题定义:论文旨在解决强化学习在机器人导航任务中安全性和探索效率之间的矛盾。现有方法,如约束强化学习,虽然最终能保证安全,但在训练初期碰撞频繁。而安全探索方法则过于保守,限制了智能体的探索能力,导致性能下降。
核心思路:论文的核心思路是结合优化控制器的鲁棒性和强化学习的自适应能力,设计一个动态安全盾。该安全盾能够根据强化学习智能体的预测结果,动态调整控制器的参数,从而在保证安全的前提下,提高智能体的探索效率。
技术框架:整体框架包含两个主要模块:强化学习智能体和动态安全盾。强化学习智能体负责学习导航策略,并预测未来状态。动态安全盾则根据智能体的预测结果,调整控制器的参数,确保智能体的行为在安全范围内。具体流程是,强化学习智能体输出动作,安全盾评估该动作的安全性,若不安全则调整动作,确保安全后执行。
关键创新:关键创新在于动态调整控制器参数的安全盾设计。传统安全盾通常采用固定的安全约束,限制了智能体的探索。而该方法能够根据强化学习智能体的学习情况,自适应地调整安全约束,从而在保证安全的同时,提高探索效率。
关键设计:动态安全盾的关键设计包括:1) 基于优化的控制器,用于保证基本的安全性;2) 强化学习智能体,用于学习导航策略和预测未来状态;3) 参数调整机制,根据强化学习智能体的预测结果,动态调整控制器的参数。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

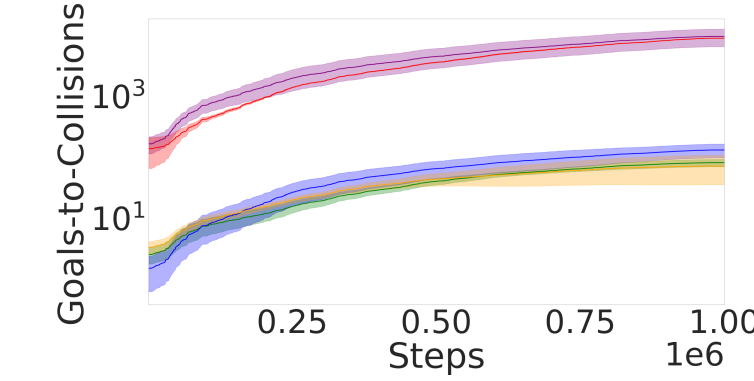
📊 实验亮点
实验结果表明,该方法在模拟环境中,在已到达目标与碰撞的比率方面优于最先进的基线方法。与经典安全盾相比,该方法实现了更高的已到达目标数量。与约束RL方法相比,碰撞次数更少。此外,该方法还在真实世界的实验中验证了其有效性。
🎯 应用场景
该研究成果可应用于各种需要安全保障的机器人导航任务,例如自动驾驶、无人机配送、仓储机器人等。通过动态安全盾,可以提高机器人在复杂环境中的适应性和安全性,降低事故风险,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Reinforcement learning (RL) has been successfully applied to a variety of robotics applications, where it outperforms classical methods. However, the safety aspect of RL and the transfer to the real world remain an open challenge. A prominent field for tackling this challenge and ensuring the safety of the agents during training and execution is safe reinforcement learning. Safe RL can be achieved through constrained RL and safe exploration approaches. The former learns the safety constraints over the course of training to achieve a safe behavior by the end of training, at the cost of high number of collisions at earlier stages of the training. The latter offers robust safety by enforcing the safety constraints as hard constraints, which prevents collisions but hinders the exploration of the RL agent, resulting in lower rewards and poor performance. To overcome those drawbacks, we propose a novel safety shield, that combines the robustness of the optimization-based controllers with the long prediction capabilities of the RL agents, allowing the RL agent to adaptively tune the parameters of the controller. Our approach is able to improve the exploration of the RL agents for navigation tasks, while minimizing the number of collisions. Experiments in simulation show that our approach outperforms state-of-the-art baselines in the reached goals-to-collisions ratio in different challenging environments. The goals-to-collisions ratio metrics emphasizes the importance of minimizing the number of collisions, while learning to accomplish the task. Our approach achieves a higher number of reached goals compared to the classic safety shields and fewer collisions compared to constrained RL approaches. Finally, we demonstrate the performance of the proposed method in a real-world experiment.