MCVO: A Generic Visual Odometry for Arbitrarily Arranged Multi-Cameras
作者: Huai Yu, Junhao Wang, Yao He, Wen Yang, Gui-Song Xia
分类: cs.RO
发布日期: 2024-12-04 (更新: 2025-03-25)
备注: 8 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
MCVO:一种通用的任意多相机视觉里程计,提升了位姿估计的精度和泛化能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 多相机视觉里程计 视觉SLAM 位姿估计 特征跟踪 后端优化
📋 核心要点
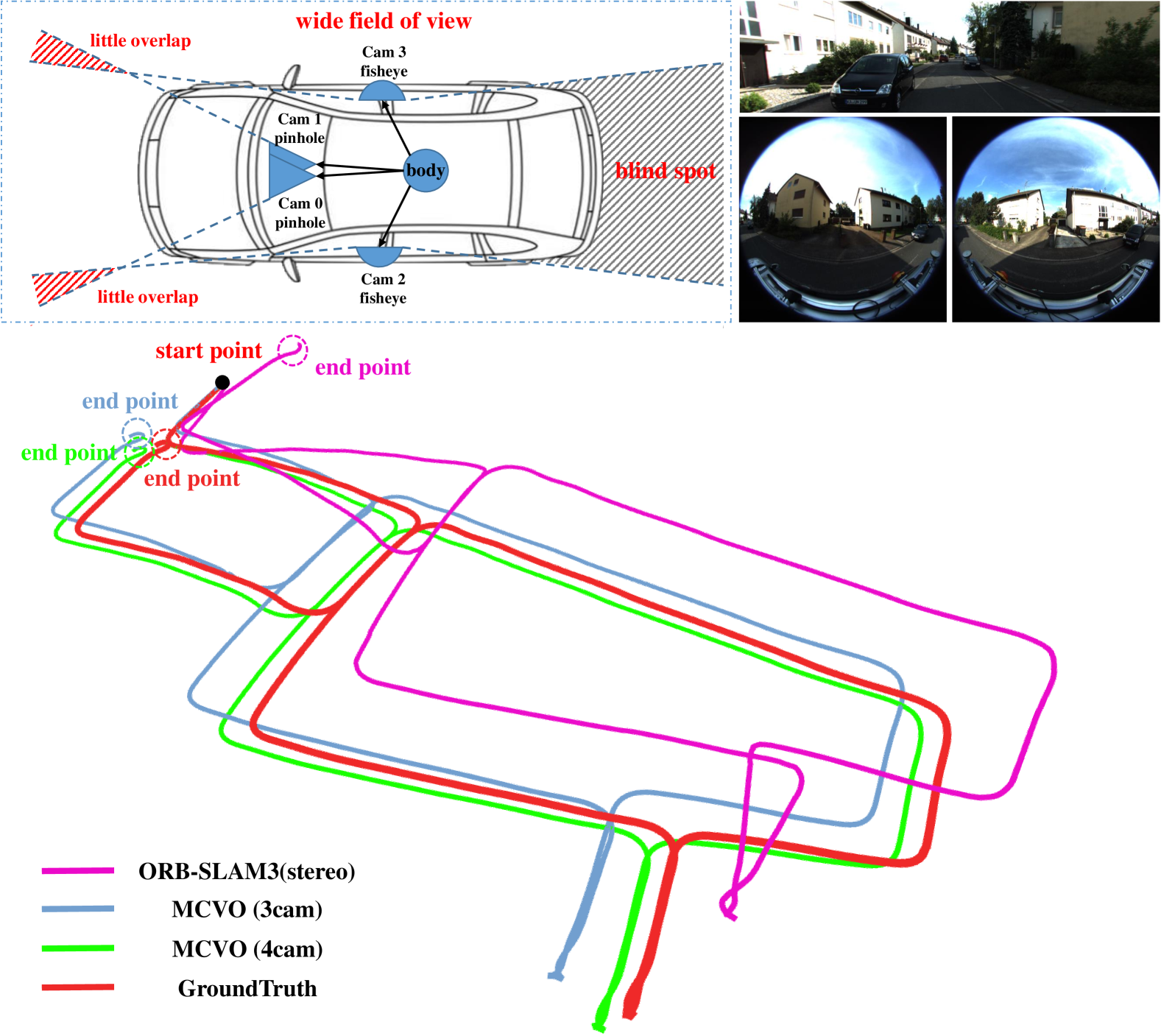
- 现有单目和双目视觉SLAM系统视野狭窄,在无纹理环境中精度退化且鲁棒性有限,多相机SLAM系统因其更宽的视野和冗余性而备受关注。
- MCVO通过学习的特征跟踪将计算压力转移到GPU,利用相机间刚性约束初始化系统,并在后端融合多相机特征进行鲁棒的位姿估计和尺度优化。
- 在KITTI-360和MultiCamData数据集上的实验表明,MCVO在任意排列的相机配置下具有鲁棒性,并优于其他立体和多相机SLAM系统。
📝 摘要(中文)
本文提出了一种鲁棒的视觉里程计系统MCVO,用于刚性捆绑的任意排列多相机系统,该系统能够在相机排列具有高度灵活性的情况下实现度量尺度的状态估计。首先,设计了一个基于学习的特征跟踪框架,将多个视频流的CPU处理压力转移到GPU。然后,在运动相机之间的刚性约束下,使用度量尺度的位姿初始化里程计系统。最后,融合多相机的特征在后端实现鲁棒的位姿估计和在线尺度优化。此外,多相机特征有助于改进姿态图优化的闭环检测。在KITTI-360和MultiCamData数据集上的实验验证了其在任意排列相机上的鲁棒性。与其他立体和多相机视觉SLAM系统相比,该方法获得了更高的位姿精度和更好的泛化能力。
🔬 方法详解
问题定义:现有视觉SLAM系统在多相机配置下,由于相机排列的任意性,位姿尺度估计和系统更新面临挑战。传统方法难以有效利用多相机提供的冗余信息,且计算复杂度高,难以实时处理。
核心思路:MCVO的核心思路是利用多相机之间的刚性约束进行度量尺度的初始化,并设计一个高效的特征跟踪和融合框架,以充分利用多相机提供的冗余信息,从而实现鲁棒且精确的位姿估计。通过学习的方法加速特征提取和匹配,降低计算负担。
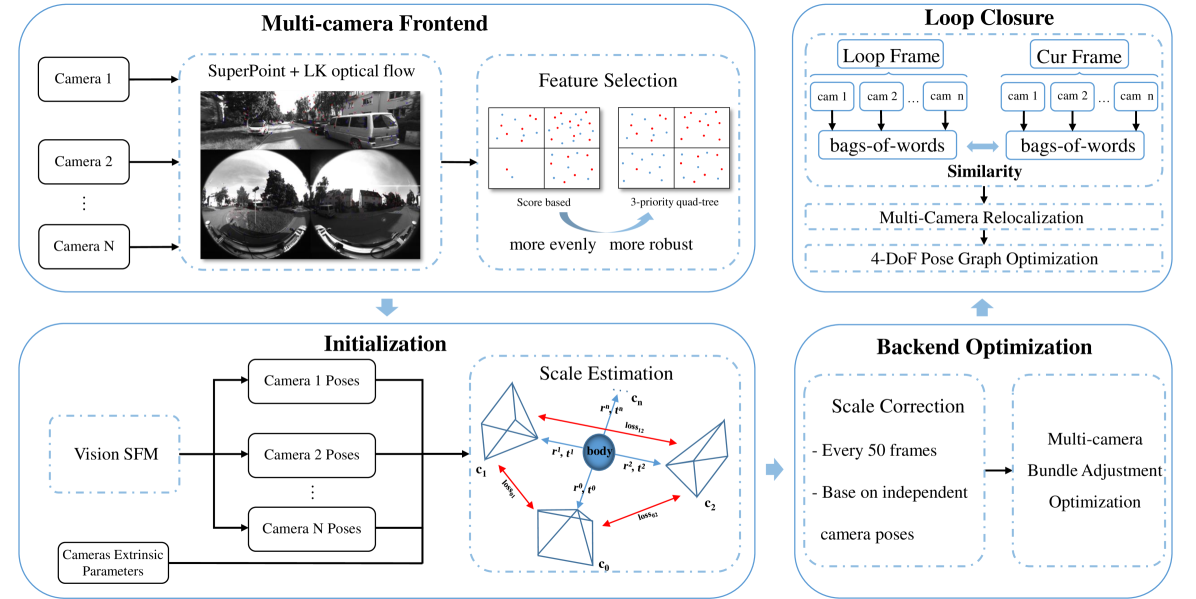
技术框架:MCVO系统主要包含三个阶段:1) 基于学习的特征跟踪:利用神经网络提取和匹配多相机图像中的特征点,并将计算压力转移到GPU。2) 度量尺度初始化:利用相机之间的刚性约束,估计初始的度量尺度位姿。3) 后端优化:融合多相机特征,进行位姿图优化和在线尺度优化,并利用多相机特征改进闭环检测。
关键创新:MCVO的关键创新在于:1) 提出了一种通用的多相机视觉里程计框架,能够处理任意排列的多相机系统。2) 采用学习的特征跟踪方法,提高了特征提取和匹配的效率。3) 设计了一种基于刚性约束的度量尺度初始化方法,避免了尺度漂移问题。4) 融合多相机特征进行后端优化,提高了位姿估计的鲁棒性和精度。
关键设计:学习的特征跟踪框架采用了一种轻量级的神经网络结构,以保证实时性。度量尺度初始化方法利用了相机之间的相对位姿关系,通过求解一个优化问题来估计初始位姿。后端优化采用了滑动窗口优化策略,并使用了BA(Bundle Adjustment)算法进行位姿精调。损失函数包括重投影误差和IMU预积分误差(如果可用)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MCVO在KITTI-360和MultiCamData数据集上取得了优异的性能。相较于其他立体和多相机视觉SLAM系统,MCVO在位姿精度上获得了显著提升,并展现出更好的泛化能力。具体数据指标(如RMSE)未在摘要中给出,但强调了其优于现有方法。
🎯 应用场景
MCVO可应用于机器人、自动驾驶、无人机等领域,尤其适用于需要大视场角和高鲁棒性的场景,例如复杂环境下的导航、三维重建和目标跟踪。该系统能够简化多相机系统的设置,提高环境适应性,并为视觉机器人提供更可靠的定位和建图能力。
📄 摘要(原文)
Making multi-camera visual SLAM systems easier to set up and more robust to the environment is attractive for vision robots. Existing monocular and binocular vision SLAM systems have narrow sensing Field-of-View (FoV), resulting in degenerated accuracy and limited robustness in textureless environments. Thus multi-camera SLAM systems are gaining attention because they can provide redundancy with much wider FoV. However, the usual arbitrary placement and orientation of multiple cameras make the pose scale estimation and system updating challenging. To address these problems, we propose a robust visual odometry system for rigidly-bundled arbitrarily-arranged multi-cameras, namely MCVO, which can achieve metric-scale state estimation with high flexibility in the cameras' arrangement. Specifically, we first design a learning-based feature tracking framework to shift the pressure of CPU processing of multiple video streams to GPU. Then we initialize the odometry system with the metric-scale poses under the rigid constraints between moving cameras. Finally, we fuse the features of the multi-cameras in the back-end to achieve robust pose estimation and online scale optimization. Additionally, multi-camera features help improve the loop detection for pose graph optimization. Experiments on KITTI-360 and MultiCamData datasets validate its robustness over arbitrarily arranged cameras. Compared with other stereo and multi-camera visual SLAM systems, our method obtains higher pose accuracy with better generalization ability. Our codes and online demos are available at https://github.com/JunhaoWang615/MCVO