Robot Learning with Super-Linear Scaling
作者: Marcel Torne, Arhan Jain, Jiayi Yuan, Vidaaranya Macha, Lars Ankile, Anthony Simeonov, Pulkit Agrawal, Abhishek Gupta
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-12-02 (更新: 2025-10-11)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出CASHER,通过众包数字孪生和模拟学习实现机器人学习的超线性扩展。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人学习 强化学习 模拟到真实 数据收集 数字孪生 众包 泛化能力
📋 核心要点
- 现有机器人学习方法在数据收集方面依赖大量人工,限制了其扩展性。
- CASHER通过众包数字孪生和模拟学习,利用模型生成的演示逐步替代人工,实现超线性扩展。
- 实验表明,CASHER在真实场景中表现出良好的零样本和少样本泛化能力,并能有效微调策略。
📝 摘要(中文)
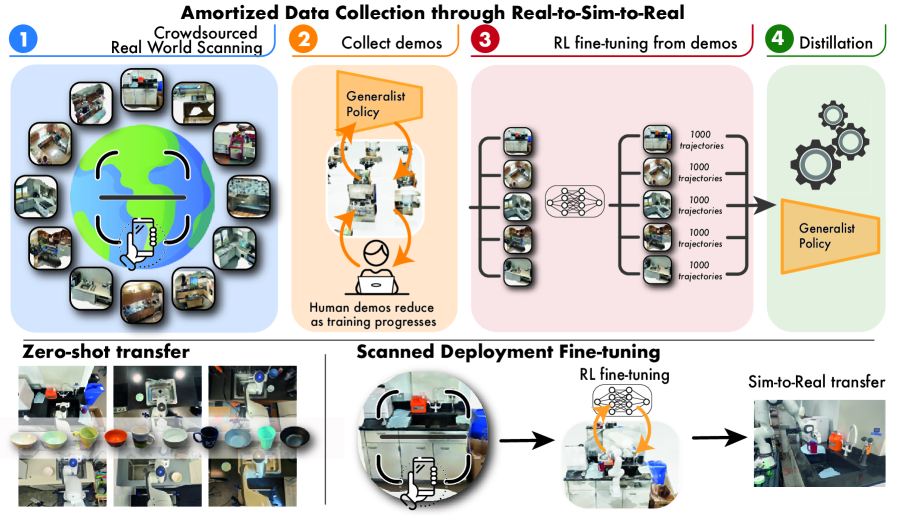
本文提出了一种名为CASHER(众包和分摊人类努力以实现Real-to-Sim-to-Real)的机器人学习流水线,旨在扩展数据收集和模拟学习,其性能随人类投入呈超线性增长。核心思想是利用3D重建技术众包真实场景的数字孪生,并在模拟环境中收集大规模数据,而非直接在现实世界中进行。模拟环境中的数据收集最初由强化学习驱动,并以人类演示作为引导。随着通用策略在不同环境中训练的进行,其泛化能力可用于替代人类演示,从而不断减少人类投入。实验表明,CASHER在三个真实世界的任务中展示了零样本和少样本的扩展规律,并且能够利用视频扫描微调预训练策略到目标场景,而无需额外的人工干预。
🔬 方法详解
问题定义:机器人学习面临数据收集效率低下的问题,尤其是在真实环境中。传统方法需要大量人工干预,成本高昂且难以扩展。现有方法难以充分利用模拟环境的优势,实现从模拟到真实的有效迁移。
核心思路:CASHER的核心思路是利用众包的方式构建真实场景的数字孪生,并在模拟环境中进行大规模数据收集和策略训练。随着策略的泛化能力提升,逐步减少对人工演示的依赖,最终实现超线性扩展。通过模拟环境训练的策略可以零样本或少样本迁移到真实世界。
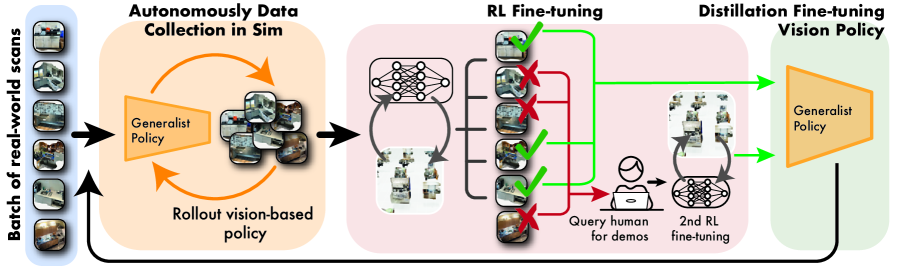
技术框架:CASHER包含以下主要阶段:1) 场景重建:通过众包方式,利用3D重建技术构建真实场景的数字孪生。2) 模拟数据生成:在模拟环境中,利用强化学习和人类演示生成训练数据。初始阶段依赖人类演示引导,后续逐步利用训练好的策略生成数据,减少人工干预。3) 策略训练:利用生成的数据训练通用策略,使其具备良好的泛化能力。4) 策略迁移:将训练好的策略迁移到真实世界,并进行微调。
关键创新:CASHER的关键创新在于其数据收集方式。通过众包数字孪生和模型生成演示,实现了数据收集效率的超线性提升。与传统方法相比,CASHER显著减少了对人工干预的依赖,降低了数据收集成本。
关键设计:CASHER使用强化学习算法(具体算法未知)在模拟环境中训练策略。人类演示用于引导初始阶段的策略学习。损失函数的设计需要考虑模拟环境与真实环境的差异,以保证策略的有效迁移。具体的网络结构和参数设置在论文中可能有所描述(未知)。
🖼️ 关键图片

📊 实验亮点
CASHER在三个真实世界的任务中展示了零样本和少样本的扩展规律。实验结果表明,CASHER能够利用视频扫描微调预训练策略到目标场景,而无需额外的人工干预。具体的性能提升数据和对比基线在论文中可能有所描述(未知)。
🎯 应用场景
CASHER具有广泛的应用前景,可应用于工业自动化、家庭服务机器人、自动驾驶等领域。通过降低数据收集成本,加速机器人学习的进程,使得机器人能够更快速、更有效地适应各种复杂环境,完成各种任务。该方法有望推动机器人技术的普及和应用。
📄 摘要(原文)
Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort. See our project website: https://casher-robot-learning.github.io/CASHER/