Planning and Reasoning with 3D Deformable Objects for Hierarchical Text-to-3D Robotic Shaping
作者: Alison Bartsch, Amir Barati Farimani
分类: cs.RO
发布日期: 2024-12-02 (更新: 2025-03-03)
💡 一句话要点
提出基于分层规划的文本到3D机器人雕塑系统,解决可变形物体操作难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人雕塑 可变形物体操作 文本到3D 分层规划 大型语言模型
📋 核心要点
- 可变形物体操作是机器人自主化的难点,现有方法难以应对真实场景下的复杂性。
- 提出一种由粗到精的分层雕塑系统,利用大语言模型生成子目标,并训练点云动作模型。
- 实验表明,该系统仅通过文本提示即可成功创建3D形状,并探讨了评估指标与人类感知的相关性。
📝 摘要(中文)
本文旨在解决自主机器人系统中可变形物体操作的关键挑战,通过将粘土雕塑成3D形状的任务进行研究。我们提出了首个由粗到精的自主雕塑系统,该系统首先选择在工作空间中放置离散粘土块的数量和位置,以创建粗略形状,然后通过一系列变形动作迭代地细化形状。我们利用大型语言模型进行子目标生成,并训练基于点云区域的动作模型,以从所需的点云子目标预测机器人动作。此外,我们的方法是第一个无需任何显式3D目标或子目标即可实现的真实文本到3D形状的自主雕塑系统。我们证明了我们的方法能够仅通过基于文本的提示成功创建一组简单的形状。此外,我们严格地探讨了如何最好地量化文本到3D雕塑任务的成功,并将现有的文本-图像和文本-点云相似性指标与该任务的人工评估进行比较。实验视频、人工评估细节和完整提示请参见我们的项目网站。
🔬 方法详解
问题定义:论文旨在解决机器人自主雕塑可变形物体的问题,特别是将文本描述转化为3D形状。现有方法通常需要明确的3D目标或子目标,限制了其灵活性和泛化能力。此外,如何有效评估文本到3D雕塑的质量也是一个挑战。
核心思路:该论文的核心思路是采用分层规划策略,将复杂的雕塑任务分解为粗略形状构建和精细形状调整两个阶段。利用大型语言模型生成中间子目标,指导机器人逐步完成雕塑任务。这种分层方法降低了任务的复杂度,提高了系统的鲁棒性。
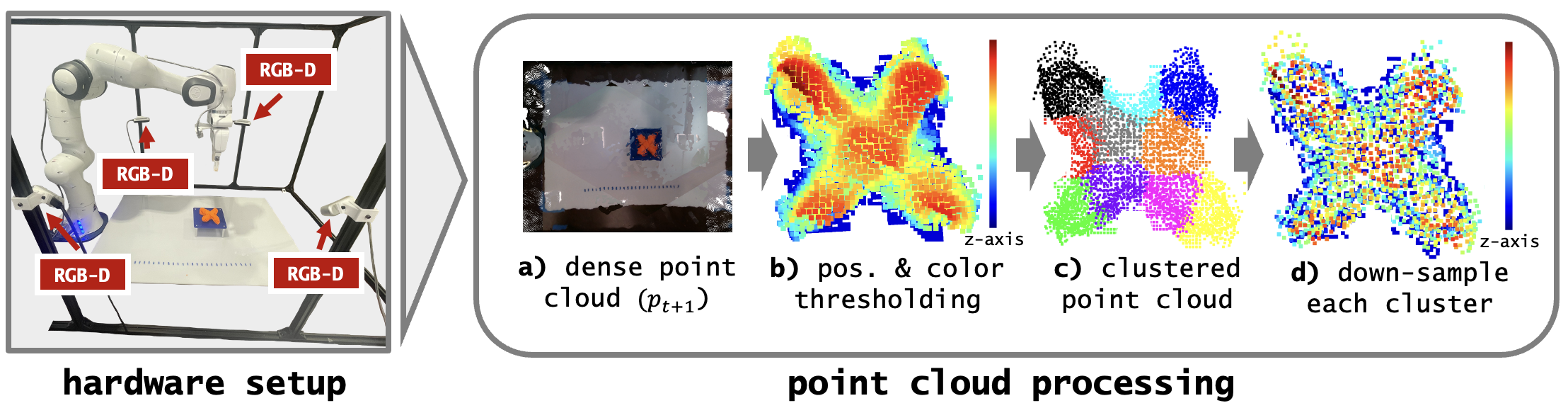
技术框架:该系统包含以下主要模块:1) 文本输入模块:接收用户输入的文本描述。2) 子目标生成模块:利用大型语言模型将文本描述转化为一系列3D点云子目标。3) 粗略形状构建模块:根据子目标,选择粘土块的数量和位置,构建初始的粗略形状。4) 精细形状调整模块:通过点云区域动作模型,预测机器人变形动作,逐步细化形状,使其逼近目标形状。5) 评估模块:采用文本-图像和文本-点云相似性指标,并结合人工评估,量化雕塑结果的质量。
关键创新:该论文的关键创新在于:1) 提出了一种无需显式3D目标或子目标的文本到3D雕塑系统,提高了系统的自主性和灵活性。2) 采用分层规划策略,将复杂的雕塑任务分解为多个子任务,降低了任务的难度。3) 利用大型语言模型生成子目标,为机器人提供了更高级别的指导。
关键设计:点云区域动作模型是关键设计之一,该模型基于点云区域特征预测机器人动作。损失函数可能包含点云距离损失、形状相似性损失等。具体网络结构未知,但推测可能采用PointNet或PointNet++等点云处理网络。
🖼️ 关键图片

📊 实验亮点
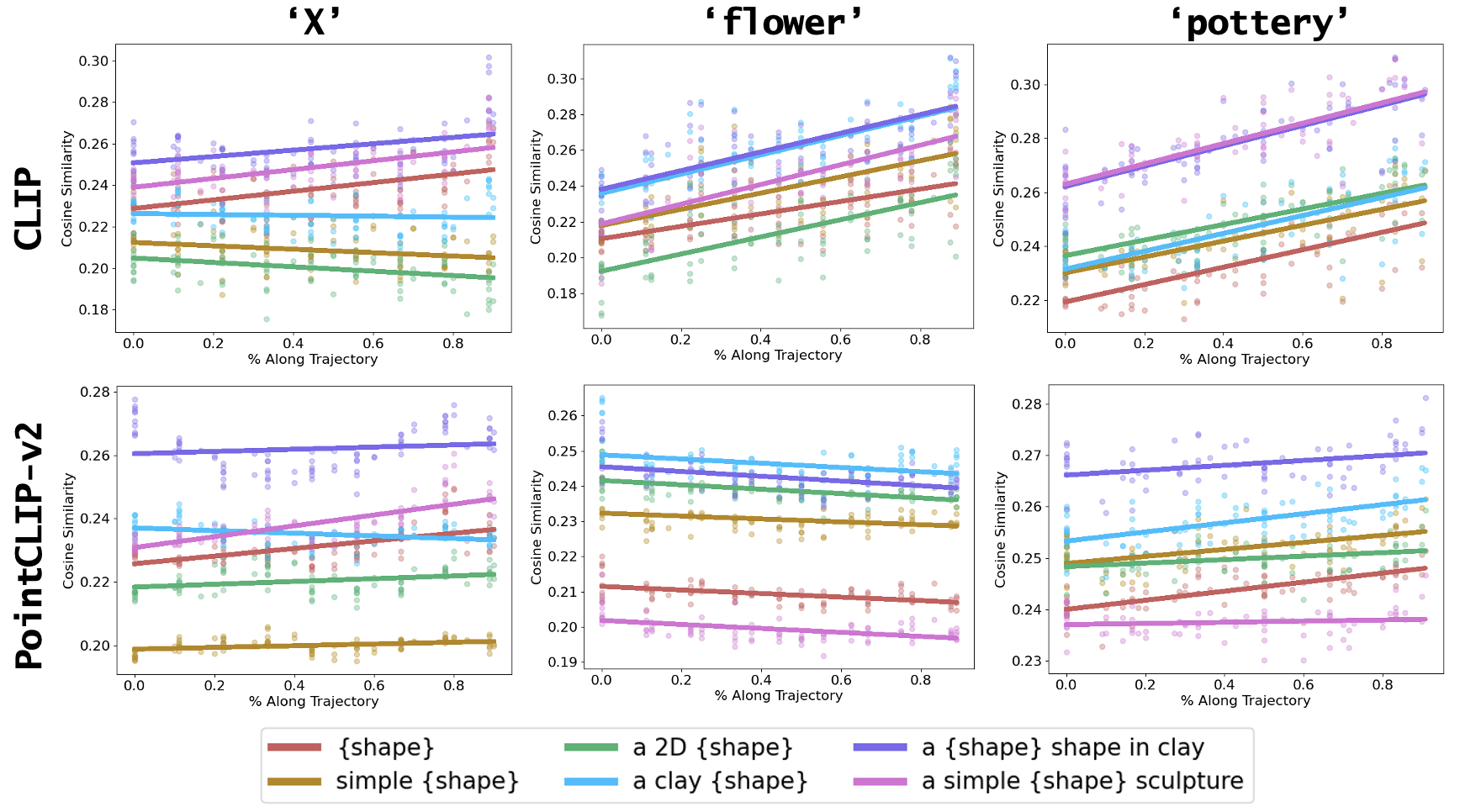
该方法成功实现了仅通过文本提示创建3D形状,无需任何显式3D目标或子目标。论文对比了不同的文本-图像和文本-点云相似性指标,并与人工评估结果进行了比较,为文本到3D雕塑任务的评估提供了参考。具体的性能数据和提升幅度未知,但实验结果表明该方法具有一定的可行性和有效性。
🎯 应用场景
该研究成果可应用于自动化制造、艺术创作、教育培训等领域。例如,可以用于定制化产品的快速原型设计,辅助艺术家进行雕塑创作,或用于机器人辅助的艺术教育。未来,该技术有望扩展到其他可变形物体的操作,如布料、绳索等,实现更广泛的机器人应用。
📄 摘要(原文)
Deformable object manipulation remains a key challenge in developing autonomous robotic systems that can be successfully deployed in real-world scenarios. In this work, we explore the challenges of deformable object manipulation through the task of sculpting clay into 3D shapes. We propose the first coarse-to-fine autonomous sculpting system in which the sculpting agent first selects how many and where to place discrete chunks of clay into the workspace to create a coarse shape, and then iteratively refines the shape with sequences of deformation actions. We leverage large language models for sub-goal generation, and train a point cloud region-based action model to predict robot actions from the desired point cloud sub-goals. Additionally, our method is the first autonomous sculpting system that is a real-world text-to-3D shaping pipeline without any explicit 3D goals or sub-goals provided to the system. We demonstrate our method is able to successfully create a set of simple shapes solely from text-based prompting. Furthermore, we explore rigorously how to best quantify success for the text-to-3D sculpting task, and compare existing text-image and text-point cloud similarity metrics to human evaluations for this task. For experimental videos, human evaluation details, and full prompts, please see our project website: https://sites.google.com/andrew.cmu.edu/hierarchicalsculpting