SparseGrasp: Robotic Grasping via 3D Semantic Gaussian Splatting from Sparse Multi-View RGB Images
作者: Junqiu Yu, Xinlin Ren, Yongchong Gu, Haitao Lin, Tianyu Wang, Yi Zhu, Hang Xu, Yu-Gang Jiang, Xiangyang Xue, Yanwei Fu
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-12-03
💡 一句话要点
SparseGrasp:基于稀疏多视角RGB图像和3D语义高斯溅射的机器人抓取
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 3D高斯溅射 稀疏视角 语义感知 场景重建 多轮抓取 DUSt3R
📋 核心要点
- 现有语言引导的机器人抓取方法依赖于密集的相机视图,难以快速更新场景,限制了其在可变环境中的有效性。
- SparseGrasp利用DUSt3R生成点云初始化3DGS,融合视觉基础模型的语义信息,并采用PCA压缩特征,提升效率。
- SparseGrasp通过渲染-比较策略实现快速场景更新,实验表明其在速度和适应性上优于现有方法,适用于多轮抓取。
📝 摘要(中文)
本文提出SparseGrasp,一种新颖的开放词汇机器人抓取系统,它能高效地利用稀疏视角的RGB图像,并能快速更新场景。该系统建立并显著增强了机器人学习中现有的计算机视觉模块。具体来说,SparseGrasp利用DUSt3R生成密集的点云,作为3D高斯溅射(3DGS)的初始化,即使在稀疏监督下也能保持高保真度。重要的是,SparseGrasp结合了来自最新视觉基础模型的语义感知。为了进一步提高处理效率,重新利用主成分分析(PCA)来压缩来自2D模型的特征。此外,还引入了一种新颖的渲染-比较策略,确保快速的场景更新,从而在可变环境中实现多轮抓取。实验结果表明,SparseGrasp在速度和适应性方面均显著优于最先进的方法,为可变环境中的多轮抓取提供了一个鲁棒的解决方案。
🔬 方法详解
问题定义:现有语言引导的机器人抓取方法通常需要密集的相机视图,这在实际应用中难以满足,尤其是在环境快速变化时。此外,现有方法更新场景的速度较慢,无法很好地支持多轮抓取任务。因此,如何利用稀疏的图像信息,快速更新场景,实现鲁棒的多轮抓取是本文要解决的关键问题。
核心思路:SparseGrasp的核心思路是利用稀疏的多视角RGB图像,通过3D语义高斯溅射(3DGS)来构建场景的稠密表示,并结合视觉基础模型的语义信息,从而实现高效、鲁棒的机器人抓取。通过DUSt3R生成高质量的点云作为3DGS的初始化,保证了在稀疏监督下的场景重建质量。同时,利用PCA进行特征压缩,并设计渲染-比较策略,加速场景更新。
技术框架:SparseGrasp系统的整体框架主要包含以下几个阶段:1) 稀疏图像输入:从多个稀疏视角获取RGB图像。2) 点云生成:利用DUSt3R从稀疏图像中生成稠密的点云,作为3DGS的初始化。3) 3DGS场景重建:使用3DGS对场景进行重建,并融合视觉基础模型的语义信息。4) 特征压缩:利用PCA对2D模型的特征进行压缩,提高处理效率。5) 抓取规划:基于重建的3D场景和语义信息,进行抓取规划。6) 场景更新:采用渲染-比较策略,快速更新场景,支持多轮抓取。
关键创新:SparseGrasp的关键创新点在于:1) 稀疏视角下的高保真场景重建:利用DUSt3R和3DGS,即使在稀疏视角下也能实现高质量的场景重建。2) 语义感知的抓取:融合了视觉基础模型的语义信息,提高了抓取的准确性和鲁棒性。3) 快速场景更新:引入了渲染-比较策略,实现了快速的场景更新,支持多轮抓取。
关键设计:在技术细节上,DUSt3R被用于生成高质量的初始点云,为3DGS提供良好的初始化。3DGS的训练过程采用了标准的优化方法,并结合了语义损失,以提高场景重建的语义一致性。PCA被用于压缩2D特征,减少计算量。渲染-比较策略通过比较渲染图像和真实图像的差异,来判断场景是否发生变化,并进行相应的更新。具体的参数设置和损失函数选择未知。
🖼️ 关键图片


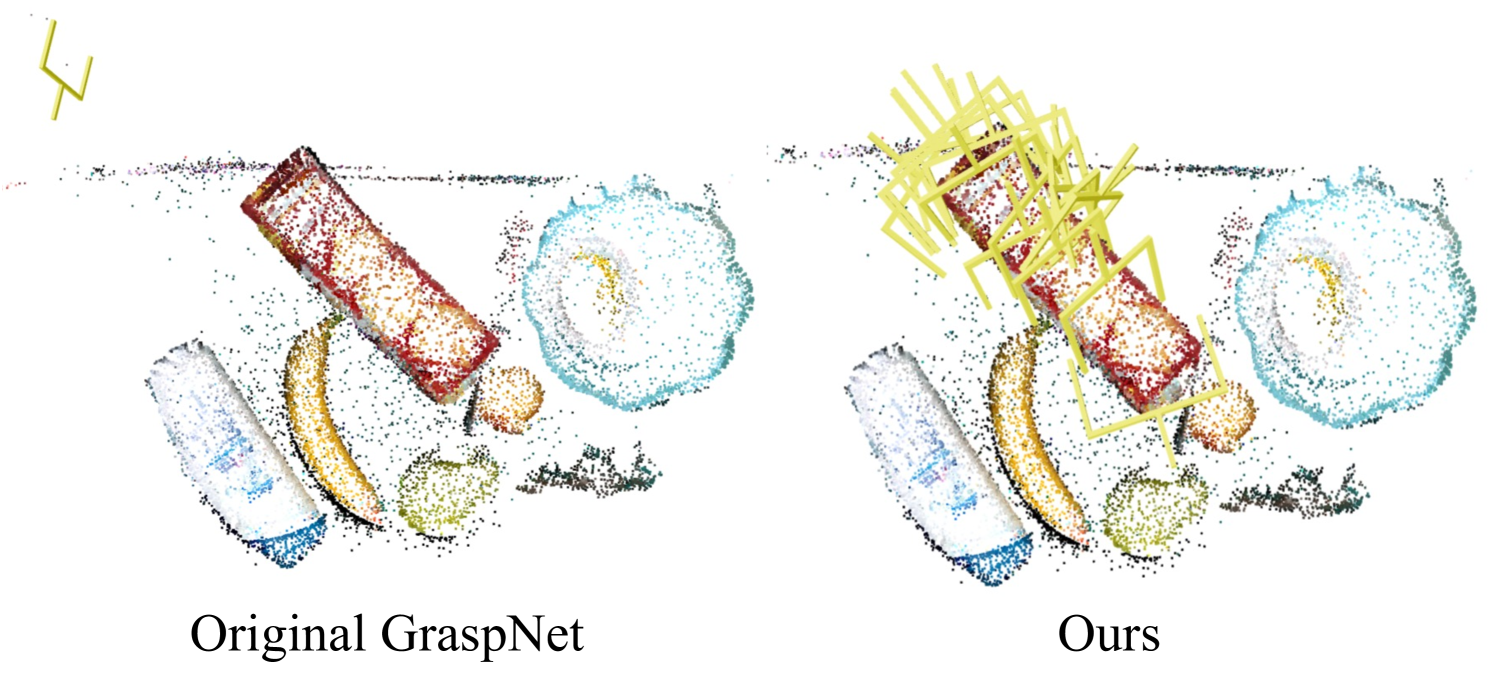
📊 实验亮点
实验结果表明,SparseGrasp在速度和适应性方面显著优于现有方法。具体性能数据未知,但摘要强调了其在可变环境中进行多轮抓取的鲁棒性。该方法通过稀疏视角RGB图像实现了高效的机器人抓取,并能快速更新场景,为机器人抓取领域带来了显著的进步。
🎯 应用场景
SparseGrasp在机器人抓取领域具有广泛的应用前景,尤其适用于环境快速变化的场景,如家庭服务机器人、仓库自动化、以及灾难救援等。该技术能够使机器人在稀疏视觉信息下,快速适应环境变化,完成复杂的抓取任务,具有重要的实际价值和潜在的社会影响。
📄 摘要(原文)
Language-guided robotic grasping is a rapidly advancing field where robots are instructed using human language to grasp specific objects. However, existing methods often depend on dense camera views and struggle to quickly update scenes, limiting their effectiveness in changeable environments. In contrast, we propose SparseGrasp, a novel open-vocabulary robotic grasping system that operates efficiently with sparse-view RGB images and handles scene updates fastly. Our system builds upon and significantly enhances existing computer vision modules in robotic learning. Specifically, SparseGrasp utilizes DUSt3R to generate a dense point cloud as the initialization for 3D Gaussian Splatting (3DGS), maintaining high fidelity even under sparse supervision. Importantly, SparseGrasp incorporates semantic awareness from recent vision foundation models. To further improve processing efficiency, we repurpose Principal Component Analysis (PCA) to compress features from 2D models. Additionally, we introduce a novel render-and-compare strategy that ensures rapid scene updates, enabling multi-turn grasping in changeable environments. Experimental results show that SparseGrasp significantly outperforms state-of-the-art methods in terms of both speed and adaptability, providing a robust solution for multi-turn grasping in changeable environment.