G3Flow: Generative 3D Semantic Flow for Pose-aware and Generalizable Object Manipulation
作者: Tianxing Chen, Yao Mu, Zhixuan Liang, Zanxin Chen, Shijia Peng, Qiangyu Chen, Mingkun Xu, Ruizhen Hu, Hongyuan Zhang, Xuelong Li, Ping Luo
分类: cs.RO, cs.AI, cs.CV, eess.SY
发布日期: 2024-11-27 (更新: 2025-06-22)
备注: Webpage: https://tianxingchen.github.io/G3Flow/, accepted to CVPR 2025
💡 一句话要点
G3Flow:用于姿态感知和可泛化物体操作的生成式3D语义流
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 语义流 扩散模型 模仿学习 3D生成模型 视觉基础模型 姿态跟踪
📋 核心要点
- 现有的基于扩散模型的机器人操作模仿学习方法,难以兼顾几何精度和语义理解,限制了操作的灵活性。
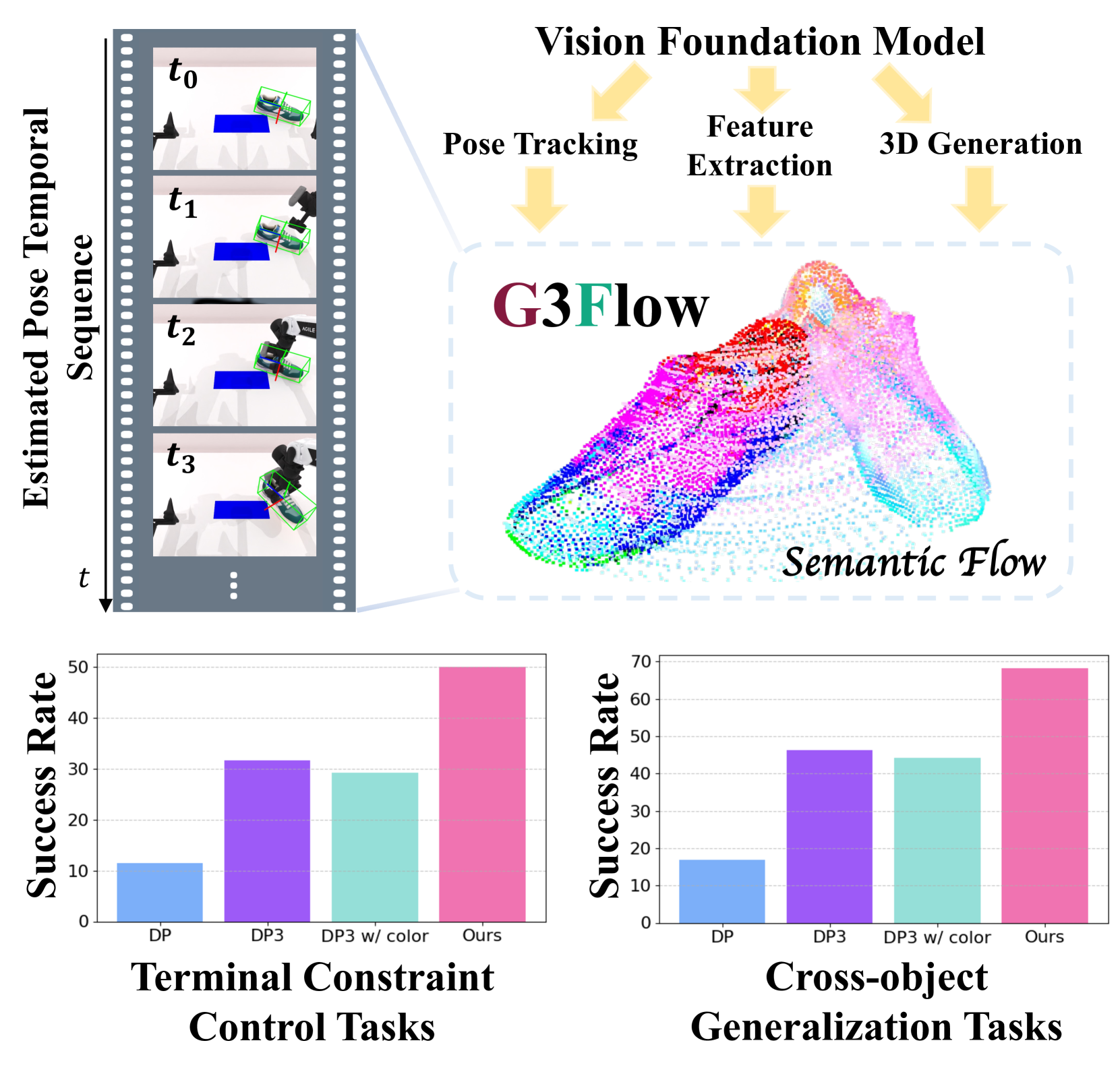
- G3Flow的核心在于构建实时语义流,它是一种动态的、以物体为中心的3D语义表示,融合了3D生成模型、视觉基础模型和姿态跟踪。
- 实验结果表明,G3Flow在终端约束操作和跨对象泛化任务上均优于现有方法,成功率分别提升至68.3%和50.1%。
📝 摘要(中文)
本文提出G3Flow,一个新颖的框架,通过利用基础模型构建实时语义流,这是一种动态的、以物体为中心的3D语义表示。该方法独特地结合了用于数字孪生创建的3D生成模型、用于语义特征提取的视觉基础模型以及用于连续语义流更新的鲁棒姿态跟踪。这种集成即使在遮挡下也能实现完整的语义理解,同时消除了手动标注的需求。通过将语义流整合到扩散策略中,我们在终端约束操作和跨对象泛化方面都展示了显著的改进。在五个模拟任务中的大量实验表明,G3Flow始终优于现有方法,在终端约束操作和跨对象泛化任务上分别实现了高达68.3%和50.1%的平均成功率。实验结果证明了G3Flow在增强机器人操作策略的实时动态语义特征理解方面的有效性。
🔬 方法详解
问题定义:现有的基于模仿学习的3D机器人操作方法,尤其依赖扩散模型的策略,在几何精度和语义理解的结合上存在不足。这导致机器人难以像人类一样灵活地进行操作,尤其是在存在遮挡或需要跨对象泛化时。手动标注语义信息成本高昂,限制了方法的应用范围。
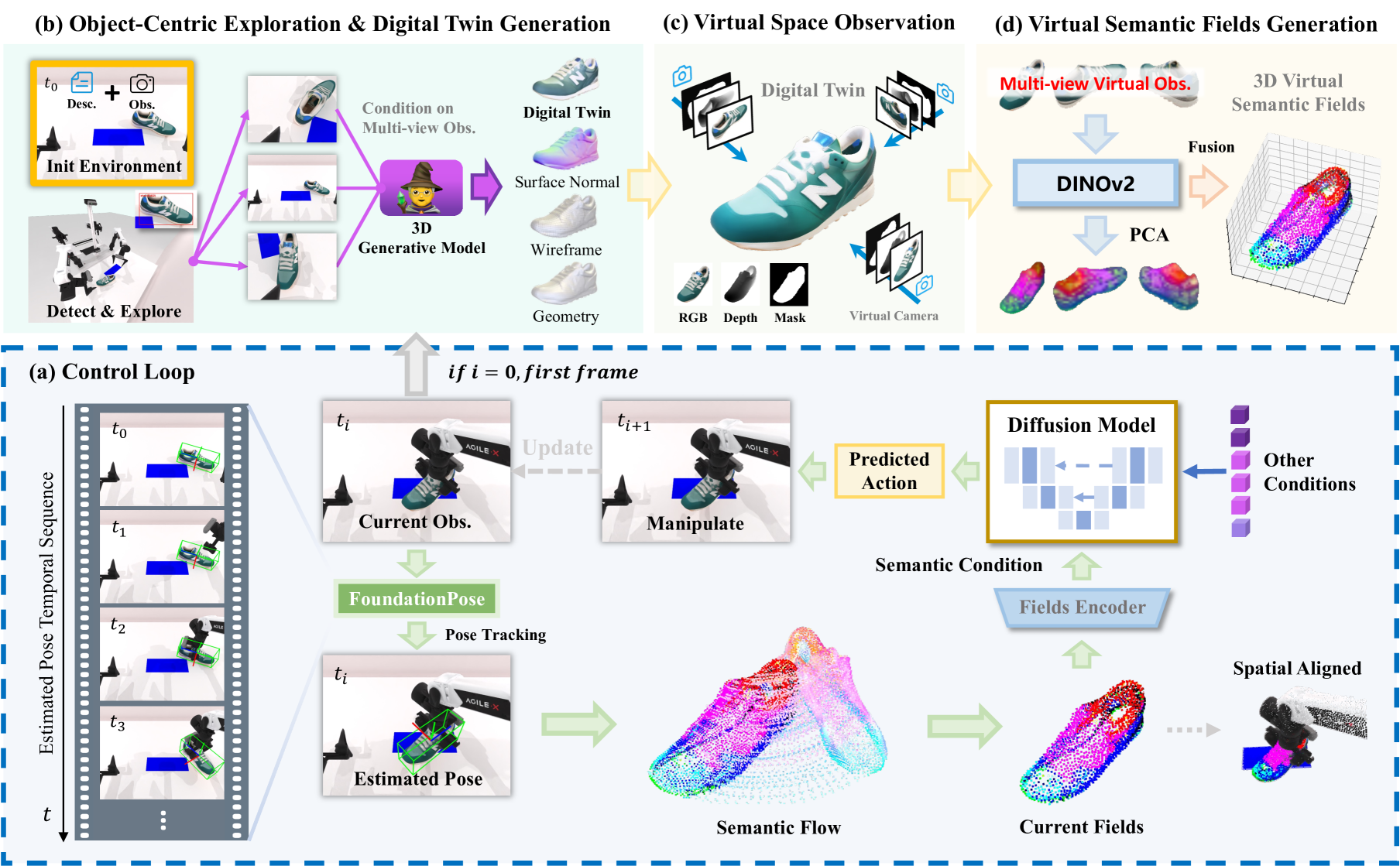
核心思路:G3Flow的核心思路是构建一个动态的、以物体为中心的3D语义表示,即语义流。通过实时更新这个语义流,机器人可以更好地理解场景,从而实现更精确和泛化的操作。这种方法避免了手动标注,并利用了现有的3D生成模型和视觉基础模型。
技术框架:G3Flow框架包含三个主要模块:1) 3D生成模型,用于创建物体的数字孪生;2) 视觉基础模型,用于提取场景的语义特征;3) 姿态跟踪模块,用于实时更新语义流。整体流程是:首先利用3D生成模型创建场景中物体的3D模型,然后使用视觉基础模型提取图像中的语义特征,最后通过姿态跟踪模块将语义特征映射到3D模型上,并实时更新语义流。这个语义流被用作扩散策略的输入,指导机器人的操作。
关键创新:G3Flow的关键创新在于将3D生成模型、视觉基础模型和姿态跟踪模块集成到一个统一的框架中,从而构建了实时语义流。这种语义流不仅包含了物体的几何信息,还包含了语义信息,并且能够实时更新,从而使机器人能够更好地理解场景。与现有方法相比,G3Flow不需要手动标注语义信息,并且能够更好地处理遮挡和跨对象泛化问题。
关键设计:G3Flow使用预训练的3D生成模型(例如,ShapeNet)来创建物体的3D模型。视觉基础模型可以是任何能够提取语义特征的模型(例如,CLIP)。姿态跟踪模块使用卡尔曼滤波器来平滑姿态估计。扩散策略使用标准的扩散模型结构,并以语义流作为输入。损失函数包括重构损失和操作成功率损失。
🖼️ 关键图片

📊 实验亮点
G3Flow在五个模拟任务中进行了广泛的实验,结果表明其性能始终优于现有方法。在终端约束操作任务上,G3Flow的平均成功率达到了68.3%,相比于最佳基线提高了显著的百分比(具体数值未知,但摘要表明是显著提升)。在跨对象泛化任务上,G3Flow的平均成功率达到了50.1%,同样优于现有方法。这些结果证明了G3Flow在增强机器人操作策略的实时动态语义特征理解方面的有效性。
🎯 应用场景
G3Flow具有广泛的应用前景,例如智能制造、家庭服务机器人、医疗机器人等。在智能制造领域,G3Flow可以用于实现自动化装配和质量检测。在家庭服务机器人领域,G3Flow可以用于实现物体识别和操作。在医疗机器人领域,G3Flow可以用于辅助手术和康复训练。该研究的实际价值在于提高了机器人操作的精度和泛化能力,降低了手动标注的成本。未来,G3Flow可以进一步扩展到更复杂的场景和任务中。
📄 摘要(原文)
Recent advances in imitation learning for 3D robotic manipulation have shown promising results with diffusion-based policies. However, achieving human-level dexterity requires seamless integration of geometric precision and semantic understanding. We present G3Flow, a novel framework that constructs real-time semantic flow, a dynamic, object-centric 3D semantic representation by leveraging foundation models. Our approach uniquely combines 3D generative models for digital twin creation, vision foundation models for semantic feature extraction, and robust pose tracking for continuous semantic flow updates. This integration enables complete semantic understanding even under occlusions while eliminating manual annotation requirements. By incorporating semantic flow into diffusion policies, we demonstrate significant improvements in both terminal-constrained manipulation and cross-object generalization. Extensive experiments across five simulation tasks show that G3Flow consistently outperforms existing approaches, achieving up to 68.3% and 50.1% average success rates on terminal-constrained manipulation and cross-object generalization tasks respectively. Our results demonstrate the effectiveness of G3Flow in enhancing real-time dynamic semantic feature understanding for robotic manipulation policies.