Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
作者: Xuanlin Li, Tong Zhao, Xinghao Zhu, Jiuguang Wang, Tao Pang, Kuan Fang
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-12-03 (更新: 2025-02-14)
💡 一句话要点
GLIDE:规划引导的扩散策略学习,用于通用接触式双手操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双手操作 扩散策略学习 运动规划 行为克隆 Sim-to-Real 机器人控制 接触操作
📋 核心要点
- 接触式双手操作任务复杂,现有方法难以获取足够数据并泛化到新场景。
- GLIDE利用运动规划器生成高质量模拟数据,并通过扩散策略学习控制策略。
- 通过特征提取、任务表示等优化,GLIDE在真实机器人上成功操作多种物体。
📝 摘要(中文)
接触式双手操作需要精确协调双臂,通过策略性选择的接触和运动来改变物体状态。由于任务的复杂性,获取足够的演示数据并训练能够泛化到未见场景的策略仍然是一个挑战。本文提出了一种名为通用规划引导扩散策略学习(GLIDE)的方法,该方法利用基于模型的运动规划器在高保真物理模拟中生成演示数据,从而有效地学习解决接触式双手操作任务。通过在随机环境中进行高效规划,该方法为涉及不同对象和转换的任务生成大规模高质量的合成运动轨迹。然后,我们使用这些演示数据,通过行为克隆训练一个任务条件扩散策略。为了解决模拟到真实的差距,我们提出了一组在特征提取、任务表示、动作预测和数据增强方面的关键设计选项,从而能够学习对平滑动作序列的鲁棒预测,并泛化到未见场景。通过在模拟和真实世界中的实验,我们证明了我们的方法能够使双臂机器人系统有效地操作具有不同几何形状、尺寸和物理属性的物体。
🔬 方法详解
问题定义:论文旨在解决接触式双手操作中,策略学习泛化性差的问题。现有方法依赖大量真实数据,获取成本高昂,且难以覆盖所有可能的场景。因此,训练出的策略难以泛化到未见过的物体和环境配置。
核心思路:论文的核心思路是利用基于模型的运动规划器生成大规模的合成数据,然后使用这些数据训练一个扩散策略。通过在随机化的模拟环境中进行规划,可以生成多样化的轨迹,从而提高策略的泛化能力。同时,使用扩散模型可以生成平滑的动作序列,更适合机器人控制。
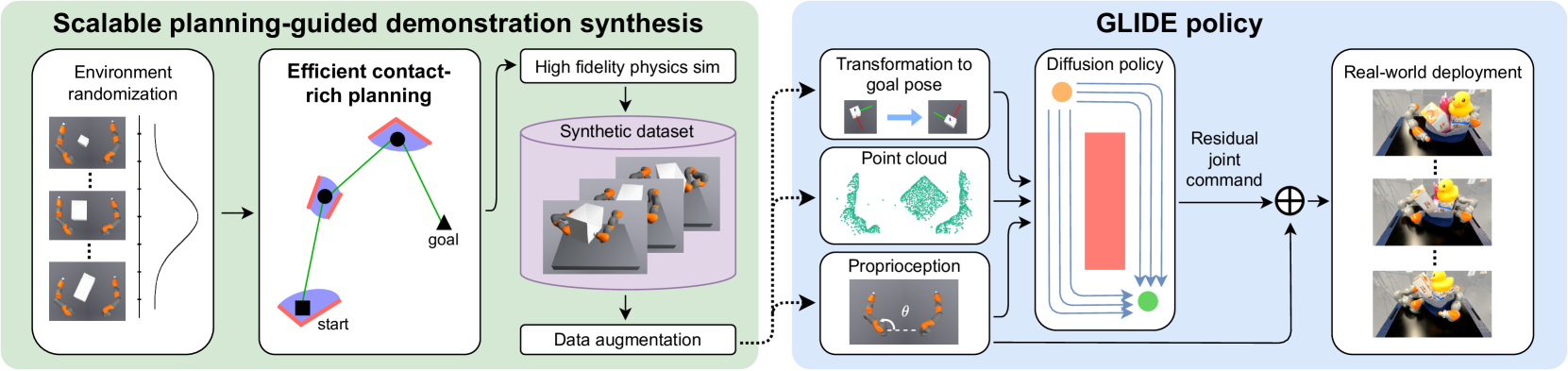
技术框架:GLIDE方法包含两个主要阶段:数据生成阶段和策略学习阶段。在数据生成阶段,使用运动规划器在随机化的模拟环境中生成大量的轨迹数据。在策略学习阶段,使用行为克隆方法,利用生成的数据训练一个任务条件扩散策略。该策略以当前状态和目标状态作为输入,输出一系列的动作序列。
关键创新:论文的关键创新在于将运动规划和扩散策略学习相结合,利用运动规划器生成高质量的训练数据,并使用扩散模型学习平滑的动作序列。此外,论文还提出了一系列针对sim-to-real的优化策略,包括特征提取、任务表示、动作预测和数据增强等。
关键设计:在特征提取方面,论文使用了低维度的状态表示,避免过拟合。在任务表示方面,论文使用了目标物体的位姿作为条件输入。在动作预测方面,论文使用了扩散模型生成平滑的动作序列。在数据增强方面,论文使用了随机噪声和扰动来增加数据的多样性。
🖼️ 关键图片

📊 实验亮点
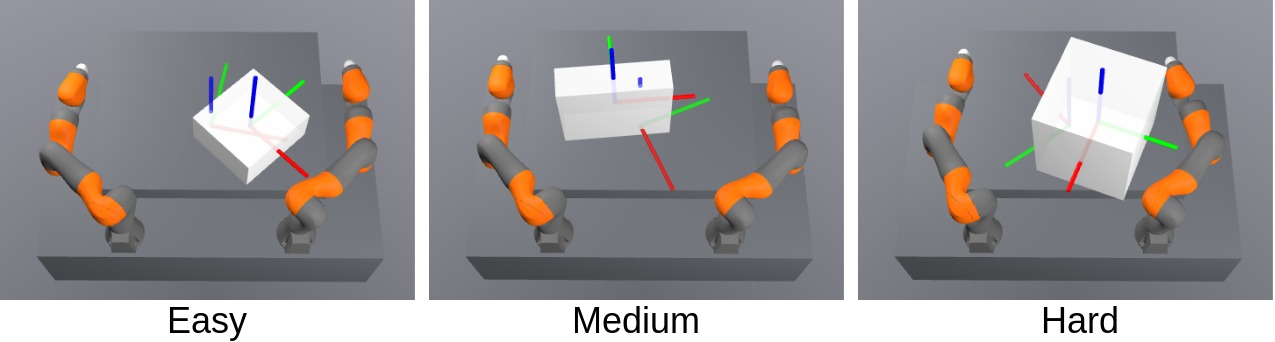
实验结果表明,GLIDE方法在模拟和真实机器人上都取得了显著的性能提升。在多个接触式双手操作任务中,GLIDE方法能够成功操作各种形状和属性的物体,并且具有良好的泛化能力。与基线方法相比,GLIDE方法在成功率和效率方面均有明显优势。
🎯 应用场景
该研究成果可应用于自动化装配、物体整理、医疗手术等领域。通过学习通用的操作策略,机器人可以灵活地处理各种形状和属性的物体,完成复杂的双手操作任务。该方法降低了对大量真实数据的依赖,有望加速机器人技术在实际场景中的应用。
📄 摘要(原文)
Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/