Visual SLAMMOT Considering Multiple Motion Models
作者: Peilin Tian, Hao Li
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-11-28 (更新: 2025-08-14)
💡 一句话要点
提出基于多运动模型的视觉SLAMMOT,提升动态环境下SLAM和MOT的精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 多目标跟踪 多运动模型 动态环境 自动驾驶
📋 核心要点
- 传统SLAM在动态环境下的性能受限,MOT则依赖于车辆状态的先验信息,两者独立运行存在不足。
- 该论文提出将多运动模型融入视觉SLAMMOT,通过紧耦合SLAM和MOT,提升动态环境下的定位和跟踪精度。
- 该研究验证了在视觉SLAMMOT中采用多运动模型的优势,为视觉SLAM在动态环境下的应用提供了新的思路。
📝 摘要(中文)
同步定位与地图构建(SLAM)和多目标跟踪(MOT)是自动驾驶领域中的关键任务。SLAM旨在实时生成地图并确定车辆在未知环境中的位姿,而MOT则专注于实时识别和跟踪多个动态目标。然而,目前常见的方法是将SLAM和MOT视为自动驾驶系统中的独立模块,这导致了固有的局限性。传统的SLAM方法通常依赖于静态环境假设,更适用于室内而非动态的室外场景。另一方面,传统的MOT技术通常依赖于车辆的已知状态,限制了基于此先验的目标状态估计的准确性。为了解决这些挑战,之前的研究提出了统一的SLAMMOT范式,但主要集中于简单的运动模式。本文基于团队之前的研究IMM-SLAMMOT,探索了将多运动模型融入视觉SLAMMOT的可行性和优势,弥合了激光雷达和视觉传感机制之间的差距。具体而言,我们提出了一种考虑多运动模型的视觉SLAMMOT解决方案,并验证了IMM-SLAMMOT在视觉领域中的固有优势。
🔬 方法详解
问题定义:现有的SLAM和MOT系统通常作为独立的模块运行,SLAM假设环境静态,而MOT依赖车辆状态先验。这在动态环境中导致SLAM精度下降,MOT目标状态估计不准确。因此,需要一种能够同时处理SLAM和MOT,并能适应动态环境的解决方案。
核心思路:核心思路是将多运动模型(Multiple Motion Models)集成到视觉SLAMMOT框架中。通过考虑多个可能的运动模型,系统能够更好地适应动态环境中目标的不同运动模式,从而提高SLAM的定位精度和MOT的目标跟踪精度。
技术框架:该视觉SLAMMOT系统包含以下主要模块:1) 视觉里程计(Visual Odometry):用于估计相机的运动;2) 地图构建(Mapping):用于构建环境地图;3) 多目标检测与跟踪(Multi-Object Detection and Tracking):用于检测和跟踪动态目标;4) 多运动模型估计(Multiple Motion Model Estimation):用于估计每个目标的运动模型;5) 状态融合(State Fusion):将SLAM和MOT的结果进行融合,以提高整体性能。
关键创新:关键创新在于将多运动模型集成到视觉SLAMMOT框架中。与传统的SLAMMOT方法相比,该方法能够更好地适应动态环境,提高SLAM的定位精度和MOT的目标跟踪精度。此外,该研究将之前基于激光雷达的IMM-SLAMMOT扩展到了视觉领域,弥合了两种传感方式之间的差距。
关键设计:具体的运动模型选择和参数设置未知,损失函数和网络结构也未在摘要中提及。但可以推测,运动模型的选择可能包括恒定速度模型、恒定加速度模型等。状态融合可能采用卡尔曼滤波或扩展卡尔曼滤波等方法。
🖼️ 关键图片

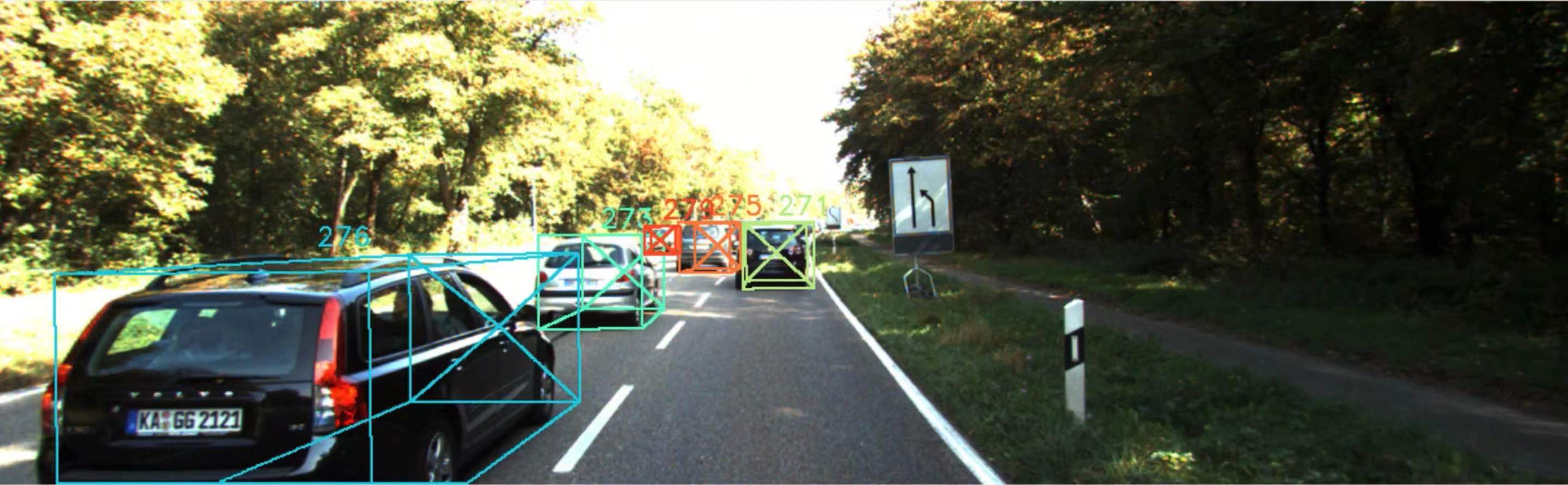
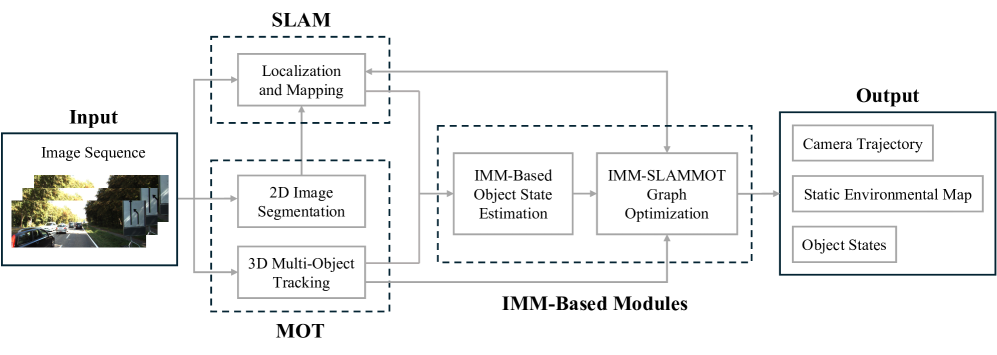
📊 实验亮点
摘要中未提供具体的实验结果和性能数据,但强调了该方法在视觉SLAMMOT中考虑多运动模型的优势,并验证了IMM-SLAMMOT在视觉领域中的可行性。未来的工作可能会提供更详细的实验结果,包括与现有方法的对比以及在不同数据集上的性能评估。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,该方法可以提高车辆在复杂动态环境下的定位和感知能力,从而提高驾驶安全性。在机器人导航中,该方法可以帮助机器人在动态环境中进行更准确的定位和导航。在增强现实中,该方法可以实现更稳定的虚拟物体与真实环境的融合。
📄 摘要(原文)
Simultaneous Localization and Mapping (SLAM) and Multi-Object Tracking (MOT) are pivotal tasks in the realm of autonomous driving, attracting considerable research attention. While SLAM endeavors to generate real-time maps and determine the vehicle's pose in unfamiliar settings, MOT focuses on the real-time identification and tracking of multiple dynamic objects. Despite their importance, the prevalent approach treats SLAM and MOT as independent modules within an autonomous vehicle system, leading to inherent limitations. Classical SLAM methodologies often rely on a static environment assumption, suitable for indoor rather than dynamic outdoor scenarios. Conversely, conventional MOT techniques typically rely on the vehicle's known state, constraining the accuracy of object state estimations based on this prior. To address these challenges, previous efforts introduced the unified SLAMMOT paradigm, yet primarily focused on simplistic motion patterns. In our team's previous work IMM-SLAMMOT\cite{IMM-SLAMMOT}, we present a novel methodology incorporating consideration of multiple motion models into SLAMMOT i.e. tightly coupled SLAM and MOT, demonstrating its efficacy in LiDAR-based systems. This paper studies feasibility and advantages of instantiating this methodology as visual SLAMMOT, bridging the gap between LiDAR and vision-based sensing mechanisms. Specifically, we propose a solution of visual SLAMMOT considering multiple motion models and validate the inherent advantages of IMM-SLAMMOT in the visual domain.