One-Shot Real-to-Sim via End-to-End Differentiable Simulation and Rendering
作者: Yifan Zhu, Tianyi Xiang, Aaron Dollar, Zherong Pan
分类: cs.RO, cs.CV, cs.GR
发布日期: 2024-11-29 (更新: 2025-05-11)
备注: 8 pages, 8 figures. Published at IEEE Robotics Automation Letters
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于可微模拟与渲染的单样本Real-to-Sim方法,用于机器人环境建模。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人 世界模型 可微渲染 可微模拟 Real-to-Sim 环境建模 单样本学习
📋 核心要点
- 现有方法难以联合优化场景的几何、外观和物理属性,限制了机器人世界模型的构建。
- 提出一种新的刚性物体表示,结合可微点云几何表示和网格外观场,实现可微碰撞检测和渲染。
- 通过单次机器人动作序列的视觉和触觉观测,端到端地学习可用于模拟和渲染的世界模型。
📝 摘要(中文)
在稀疏的在线观测中,为处于新环境中的机器人识别具有预测性的世界模型,对于机器人在新环境中进行任务规划和执行至关重要。然而,现有利用可微编程识别世界模型的方法无法联合优化场景的几何形状、外观和物理属性。本文提出了一种新的刚性物体表示方法,可以联合识别这些属性。该方法采用了一种新的基于可微点的几何表示,并结合了基于网格的外观场,从而实现可微的物体碰撞检测和渲染。结合可微物理模拟器,我们实现了世界模型的端到端优化,给定物理运动序列的稀疏视觉和触觉观测。通过一系列模拟和真实环境中的世界模型识别任务,我们证明了该方法仅需一个机器人动作序列即可学习到可用于模拟和渲染的世界模型。代码和更多视频可在项目网站上找到:https://tianyi20.github.io/rigid-world-model.github.io/
🔬 方法详解
问题定义:现有基于可微编程的世界模型构建方法,无法同时优化场景中物体的几何形状、外观以及物理属性。这导致构建的仿真环境与真实环境存在较大差异,影响了机器人在仿真环境中学习策略向真实环境的迁移效果。现有方法通常需要大量的训练数据或者复杂的预处理步骤,难以适应真实世界中数据稀疏的场景。
核心思路:论文的核心思路是设计一种可微的刚性物体表示方法,该方法能够同时表示物体的几何形状和外观,并且能够进行可微的碰撞检测和渲染。通过结合可微的物理模拟器,可以实现端到端的优化,从而仅使用少量的观测数据即可构建高质量的世界模型。这种方法允许模型从真实数据中学习,并直接应用于仿真环境,从而减少了真实环境和仿真环境之间的差距。
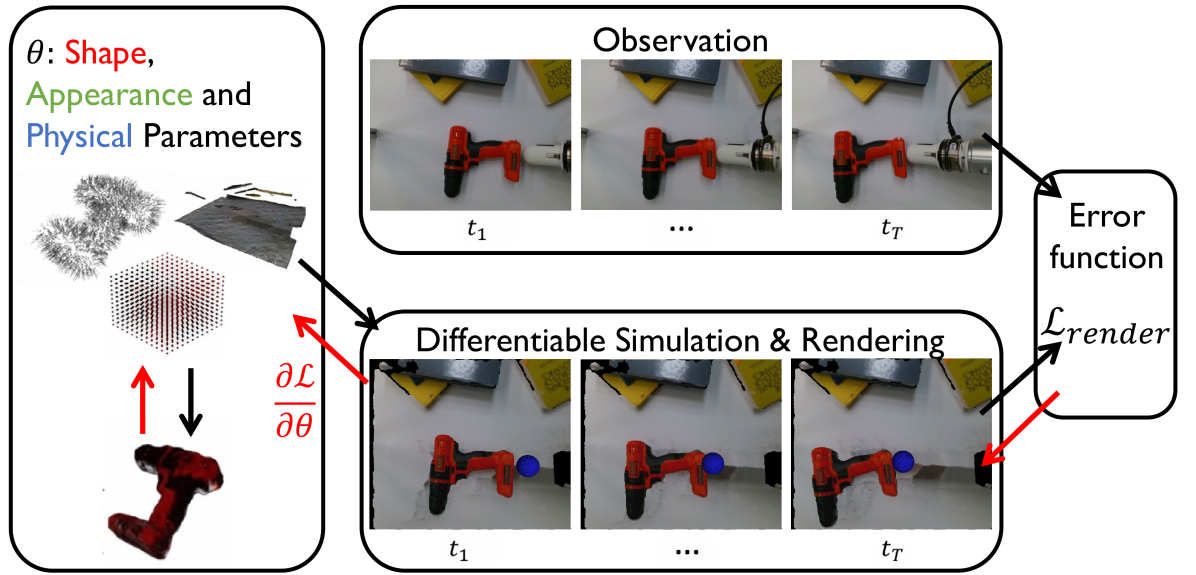
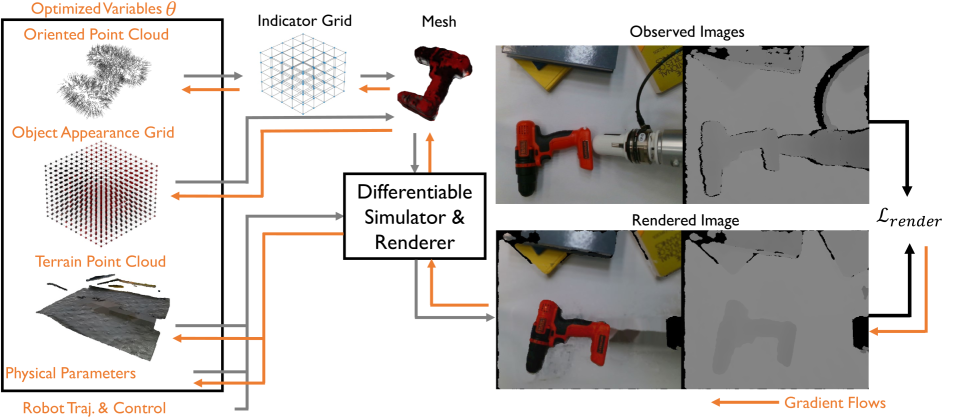
技术框架:该方法主要包含以下几个模块:1) 可微点云几何表示模块:使用点云来表示物体的几何形状,并设计可微的操作,例如碰撞检测。2) 网格外观场模块:使用网格来表示物体的外观,并设计可微的渲染方法。3) 可微物理模拟器:使用可微的物理引擎来模拟物体的运动。4) 优化模块:使用梯度下降等优化算法来优化物体的几何形状、外观和物理属性,使得模拟结果与真实观测尽可能一致。整个流程是端到端可微的,允许联合优化所有模块的参数。
关键创新:该方法最重要的创新点在于提出了一种新的刚性物体表示方法,该方法能够同时表示物体的几何形状和外观,并且能够进行可微的碰撞检测和渲染。与现有方法相比,该方法能够更加准确地表示物体的几何形状和外观,并且能够进行端到端的优化,从而仅使用少量的观测数据即可构建高质量的世界模型。此外,该方法还结合了可微物理模拟器,使得构建的世界模型可以直接用于仿真环境。
关键设计:在几何表示方面,使用了基于点的表示,每个点都有位置和法向量信息。外观表示方面,使用了基于网格的表示,每个网格单元都有颜色和纹理信息。碰撞检测使用了基于梯度的可微方法。损失函数包括视觉损失(渲染图像与真实图像的差异)和触觉损失(模拟触觉数据与真实触觉数据的差异)。优化算法使用了Adam优化器,学习率设置为0.001。网络结构方面,几何和外观表示都使用了多层感知机(MLP)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法仅需一个机器人动作序列即可学习到可用于模拟和渲染的世界模型。在模拟和真实环境中的世界模型识别任务中,该方法都取得了良好的效果。与现有方法相比,该方法能够更加准确地表示物体的几何形状和外观,并且能够进行端到端的优化,从而仅使用少量的观测数据即可构建高质量的世界模型。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、增强现实等领域。例如,机器人可以在新环境中通过少量交互快速构建环境模型,从而进行有效的任务规划和执行。在自动驾驶领域,可以利用该方法构建高精度的交通场景模型,提高自动驾驶系统的安全性。在增强现实领域,可以利用该方法将虚拟物体无缝地融入真实场景。
📄 摘要(原文)
Identifying predictive world models for robots in novel environments from sparse online observations is essential for robot task planning and execution in novel environments. However, existing methods that leverage differentiable programming to identify world models are incapable of jointly optimizing the geometry, appearance, and physical properties of the scene. In this work, we introduce a novel rigid object representation that allows the joint identification of these properties. Our method employs a novel differentiable point-based geometry representation coupled with a grid-based appearance field, which allows differentiable object collision detection and rendering. Combined with a differentiable physical simulator, we achieve end-to-end optimization of world models, given the sparse visual and tactile observations of a physical motion sequence. Through a series of world model identification tasks in simulated and real environments, we show that our method can learn both simulation- and rendering-ready world models from only one robot action sequence. The code and additional videos are available at our project website: https://tianyi20.github.io/rigid-world-model.github.io/