ELEMENTAL: Interactive Learning from Demonstrations and Vision-Language Models for Reward Design in Robotics
作者: Letian Chen, Nina Moorman, Matthew Gombolay
分类: cs.RO, cs.LG
发布日期: 2024-11-27 (更新: 2025-05-09)
备注: ICML 2025
💡 一句话要点
ELEMENTAL:结合演示学习与视觉-语言模型,交互式机器人奖励函数设计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 强化学习 逆强化学习 视觉语言模型 人机交互
📋 核心要点
- 现有机器人强化学习依赖人工设计的复杂奖励函数,大型语言模型在机器人奖励函数设计中存在泛化性差和特征权重难以平衡等问题。
- ELEMENTAL框架结合自然语言指导和视觉演示,利用逆强化学习平衡特征权重,并通过迭代反馈循环改进学习效果。
- 实验结果表明,ELEMENTAL在任务成功率和泛化能力上显著优于现有方法,证明了其在机器人演示学习中的有效性。
📝 摘要(中文)
强化学习(RL)在机器人任务中表现出色,但通常依赖于复杂且专门设计的奖励函数。研究人员探索了如何利用大型语言模型(LLM)来简化非专业用户指定奖励函数的过程。然而,LLM难以平衡不同特征的重要性,泛化到分布外的机器人任务效果不佳,并且仅基于文本描述无法正确表示问题。为了解决这些挑战,我们提出了ELEMENTAL(intEractive LEarning froM dEmoNstraTion And Language),这是一个新颖的框架,它结合了自然语言指导和视觉用户演示,以更好地使机器人行为与用户意图对齐。通过结合视觉输入,ELEMENTAL克服了纯文本任务规范的局限性,同时利用逆强化学习(IRL)来平衡特征权重并最佳地匹配演示行为。ELEMENTAL还引入了一个通过自我反思的迭代反馈循环,以改进特征、奖励和策略学习。实验结果表明,ELEMENTAL在任务成功率上优于先前工作42.3%,并且在分布外任务中实现了41.3%的更好泛化,突出了其在LfD中的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决机器人强化学习中奖励函数设计困难的问题。现有方法,特别是基于大型语言模型的方法,在平衡不同特征的重要性、泛化到新的任务环境以及仅通过文本描述准确表达用户意图方面存在局限性。这些局限性导致机器人难以学习到符合用户期望的行为。
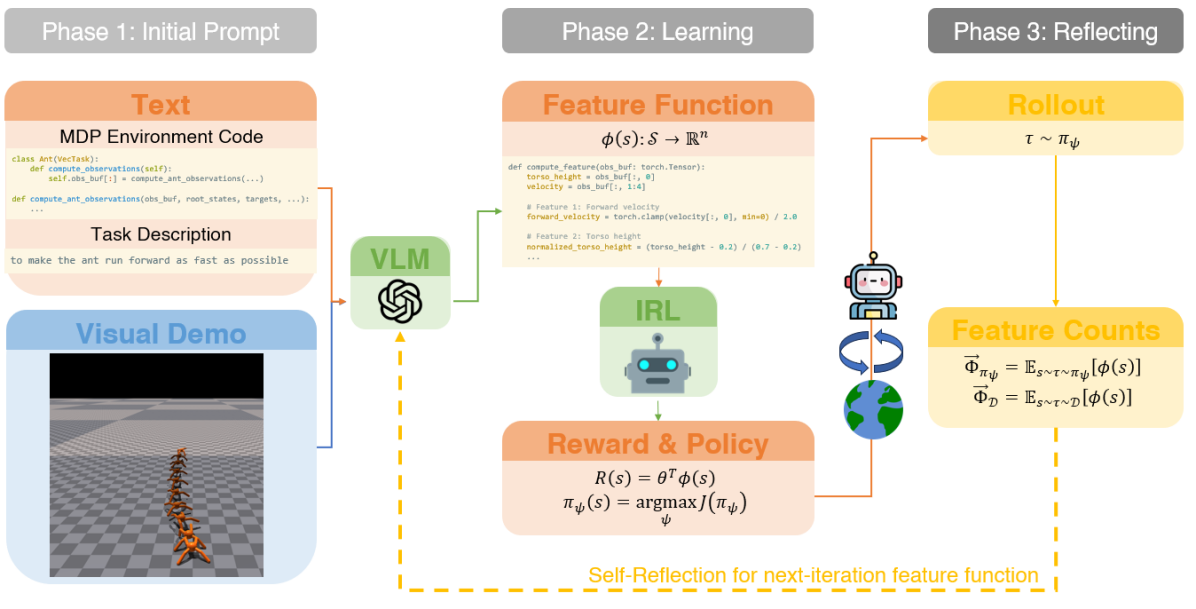
核心思路:ELEMENTAL的核心思路是结合自然语言指导和视觉用户演示,利用逆强化学习(IRL)从演示中学习奖励函数,并使用迭代反馈循环来改进学习过程。通过视觉输入,模型可以更好地理解任务环境和用户意图,克服了纯文本描述的不足。IRL用于自动平衡不同特征的权重,确保学习到的奖励函数能够产生与演示行为一致的策略。
技术框架:ELEMENTAL框架包含以下主要模块:1) 视觉-语言输入模块,接收用户的自然语言指令和视觉演示;2) 特征提取模块,从视觉输入中提取相关特征;3) 逆强化学习模块,利用演示数据学习奖励函数;4) 策略学习模块,使用强化学习算法训练机器人策略;5) 自我反思模块,评估当前策略的性能并生成反馈,用于改进特征、奖励和策略学习。整个框架通过迭代的方式不断优化,最终得到符合用户意图的机器人行为。
关键创新:ELEMENTAL的关键创新在于结合了视觉用户演示和自然语言指导,克服了纯文本描述的局限性。此外,引入了自我反思机制,通过迭代反馈循环不断改进学习效果。这种结合使得模型能够更好地理解用户意图,并学习到更鲁棒和泛化的机器人策略。与现有方法相比,ELEMENTAL能够更有效地利用用户提供的少量演示数据,并自动平衡不同特征的权重。
关键设计:ELEMENTAL使用逆强化学习算法(具体算法未知)从演示数据中学习奖励函数。视觉特征提取模块的具体网络结构未知,但需要能够提取与任务相关的视觉信息。自我反思模块的设计细节未知,但需要能够评估当前策略的性能并生成有用的反馈信号。损失函数的设计需要能够鼓励学习到的策略与演示行为一致,并惩罚不符合用户意图的行为。
🖼️ 关键图片


📊 实验亮点
ELEMENTAL在任务成功率上比现有方法提高了42.3%,并且在分布外任务中实现了41.3%的泛化性能提升。这些结果表明,ELEMENTAL能够更有效地利用用户提供的演示数据,并学习到更鲁棒和泛化的机器人策略。该研究为机器人演示学习领域带来了显著的进步。
🎯 应用场景
该研究成果可应用于各种机器人任务,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过结合自然语言指导和视觉演示,用户可以更轻松地训练机器人完成复杂任务,而无需专业的编程知识。该技术有望降低机器人应用门槛,促进机器人技术的普及。
📄 摘要(原文)
Reinforcement learning (RL) has demonstrated compelling performance in robotic tasks, but its success often hinges on the design of complex, ad hoc reward functions. Researchers have explored how Large Language Models (LLMs) could enable non-expert users to specify reward functions more easily. However, LLMs struggle to balance the importance of different features, generalize poorly to out-of-distribution robotic tasks, and cannot represent the problem properly with only text-based descriptions. To address these challenges, we propose ELEMENTAL (intEractive LEarning froM dEmoNstraTion And Language), a novel framework that combines natural language guidance with visual user demonstrations to align robot behavior with user intentions better. By incorporating visual inputs, ELEMENTAL overcomes the limitations of text-only task specifications, while leveraging inverse reinforcement learning (IRL) to balance feature weights and match the demonstrated behaviors optimally. ELEMENTAL also introduces an iterative feedback-loop through self-reflection to improve feature, reward, and policy learning. Our experiment results demonstrate that ELEMENTAL outperforms prior work by 42.3% on task success, and achieves 41.3% better generalization in out-of-distribution tasks, highlighting its robustness in LfD.