Incorporating System-level Safety Requirements in Perception Models via Reinforcement Learning
作者: Weisi Fan, Jesse Lane, Qisai Liu, Soumik Sarkar, Tichakorn Wongpiromsarn
分类: cs.RO, cs.LG
发布日期: 2024-12-04
💡 一句话要点
提出基于强化学习的感知模型训练方法,提升自动驾驶系统级安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 感知模型 自动驾驶 系统安全 规则手册
📋 核心要点
- 现有感知模型训练通常只关注准确率等指标,忽略了感知错误对系统安全性的潜在影响。
- 该论文提出利用强化学习框架,将系统级安全需求转化为奖励函数,从而指导感知模型的训练。
- 实验结果表明,该方法训练的模型在系统级安全性方面优于传统的基线感知模型。
📝 摘要(中文)
自动驾驶系统中的感知组件通常独立于下游决策和控制组件进行开发和优化,依赖于诸如准确率、精确率和召回率等性能指标。传统的损失函数,如交叉熵损失和负对数似然,侧重于减少错误分类误差,但未能考虑这些误差对系统级安全性的影响,忽略了由这些误差引起的系统级故障的不同严重程度。为了解决这一局限性,我们提出了一种新的训练范式,该范式通过理解系统级安全目标来增强感知组件。我们方法的核心是将系统级安全需求(使用规则手册形式化规范)转化为安全分数。然后,将这些分数纳入强化学习框架的奖励函数中,用于使用系统级安全目标微调感知模型。仿真结果表明,使用这种方法训练的模型在系统级安全性方面优于基线感知模型。
🔬 方法详解
问题定义:现有自动驾驶感知模型训练通常独立于下游决策和控制模块,优化目标集中在提高感知准确率,如分类精度等。然而,不同的感知错误对系统安全的影响程度不同,例如将行人误识别为车辆的风险远高于将一种类型的车辆误识别为另一种。因此,如何将系统级的安全需求融入到感知模型的训练中,是一个亟待解决的问题。
核心思路:该论文的核心思路是将系统级的安全需求转化为强化学习中的奖励函数,通过强化学习的方式微调感知模型。具体来说,首先将系统级的安全规则形式化为安全分数,然后将该分数作为强化学习的奖励信号,引导感知模型学习降低系统风险的行为。这样,感知模型的优化目标不再仅仅是提高准确率,而是直接优化系统级的安全性。
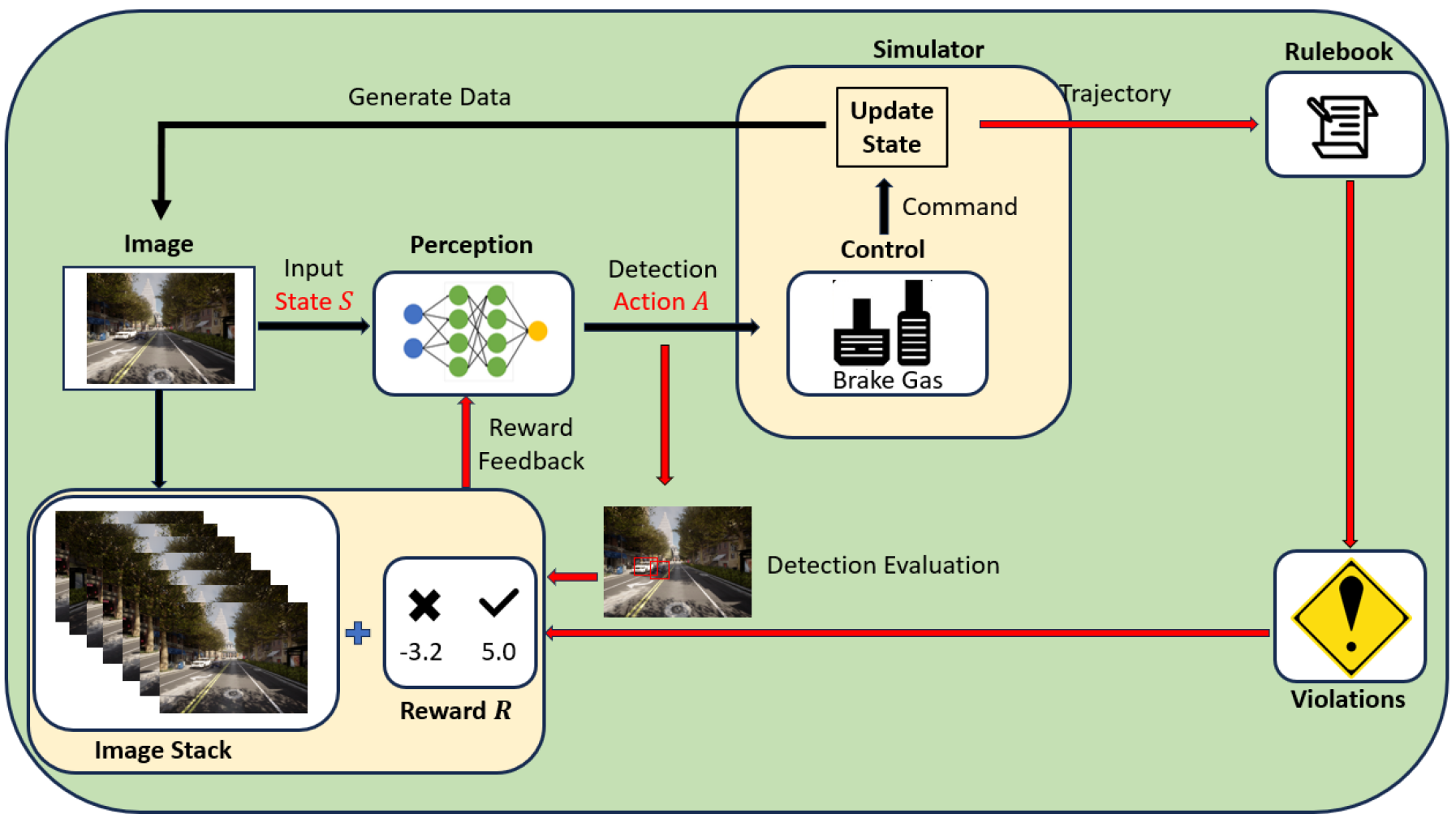
技术框架:整体框架包括以下几个主要模块:1) 规则手册 (Rulebook):形式化地描述系统级的安全需求,例如避免碰撞、保持车道等。2) 安全分数计算模块:根据规则手册和当前系统状态,计算出一个安全分数,用于评估当前状态的安全性。3) 感知模型:需要训练的感知模型,例如目标检测器或语义分割模型。4) 强化学习代理:使用安全分数作为奖励信号,通过与环境交互,学习如何调整感知模型的参数,以最大化系统安全性。整个流程是:感知模型输出感知结果,结合环境状态,计算安全分数,强化学习代理根据安全分数调整感知模型参数,重复迭代。
关键创新:该论文最重要的创新在于将系统级的安全需求与感知模型的训练过程联系起来。传统的感知模型训练通常只关注感知本身的准确率,而忽略了感知错误对系统安全的影响。该论文通过强化学习的方式,将系统安全作为感知模型训练的直接目标,从而能够训练出更加安全的感知模型。
关键设计:关键设计包括:1) 安全分数的定义:如何将复杂的系统安全规则转化为一个可量化的安全分数,需要仔细设计。2) 强化学习算法的选择:需要选择合适的强化学习算法,例如Q-learning或Policy Gradient等,以及合适的奖励函数和状态空间。3) 感知模型的微调策略:如何有效地利用强化学习信号微调感知模型的参数,避免过度拟合或训练不稳定。
🖼️ 关键图片

📊 实验亮点
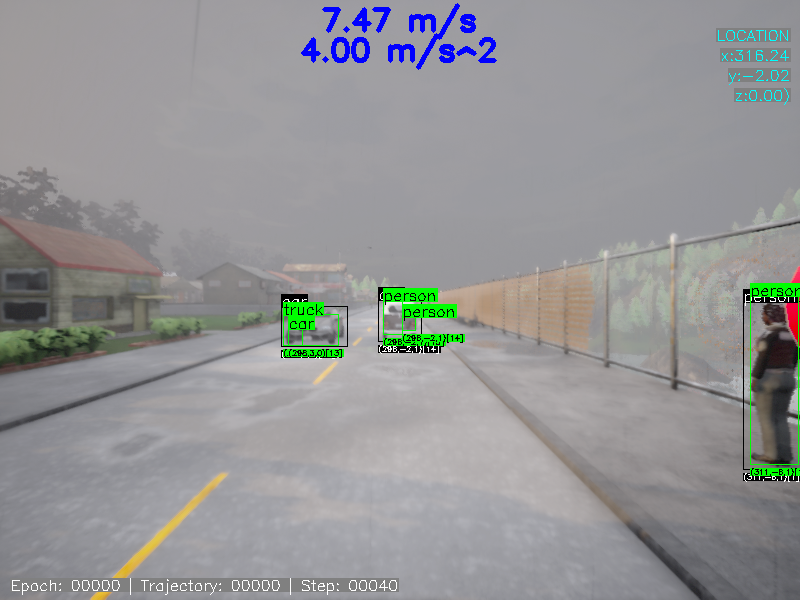
仿真结果表明,使用该方法训练的感知模型在系统级安全性方面显著优于基线感知模型。具体来说,在相同的场景下,使用该方法训练的模型能够减少碰撞事故的发生率,并提高系统的整体安全性。虽然论文中没有给出具体的数值提升比例,但强调了在系统级安全上的显著改善。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,例如自动驾驶汽车、无人配送车、工业机器人等。通过将系统级安全需求融入感知模型的训练中,可以显著提高自动驾驶系统的安全性,降低事故发生的概率。此外,该方法还可以推广到其他安全攸关的系统中,例如医疗机器人、航空航天系统等。
📄 摘要(原文)
Perception components in autonomous systems are often developed and optimized independently of downstream decision-making and control components, relying on established performance metrics like accuracy, precision, and recall. Traditional loss functions, such as cross-entropy loss and negative log-likelihood, focus on reducing misclassification errors but fail to consider their impact on system-level safety, overlooking the varying severities of system-level failures caused by these errors. To address this limitation, we propose a novel training paradigm that augments the perception component with an understanding of system-level safety objectives. Central to our approach is the translation of system-level safety requirements, formally specified using the rulebook formalism, into safety scores. These scores are then incorporated into the reward function of a reinforcement learning framework for fine-tuning perception models with system-level safety objectives. Simulation results demonstrate that models trained with this approach outperform baseline perception models in terms of system-level safety.