Diffusion-VLA: Generalizable and Interpretable Robot Foundation Model via Self-Generated Reasoning
作者: Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, Feifei Feng
分类: cs.RO, cs.CV
发布日期: 2024-12-04 (更新: 2025-06-04)
备注: Accepted by ICML 2025. The project page is available at: http://diffusion-vla.github.io
💡 一句话要点
提出DiffusionVLA,通过自生成推理实现通用且可解释的机器人基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人 视觉运动策略 扩散模型 自回归模型 可解释性 泛化能力 推理注入 深度学习
📋 核心要点
- 现有视觉运动策略模型在泛化性和可解释性方面存在不足,难以适应新环境和理解模型决策。
- DiffusionVLA结合自回归模型和扩散模型,通过token预测进行推理,并注入推理短语增强策略学习。
- 实验表明,DiffusionVLA在工厂分拣和bin-picking任务中表现出色,具有良好的泛化性和可解释性,且数据效率高。
📝 摘要(中文)
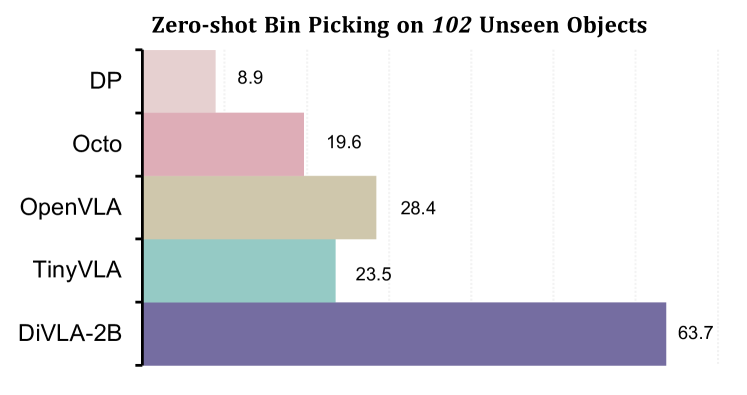
本文提出了一种名为DiffusionVLA的新框架,它将自回归模型与扩散模型无缝结合,用于学习视觉运动策略。该方法的核心是下一个token预测目标,使模型能够在当前观测的上下文中有效地推理用户的查询。随后,附加一个扩散模型来生成鲁棒的动作输出。为了通过自我推理来增强策略学习,我们引入了一种新的推理注入模块,该模块将推理短语直接集成到策略学习过程中。整个框架简单而灵活,易于部署和升级。我们使用多个真实机器人进行了广泛的实验,以验证DiffusionVLA的有效性。我们的测试包括一项具有挑战性的工厂分拣任务,其中DiffusionVLA成功地对物体进行分类,包括那些在训练期间未见过的物体。我们观察到推理模块使模型具有可解释性,允许观察者理解模型的思维过程并识别策略失败的潜在原因。此外,我们在零样本的bin-picking任务上测试了DiffusionVLA,在102个以前未见过的物体上实现了63.7%的准确率。我们的方法对视觉变化(如干扰物和新背景)具有鲁棒性,并且易于适应新的形态。此外,DiffusionVLA可以遵循新的指令并保留对话能力。值得注意的是,DiffusionVLA具有数据效率并且推理速度很快;我们最小的DiffusionVLA-2B在单个A6000 GPU上以82Hz的速度运行,并且可以从头开始训练,只需不到50个复杂任务的演示。最后,我们将模型从2B扩展到72B参数,展示了随着模型尺寸的增加而提高的泛化能力。
🔬 方法详解
问题定义:论文旨在解决机器人视觉运动策略学习中的泛化性和可解释性问题。现有方法通常难以适应新的环境和物体,并且模型的决策过程难以理解,导致难以调试和改进。这些痛点限制了机器人在复杂和动态环境中的应用。
核心思路:DiffusionVLA的核心思路是将自回归模型用于推理,扩散模型用于动作生成,并引入推理注入模块来增强策略学习。自回归模型通过预测下一个token来理解用户的查询和当前观测,扩散模型则生成鲁棒的动作输出。推理注入模块将推理短语直接集成到策略学习过程中,提高模型的可解释性。
技术框架:DiffusionVLA的整体架构包含三个主要模块:1) 自回归推理模块:使用Transformer架构,以视觉输入和用户指令为条件,预测下一个token,实现对任务的理解和推理。2) 扩散模型:以自回归推理模块的输出为条件,生成连续的动作输出。3) 推理注入模块:将推理短语(例如“找到红色物体”)作为额外的输入,引导模型进行更明确的推理。
关键创新:DiffusionVLA的关键创新在于将自回归模型和扩散模型结合,并引入推理注入模块。这种结合使得模型既能进行有效的推理,又能生成鲁棒的动作输出。推理注入模块通过显式地引入推理短语,提高了模型的可解释性,使得观察者可以理解模型的思维过程。
关键设计:在自回归推理模块中,使用了标准的Transformer架构,并采用了交叉熵损失函数进行训练。扩散模型使用了U-Net架构,并采用了噪声预测损失函数进行训练。推理注入模块通过将推理短语嵌入到Transformer的输入中来实现。模型参数规模从2B到72B不等,以探索模型规模对性能的影响。
🖼️ 关键图片


📊 实验亮点
DiffusionVLA在工厂分拣任务中成功分类了训练期间未见过的物体,在零样本bin-picking任务中达到了63.7%的准确率(102个未见物体)。该模型对视觉干扰具有鲁棒性,并能适应新的机器人形态。最小的DiffusionVLA-2B模型在单个A6000 GPU上以82Hz运行,且仅需不到50个演示即可完成复杂任务的训练。模型规模扩展到72B参数后,泛化能力进一步提升。
🎯 应用场景
DiffusionVLA具有广泛的应用前景,包括工业自动化、家庭服务机器人、医疗机器人等领域。它可以用于解决复杂的机器人操作任务,例如物体分拣、装配、抓取等。其可解释性使得用户可以更容易地理解和信任机器人的行为,从而促进人机协作。
📄 摘要(原文)
In this paper, we present DiffusionVLA, a novel framework that seamlessly combines the autoregression model with the diffusion model for learning visuomotor policy. Central to our approach is a next-token prediction objective, enabling the model to reason effectively over the user's query in the context of current observations. Subsequently, a diffusion model is attached to generate robust action outputs. To enhance policy learning through self-reasoning, we introduce a novel reasoning injection module that integrates reasoning phrases directly into the policy learning process. The whole framework is simple and flexible, making it easy to deploy and upgrade. We conduct extensive experiments using multiple real robots to validate the effectiveness of DiffusionVLA. Our tests include a challenging factory sorting task, where DiffusionVLA successfully categorizes objects, including those not seen during training. We observe that the reasoning module makes the model interpretable. It allows observers to understand the model thought process and identify potential causes of policy failures. Additionally, we test DiffusionVLA on a zero-shot bin-picking task, achieving 63.7\% accuracy on 102 previously unseen objects. Our method demonstrates robustness to visual changes, such as distractors and new backgrounds, and easily adapts to new embodiments. Furthermore, DiffusionVLA can follow novel instructions and retain conversational ability. Notably, DiffusionVLA is data-efficient and fast at inference; our smallest DiffusionVLA-2B runs 82Hz on a single A6000 GPU and can train from scratch on less than 50 demonstrations for a complex task. Finally, we scale the model from 2B to 72B parameters, showcasing improved generalization capabilities with increased model size.